点击上方
“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
最近看到一篇文章介绍一个很有意思的问题,『为什么没有做batch attention的?』,在此给大家分享一下,希望对大家有一定的帮助。
转载自丨NewBeeNLP

当前的深度神经网络尽管已经取得了巨大的成功,但仍然面临着来自于数据稀缺的各种挑战,比如数据不平衡,零样本分布,域适应等等。当前已经有各种方法通过样本之间的关系去针对这些问题。然而这些方法并没有去挖掘内在的网络结构来使网络模型建模关系。受这些启发,我们提出了一个使网络能够从训练批次(min-batch)中学习样本关系的
简单有效并且即插即用
Transformer 模块,Batch TransFormer(BatchFormer)。
具体地,
BatchFormer 应用于每个训练批次数据的batch维度来隐式地探索样本关系。
BatchFormer 使每个批量的样本间能够互相促进学习,比方说,在长尾识别中,利用频繁类别数据促进稀有类别的样本的学习。更进一步地,由于在训练的时候在 batch 维度引用了 Transformer,训练和测试的数据分布不再一致了。
因此我们提出一种共享分类器的策略,来消除在训练和测试的分布偏差从而达到 Batch 不变学习,进而使我们在测试的时候能够移除 BatchFormer。这种共享策略使 BatchFormer 在测试时不增加任何计算负载。不需要任何额外的策略,
BatchFormer 在 10 多个数据集上面展示了稳定的提升,包括了长尾分布,组合零样本学习,领域泛化,领域适应,对比学习
。
最后但是更重要的,基于 DETR,我们进一步将 BatchFormer 扩展到像素级别的任务上面,包括目标检测,全景分割,图像分类。
改进版的 BatchFormer 能够即插即用于 DETR, Deformable DETR, Conditional DETR, SMCA, DeiT。

论文标题:
BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
CVPR 2022
https://arxiv.org/pdf/2203.01522.pdf (CVPR 2022)
https://arxiv.org/pdf/2204.01254.pdf (V2)
https://github.com/zhihou7/BatchFormer

