近日,百度硅谷 AI 实验室刘海容、李先刚等人发表论文提出了一种新的语音识别模型 Gram-CTC,将语音识别的速度和准确率大大提高。据研究人员介绍,这一新方法可以显著减少模型训练与推理时间。在相同任务中,新模型的表现在单一模型对比中超过了微软等公司的研究。点击阅读原文下载此论文。
在百度的研究发表之前,微软曾在 2016 年 10 月宣布他们的多系统方法在 2000 小时的口语数据库 switchboard 上测得 5.9% 的误差率。后者被认为是对多系统方法潜力的探索,而百度的此次提出的单系统方法则更易于实用化。
CTC 端到端学习使用一个算法将输入和输出联系起来,通常采用深层神经网络。这种方式推崇更少的人工特征设计,更少的中间单元。端到端学习的系统包括:基于 CTC 的语音识别,基于注意机制的机器翻译,目前业界的很多产品中都能找到 CTC 的身影。(参考文章:专访|百度语音识别技术负责人李先刚:如何利用Deep CNN大幅提升识别准确率?)
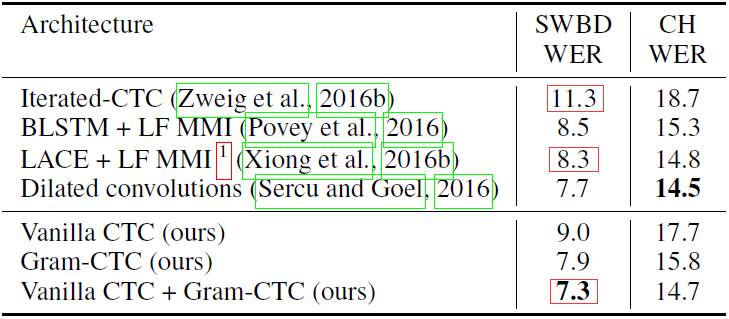
在 Fisher-Switchboard 基准测试上,百度的研究者使用域内数据和此前已发表过的结果进行了比较,表中只列出了单一模型的结果。
在多种语言的语音识别中,Deep Speech 利用 CTC 损失呈现出一种端到端的神经架构。百度展示的 Gram CTC 能够扩展 CTC 损失函数,让它自动发现并预测字段,而不是字符。
使用 Gram CTC 的模型可以用单一模型在 Fisher-Swbd 基准上实现超过以往任何其他模型的表现,这说明使用 Gram-CTC 端到端的学习优于基于上下文和相关音素的系统,使用相同的训练数据也能让训练速度加快两倍。
针对同一段音频,思考下文中可能出现的转录,它们对于语音转录来说都是可行的。
CTC 一次只能预测一个字符,假设输入的对象之间相互独立。为了让两种转录相似,CTC 必须要选择两个字符来补全空白,如下图。

只使用 Option 2 的候选填补空白,我们即可达成第一个目标,即「recognize speech …」;使用 Option 1 中的候选,我们会得到「wreck a nice beach …」。另外,从 Option 1 和 2 中共同选择我们会得到很多种无意义的语句。
字段是介于字符和单词之间的单元,如「ing」,「euax」,「sch」等(包含但不限于词缀),虽然相同的字段可能会因为不同单词或上下文情况出现不同的读音,但字段在英语中通常倾向于同一个发音。在我们的例子中,我们也可以使用字段进行预测:

正如上图所示,这种方法可以大量减少无意义的预测组合,此外,预测词缀还具有以下优点:
论文:Gram-CTC:用于序列标注的自动单元选择和目标分解(Gram-CTC: Automatic Unit Selection and Target Decomposition for Sequence Labelling)

摘要:大多数已有的序列标注模型(sequence labelling model)都依赖一种目标序列到基本单元序列的固定分解。而这些方法都有两个主要的缺点:1)基本单元的集合是固定的,比如语音识别中的单词、字符与音素集合。2)目标序列的分解是固定的。这些缺点通常会导致建模序列时的次优表现。在本论文中,我们拓展了流行的 CTC 损失标准来减缓这些限制,并提出了一种名为 Gram-CTC 的新型损失函数。在保留 CTC 的优势的同时,Gram-CTC 能自动地学习基础单元(gram)的最佳集合,也能自动学习分解目标序列的最合适的方式。不像 CTC,Gram-CTC 使得该模型能在每个时间步骤上输出字符的变量值,使得模型能捕捉到更长期的依存关系(dependency),并提升计算效率。我们证明此次提出的 Gram-CTC 在多种数据规模的大型词汇语音识别任务上,既提升了 CTC 的表现又改进了 CTC 的效率。而且我们使用 Gram-CTC 也在标准的语音基准上得到了超越当前最佳的结果。
原文链接:http://research.baidu.com/gram-ctc-speech-recognition-word-piece-targets/
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]







