导语:
本文作者为解决一个JDK性能问题,从堆栈分析,到GC分析,再到Safepoint原因分析,最终定位到问题根因与所用的JDK版本有关。并整理成文,与所有Java相关开发的同学分享此次经验。
笔者近期在工作中遇到这样一个问题:某客户新上线了一个Elasticsearch应用,但运行一段时间后就变的特别慢,甚至查询超时。重启后服务恢复,但每隔3~4小时后问题重现。
针对这个问题,我身边的同事也帮忙做了简单分析,发现存在大量Merge的线程,应该怎么办呢?
根据我之前定位问题的经验,一般通过Thread Dump日志分析,就能找到问题原因的正确方向,然后再分析该问题不断重复的原因。
按
照
这个思路,问题分析起来应该不算复杂。
But,后来剧情还是出现了波折。
因网络隔离原因,只能由客户配合获取Thread Dump日志。并
跟客户强调了获取Thread Dump日志的技巧,每个节点每隔几秒获取一次,输出到一个独立的文件中。集群涉及到三个节点,我们暂且将这三个节点称之为39,158, 211。问题复现后,拿到了第一批Thread Dump文件:
从文件的大小,可轻易看出39节点大概率是一个问题节点,它的Thread Dump日志明显大出许多:查询变慢或者卡死,通常表现为大量的Worker Thread忙碌,也就是说,活跃线程数量显著增多。而在ES(Elasticsearch,以下简称为ES)的默认查询行为下,只要有一个节点出现问题,就会让整个查询受牵累。
那么我们先对三个节点任选的1个Thread Dump文件的线程总体情况进行对比:
|
节点名称
|
3
9
|
1
58
|
2
11
|
|
线程总数
|
366
|
341
|
282
|
|
RUNNABLE
|
264
|
221
|
162
|
|
W
AITING
|
64
|
88
|
92
|
|
T
IME_WAITING
|
28
|
32
|
28
|
|
B
LOCKED
|
10
|
0
|
0
|
再按线程池进行分类统计:
|
节点名称
|
3
9
|
1
58
|
2
11
|
|
Luc
ene Merge Thread
|
77
|
0
|
0
|
|
h
ttp_server_worker
|
64
|
64
|
64