介绍
尽管深度学习已经取得了巨大的成功,但是它严重依赖于大量的数据。对大量训练数据的依赖限制了深度模型的实际应用。因此,怎么改善深度模型在数据稀缺的场景下的泛化能力受到了广泛的关注,比如长尾学习,少样本学习,零样本学习,领域泛化。尽管这样,当前仍然缺乏一种简单,统一的探索样本关系的框架来针对各种样本稀缺的问题。一个直观的例子可以见图 1,我们可以利用不同样本的相似性和共享的 part 来改善网络的泛化。
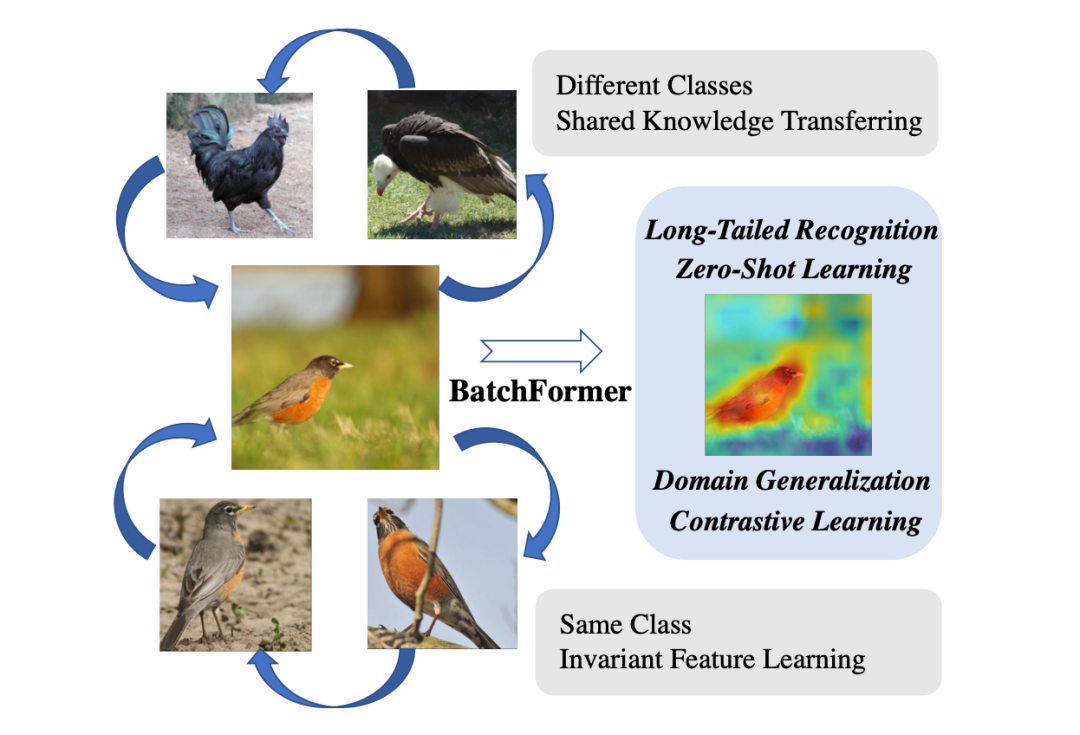
▲ 图1:样本关系的示例.鸟和鸡具有形状上的相似性。并且他们共享着两条腿的特性。
尽管没有单独地阐述样本关系,最近的工作已经内在地探索了样本关系通过约束或者知识迁移。一些常见的例子是 mixup
[3]
,copy-paste
[4]
,crossgrad
[5]
和组合学习
[6]
。这些方法内在地利用样本间存在相似关系和共享部分的关系来增强数据约束模型。
另外一种方式是知识迁移,比如说 1)在频繁类别和稀有类别之间
[7]
,2)从已见类别到未见
[8]
,3)已知域和未知域
[9]
. 然而这些方法是从网络的输入或者输出来探索关系,没有设计网络内部结构来学习到样本关系,更没有在 batch 维度进行数据的协同学习。在这篇文章,我们介绍一种网络模块作用到 Batch 维度上去探索样本关系。
然而,训练和测试的不一致(测试的时候,不会总有一个样本)使网络并不容易在 batch 维度学习到样本关系。因为我们在测试的时候,经常会遇到没有 batch 的数据。一个经典的例子是 Batch Normalization。Batch Normalization 总是保留着 mini-batch 统计出的均值和方差,来归一化测试样本。
另外一种方式是使用特征的 memory bank 来保留类别的中心,这样来帮助判别稀有和零样本类别. 不同于以上的方式,我们介绍一种全新的简单有效的模块来通过利用结构的优势探索样本关系对于表示学习的帮助。
具体地,我们尝试在 batch 维度上面引入 Transformer 结构来建模样本关系。在这里,我们主要启发与图结构,没有 positional embedding 时,Transformer 也可以看做是一个全连接图网络。我们把这种模块称为 Batch Transformer 或者 BatchFormer。在实现中,我们在分类器和特征提取器之间插入 BatchFormer。
此外,为了减少测试和训练的偏移,不同于 Batch Normalization 和 Memory Feature Bank, 我们介绍了一种新的策略,共享分类器:我们在 BatchFormer 前后引入共享的分类器。相较于统计的均值方差和 Feature back,共享策略能够让我们在测试的时候不增加任何计算和内存的负载。
尽管加入共享分类器可以使得网络能够有效地改善数据稀缺的分类问题。然而,对于pixel级别的任务来说,这并不非常适用。因此我们进一步将 BatchFormer 泛化到一般化的任务,像目标检测和分割。我们将 BatchFormer 应用到一般的 Transformer 结构中,比如 DETR 和 DeiT,插入到两层空间 Transformer 的中间,同时改进共享分类器为双流结构来保证训练和测试的 batch 不变性。我们把这个方法称为 BatchFormerV2。
一个简单的比较 Channel Attention [10],Visual Transformer
[11]
和 BatchFormer 可以如图 2 所示。我们将 Attention 结构从通道和空间维度泛化到 batch 维度,展示了一种新的模型结构的可能。
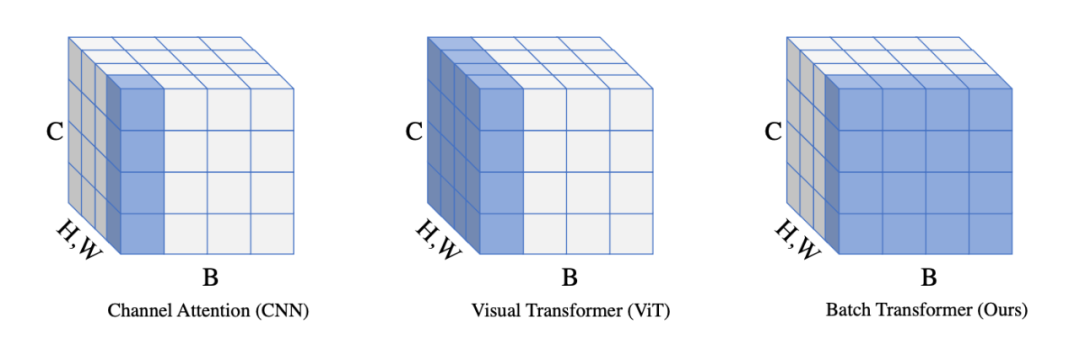
▲ 图2: Channel Attention在通道做attention,Visual Transformer在空间维度上面做attention,而我们的BatchFormer在Batch维度上面做attention。
简而言之,我们介绍了一种简单有效的针对数据稀缺的 Transformer 模块,取名为 BatchFormer。我们在超过 10 个数据稀缺数据,5 个任务上面展示了方法的有效性。更进一步,我们提出一个 BatchFormerV2 版本,将 BatchFormer 泛化到一般的目标检测和分割任务上面,即插即用地显著改善了 DETR,Deformable-DETR,Conditional DETR,SMCA 的效果。