|
|
s
earch
|
49
|
49
|
49
|
|
t
ransport_client_boss
|
28
|
64
|
30
|
|
b
ulk
|
32
|
32
|
32
|
|
g
eneric
|
15
|
6
|
4
|
|
t
ransport_server_worker
|
27
|
55
|
29
|
|
r
efresh
|
10
|
5
|
10
|
|
m
anagement
|
5
|
2
|
3
|
|
w
armer
|
5
|
5
|
5
|
|
f
lush
|
5
|
5
|
5
|
|
o
thers
|
49
|
54
|
51
|
可以发现:
39节点上的Lucene Merge Thread明显偏多,而其它两个节点没有任何Merge的线程
。
再对39节点的Thread Dump文件进行深入分析,发现的异常点总结如下:
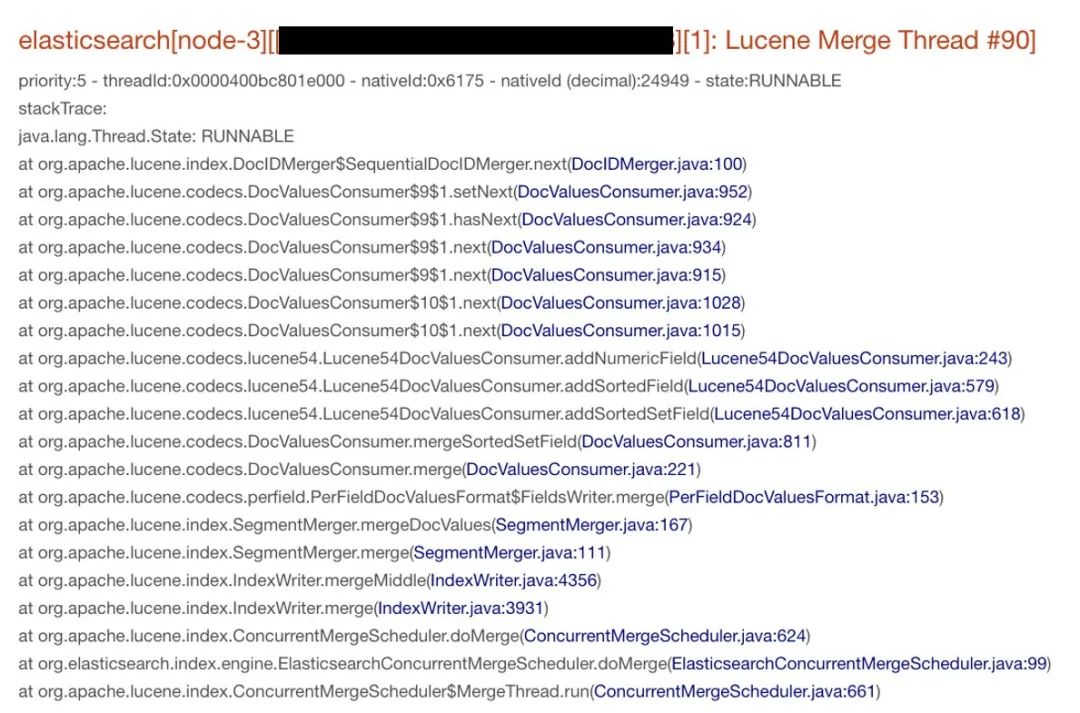
1. Lucene Merge Thread达到77个,其中一个线程的调用栈如下所示:
2. 有8个线程在竞争锁定ExpiringCache:

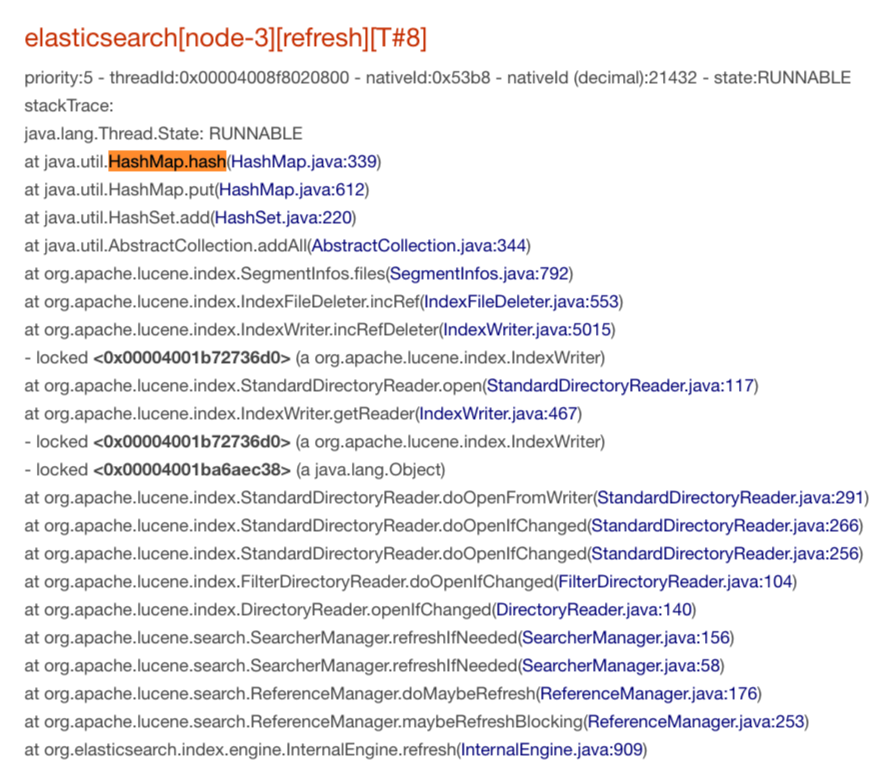
3. 有8个线程都在做HashMap#hash计算:
现象1中提到了有77个同时在做Merge的线程,但无法确定这些Merge任务是同时被触发的,还是因为系统处理过慢逐步堆积成这样的状态。
无论如何这像是一条重要线索
。再考虑到这是一个新上线的应用,关于环境信息与使用姿势的调研同样重要:
我开始怀疑这种特殊的使用方式:
集群中存在多个写活跃的索引,但每分钟的写入量都偏小,在KB至数MB级别。
这意味着,Flush可能都是周期性触发,而不是超过预设阈值后触发。
这种写入方式,会导致产生大量的小文件。
抽样观察了几个索引中新产生的Segment文件,的确每一次生成的文件都非常小。
关于第2点现象,我认真阅读了java.io.UnixFileSystem的源码:
多个线程都在争相调用ExpiringCache#put操作,这侧面反映了文件列表的高频变化,这说明系统中存在高频的Flush和Merge操作。