方法
2.1 BatchFormer
BatchFormer 是一个即插即用的模块,通过探索样本关系对促进表示学习。如图 3 所示,我们在特征提取器后面插入 TransFormer 模块。特别地,我们的 Transformer 是沿着 batch dimension, 也就是说我们把整个 batch 看做一个 sequence。在这里,我们移除了 Transformer 的 positional embedding 以达到位置的不变性学习。
与此同时,我们在 Transformer 前后都加入了一个分类器,注意,这两个分类器是共享的,通过这个共享分类器,使得我们能够保持训练和测试的 batch 不变性。

▲ 图3:模块示意图,我们在分类器前一层插入一个Transformer Encoder模块。该模块作用于Batch维度,而不是空间维度。同时在Transformer前后共享分类器。
BatchFormer 可以通过简单的
几行代码实现
,如下图所示:

2.2 BatchFormerV2
我们将 BatchFormer 泛化为一个更通用的模块,来促进一般的计算机视觉任务,比如目标检测和分割,图像分类。具体的,我们将 BatchFormer 插入到两层 Visual Transformer 之间,在每个空间的像素点上面进行 Batch Transformer 操作.同时我们将每个空间位置上面的 BatchFormer 共享,如下图所示。
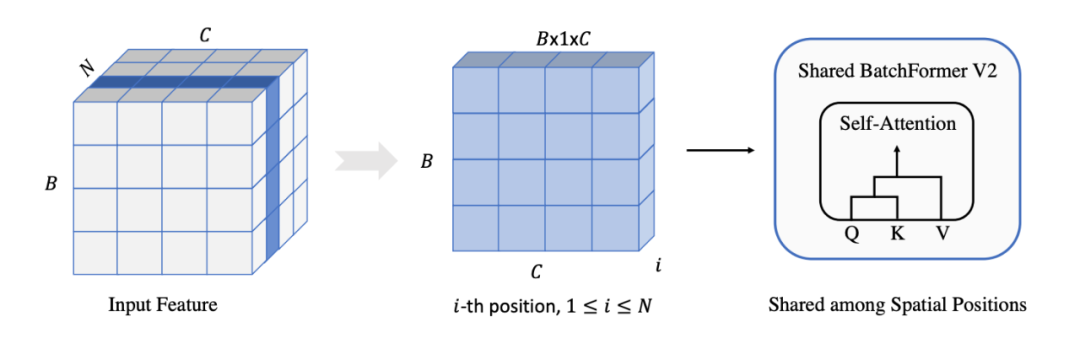
▲ 图4:BatchFormerV2空间维度共享图
同时,我们介绍了一种新的双分支模式,从 BatchFormer 前开始,将每个 Batch 复制一份,让一份 batch 的数据传入原有的网络模块中,让另外一份 batch 的数据经过 BatchFormer 分支。除了 BatchFormerV2 模块外,其他所有模块参数,我们在两个分支中全部共享。这里的目的同共享分类器一致:让模型学到一个batch 不变的特征。模型框架如下:
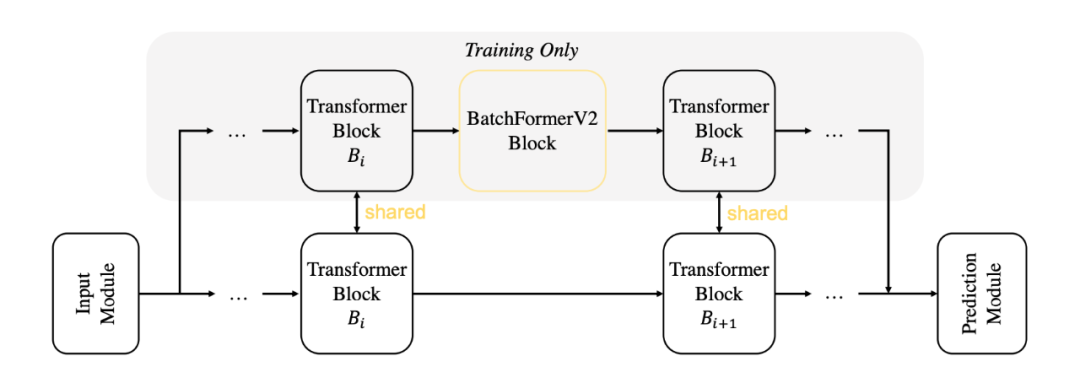
▲ 图5: BatchFormerV2双分支框架图。BatchFormerV2分支加入了BatchFormer模块,而原有的分支保持不变。两个分支输入的数据是一样的。
BatchFormerV2 也可以通过简单的几行代码实现如下:

2.3 梯度分析
从模型的优化上,BatchFormer 结构改变了梯度传播的方向,使得任意一个样本的特征会贡献到所有其他样本的 loss 计算上面。因此任意一个 loss 算出来的梯度,都会回传到基于其他所有样本计算的梯度上面。从样本的增强角度上面看,BatchFormer 可以看成是隐式地增加了数据。每一个样本特征可以看成是其他样本的虚拟特征
[3]
。这样 BatchFormer 实际上大大增强了样本,所以能够有效地改善数据稀缺的问题。

实验结果
这里我们主要展示了我们核心的实验结果,比如目标检测,全景分割,长尾识别,对比学习,域泛化,等等。更多任务的实验和消除分析请参见我们的论文和附录。
3.1 目标检测
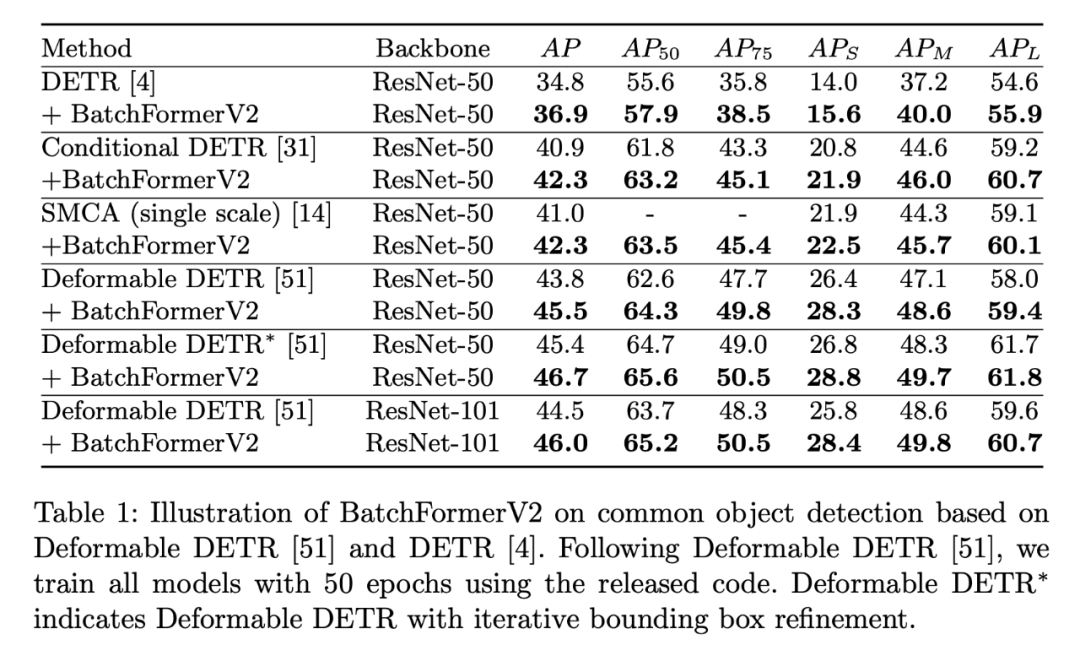
我们发现,BatchFormer 能够即插即用到 DETR 以及 DETR 派生出来的各种方法上面。并且取得了超过一个点的一致性的提升。
3.2 全景分割