这加剧了我关于使用姿势的怀疑:"细雨绵绵"式的写入,被动触发Flush,如果周期相同,意味着同时Flush,多个Shard同时Merge的概率变大。
于是,我开始在测试环境中模拟这种使用方式,创建类似的分片数量,控制写入频率。计划让测试程序至少运行一天的时间,观察是否可以复现此问题。在程序运行的同时,我继续调查Thread Dump日志。
第3点现象中,仅仅是做一次hash计算,却表现出特别慢的样子。如果将这三点现象综合起来,可以发现所有的调用点都在做CPU计算。按理说,CPU应该特别的忙碌。
等问题在现场复现的时候,客户协助获取了CPU使用率与负载信息,结果显示CPU资源非常闲。在这之前,同事也调研过IO资源,也是非常闲的。这排除了系统资源方面的影响。此时也发现,
每一次复现的节点是随机的,与机器无关
。
一天过去后,在本地测试环境中,问题没能复现出来。尽管使用姿势不优雅,但却不像是问题的症结所在。
通过jstack命令获取Thread Dump日志时,需要让JVM进程进入Safepoint,相当于整个进程先被挂起。获取到的Thread Dump日志,也恰恰是进程挂起时每个线程的瞬间状态。
所有忙碌的线程都刚好在做CPU计算,但CPU并不忙碌。
这提示需要进一步调查GC日志
。
现场应用并未开启GC日志。考虑到问题当前尚未复现,通过jstat工具来查看
G
C
次数与
G
C
统计时间的意义不太大。让现场人员在jvm.options中手动添加了如下参数来开启GC日志:
8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8
:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=32m
添加
PrintGCApplicationStoppedTime
是为了将每一次JVM进程发生的STW(Stop-The-World)中断记录在
GC
日志
中。通常,此类STW中断都是因GC引起,也可能与偏向锁有关。
刚刚重启,现场人员把
G
C
日志tail的结果发了过来,这是为了确认配置已生效。诡异的是,刚刚重启的进程居然在不停的打印STW日志:

关于STW日志(”…Total time for which application threads were stopped…”),这里有必要简单解释一下:
JVM有时需要执行一些全局操作,典型如GC、偏向锁回收,此时需要暂停所有正在运行的Thread,这需要依赖于JVM的Safepoint机制,Safepoint就好比一条大马路上设置的红灯。
JVM每一次进入STW(Stop-The-World)阶段,都会打印这样的一行日志:
2020-09-10T13:59:43.210+0800: 73032.559: Total time for which application threads were stopped: 0.0002853 seconds, Stopping threads took: 0.0000217 seconds
在这行日志中,提示了STW阶段持续的时间为0.0002853秒,而叫停所有的线程(Stopping threads)花费了0.0000217秒,前者包含了后者。通常,Stopping threads的时间占比极小,如果过长的话可能与代码实现细节有关,这里不过多展开。
回到问题,一开始就打印大量的STW日志,容易想到与偏向锁回收有关。直到问题再次复现时,拿到了3个节点的完整的GC日志,发现无论是YGC还是FGC,触发的频次都很低,这排除了GC方面的影响。
出现的大量STW日志
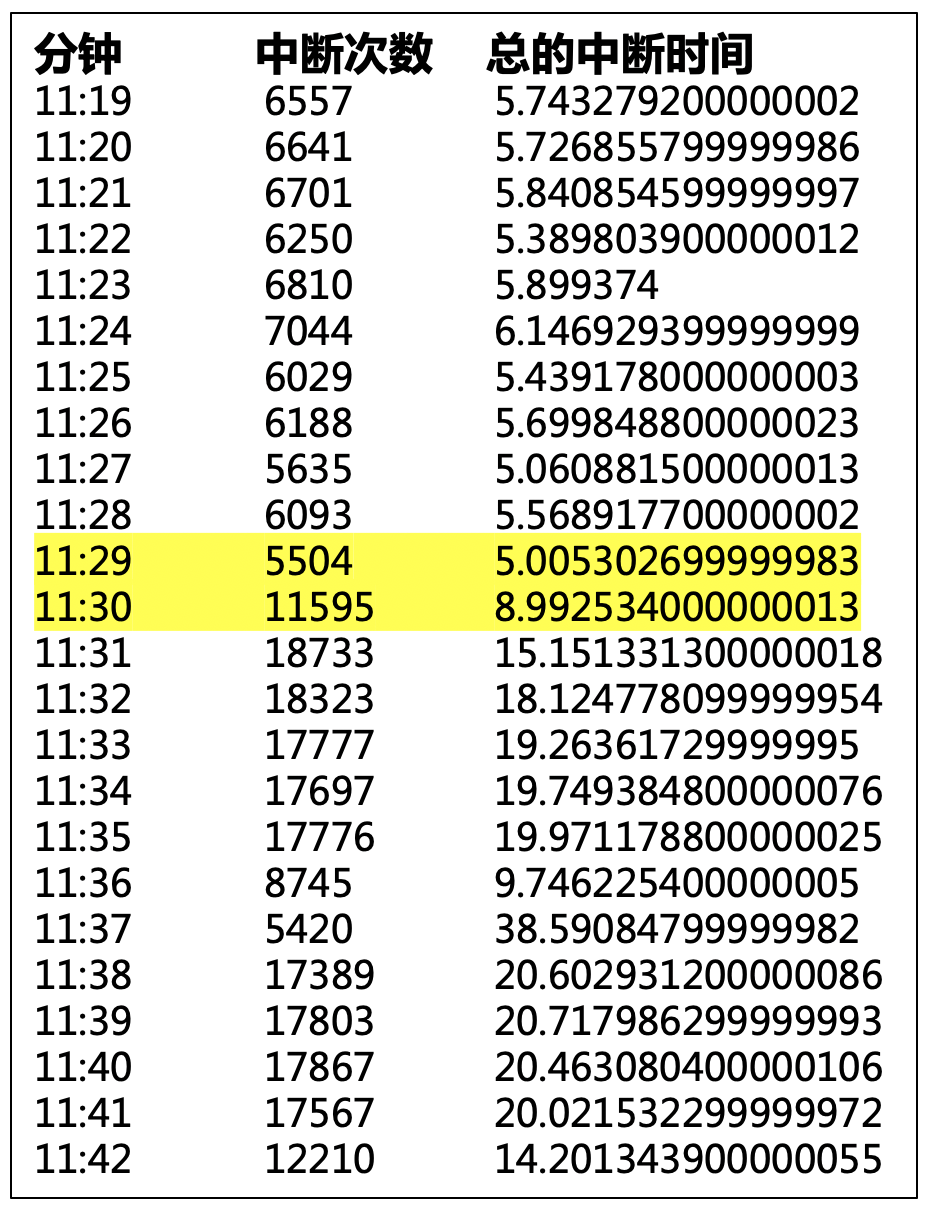
,使我意识到该现象极不合理。有同学提出怀疑,每一次中断时间很短啊?写了一个简单的工具,对每一分钟的STW中断频次、中断总时间做了统计:
-
-
在11:29~11:30之间,中断频次陡增,这恰恰是问题现象开始出现的时间段。
每分钟的中断总时间甚至高达20~30秒。
这就好比,一段1公里的马路上,正常是遇不见任何红绿灯的,现在突然增加了几十个红绿灯,实在是让人崩溃。
这些中断很好的解释了“所有的线程都在做CPU计算,然而CPU资源很闲”的现象
。
Safepoint有多种类型,为了确认Safepoint的具体类型,继续让现场同学协助,在jvm.options中添加如下参数,打开JVM日志:
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount=10