我们在全景分割上面,提高了 DETR 1.7%
。
我们注意到 BatchFormerV2 主要提升了 stuff 的类别。我们的可视化实验也发现,BatchFormerV2 能够更加注意到 object。
3.
3 长尾分布
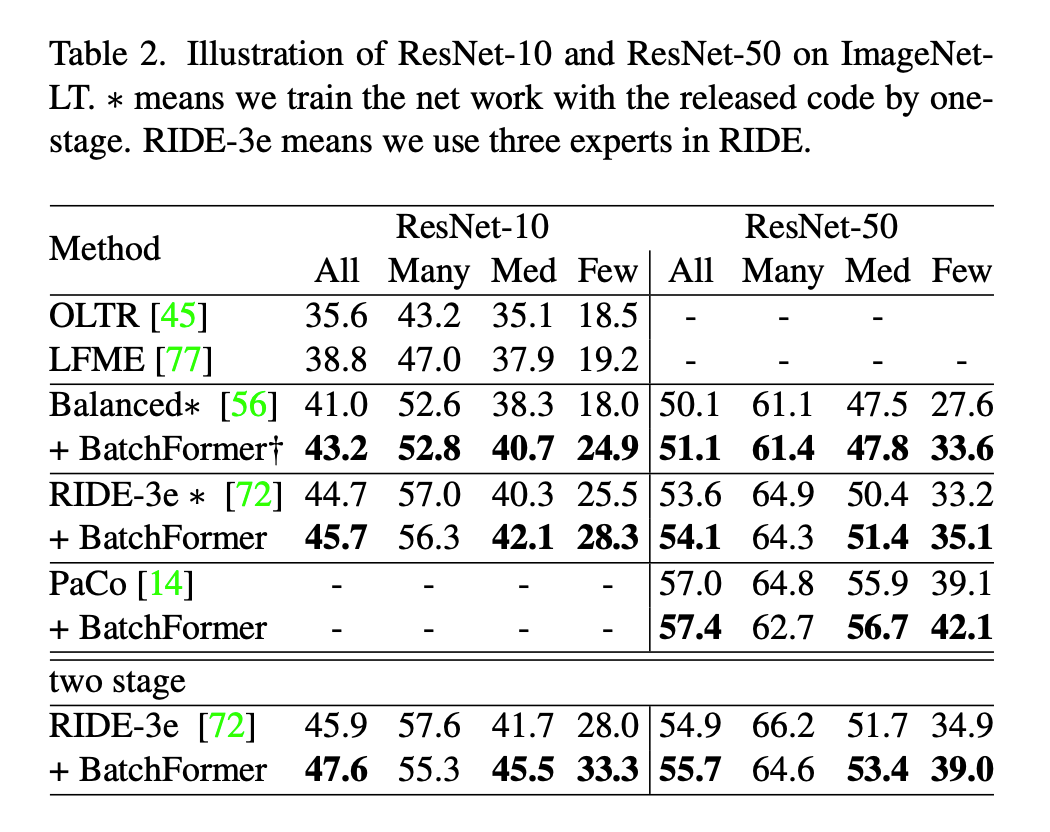
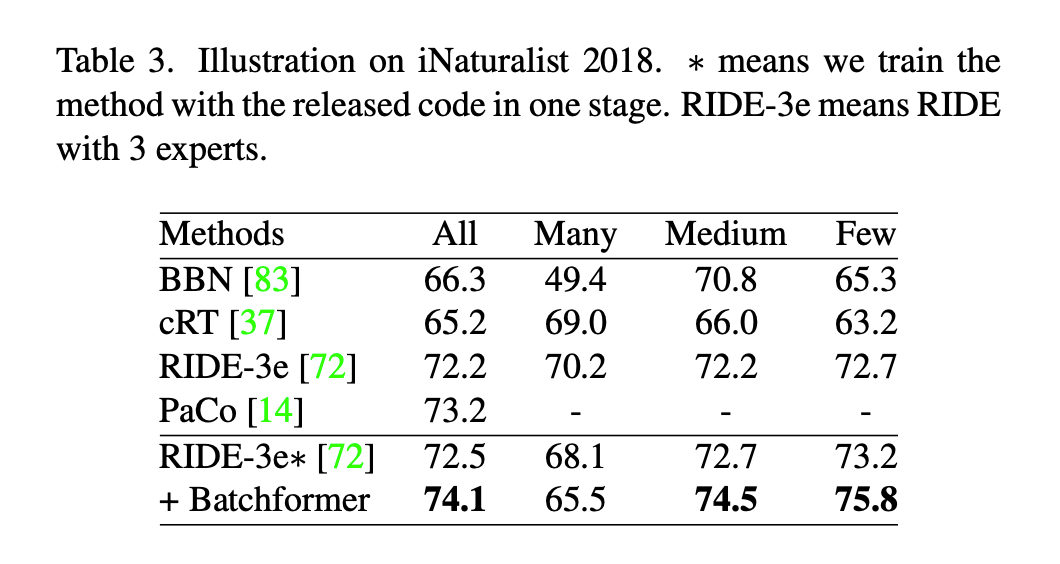
从实验的结果看,BatchFormer 主要提升了 few shot 的类别。在长尾分布中,我们认为 BatchFormer 平衡了数据。
3.4 自监督学习

BatchFormer 一致地改善了 MoCo-V2 和 V3。
3.5 组合零样本学习
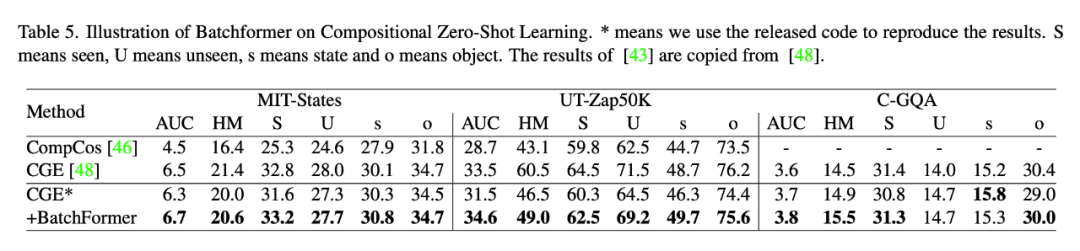
3.6 领域泛化

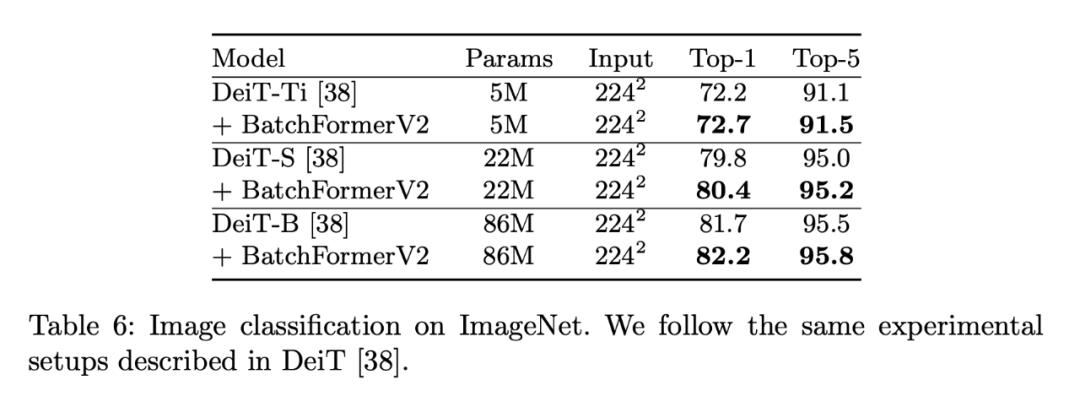
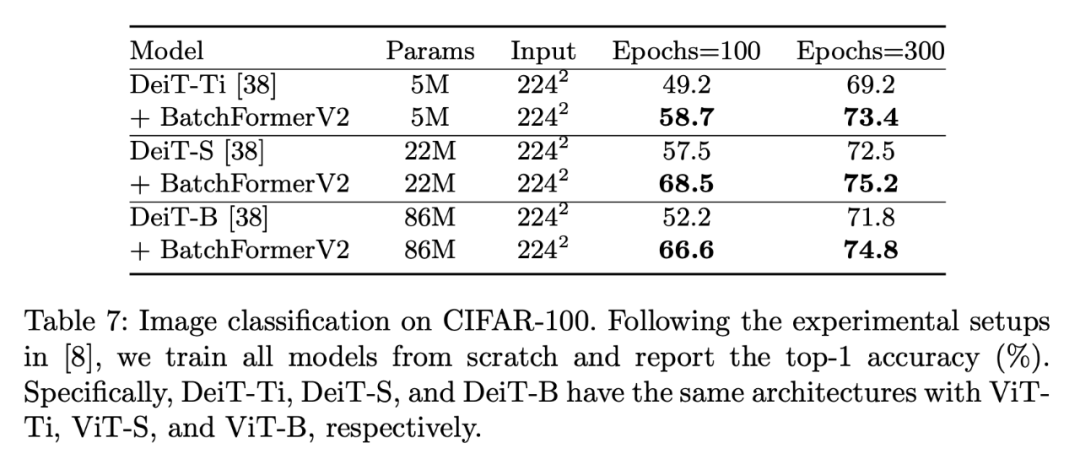
3.7 图像分类
3.8 消除实验
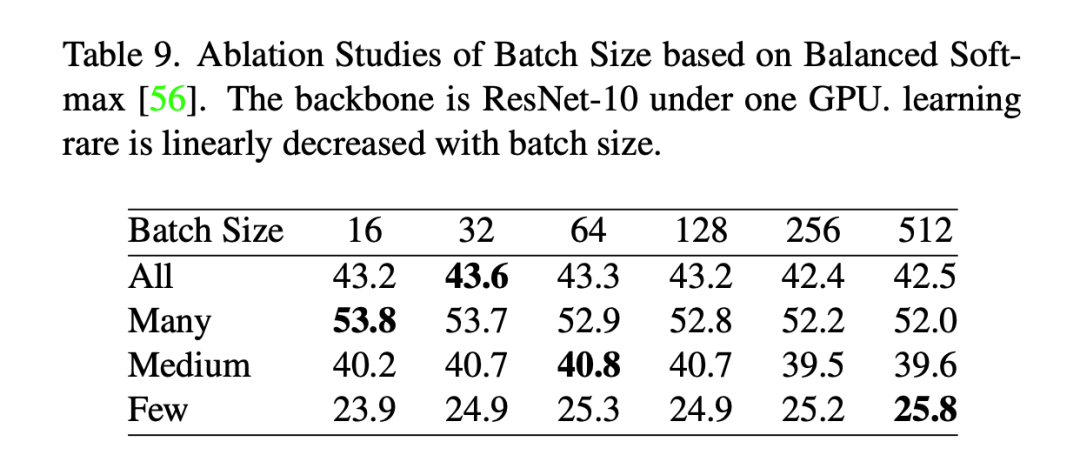
我们基于长尾识别数据集(ImageNet-LT)进行了消除实验。实验中,我们发现batch size 对于模型性能的影响较小。
3.9 梯度分析
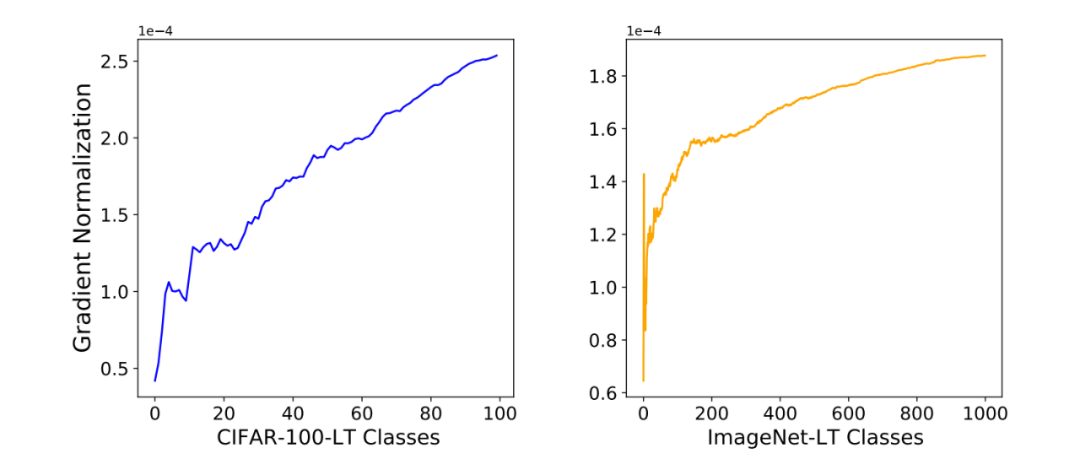
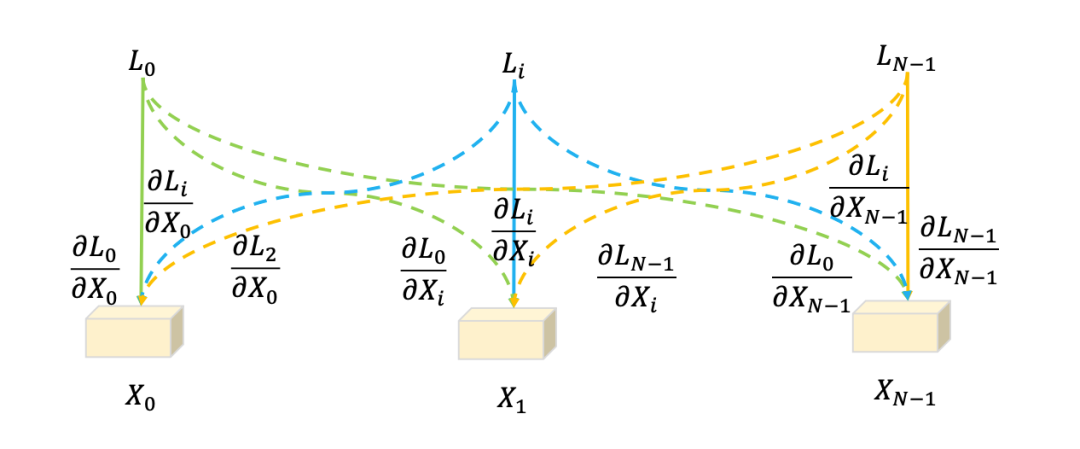
我们按照实例的频数降序提取出每个类别的在训练样本中对其他样本的梯度均值。我们发现稀有类别的对其他样本的梯度明显更大。这个实验说明,BatchFormer 实际上是通过梯度传播改善了模型对于不平衡数据的学习。

可视化分析
4.1 Grad-CAM可视化

我们基于 Grad-CAM 可视化了特征图。第二行是我们的基线,第三行是加上 Transformer 模块后的结果。我们发现在长尾分类的稀有样本中,当场景简单的时候模型会注意到物体的更多细节部分,当场景复杂的时候,模型会学会忽略噪音像素而专注到具体物体中。
4.2 全景分割

第二行是我们的基线(DETR),第三行是 DETR 加上我们提出的方法的结果。我们注意到 BatchFormerV2 会显著地改善物体分割的细节。比如上图中桌子脚,飞机的轮子和浴缸边缘。最后一个图片里面展示 BatchFormerV2 能够分割出细小的目,比如草地。

总结与展望









