「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
论文作者 | 王少楠,张家俊,宗成庆
(中科院自动化所)
特约记者 | 张琨(中国科学技术大学)
学习句子的语义表示就是将句子的含义映射到一个向量空间中,同时保留句子本身的一些特性,例如:表达相似含义的句子在向量空间中应该距离更近。而句子表示模型是将句子的含义编码为计算机可以理解的形式,这是解决大部分自然语言处理问题的先决条件,因此直接影响了许多自然语言处理任务的性能,如在神经机器翻译中需要首先将源语言句子表示为一个向量、在问答系统中需要将问句和答案编码为向量表示等。
但是句子是由不同的词构成的,不同的词包含的信息量不同,对句子的语义表示影响也就不同。如何能区分出这些词汇,给予重要的词更多的注意力,对句子语义的表示有着重要的意义,同时也有助于机器对句子语义的理解。来自中国科学院自动化研究所的王少楠,张家俊和宗成庆老师发表在国际人工智能联合会议(IJCAI)上的文章“Learning Sentence Representation with Guidance of Human Attention”通过对人类阅读和句子理解机制的模仿,找到了一种新的编码句子语义的方法。
在理解句子语义方面,人类无疑是机器最好的老师,那么人类是如何阅读和理解句子的呢?由于组成句子的词所包含的信息量不同,因此人类在阅读和理解句子时会选择性的注意句子中的某些词汇,也会选择性的跳读一些词汇,这种注意力机制(图 1)让人阅读和理解句子变得更加高效。
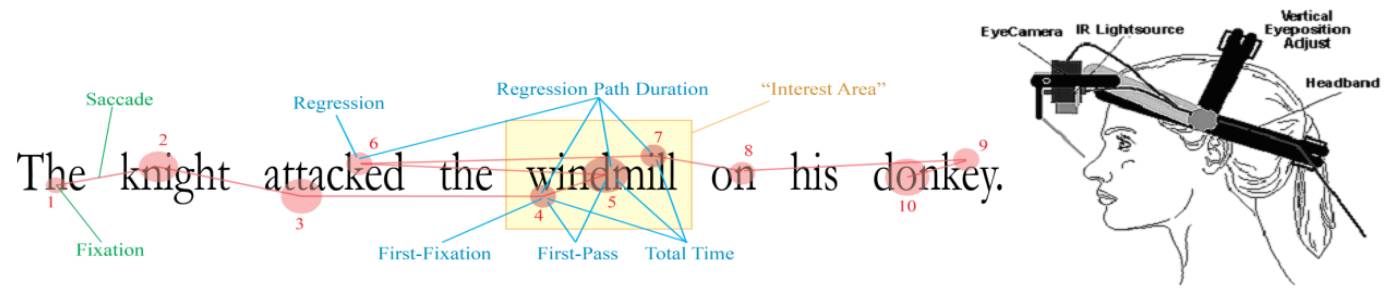
▲ 图1:人类阅读过程中的眼动(注意力)轨迹
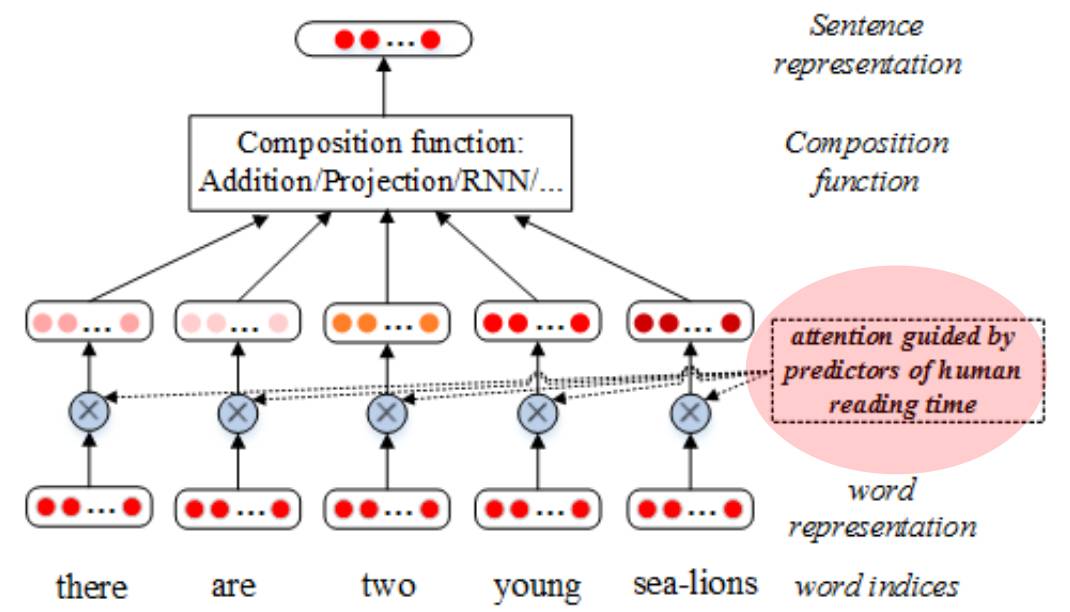
受人类注意力机制的启发,作者认为在构建句子表示时应该给重要的词汇赋予较高的权重,这样可以得到更好的句子语义表示。那么哪些词汇对句子含义的表达更重要呢?同样我们从人类阅读文本时的注意力分布寻找答案,大量的有关人类阅读时间的研究证明了词汇的特性,如词性、词长、词频、词汇惊异度(Surprisal)等,都会影响人类阅读文本时对这个词汇的关注程度。因此,作者选择了词汇惊异度和词汇的词性来对词汇的重要程度进行建模。
对于以上两种特征,作者分别提出了不同的词汇重要性计算方法,针对词汇惊异度特征,作者直接将它的数值作为词汇的重要性分数;针对词汇词性特征,作者通过赋予每个词汇类别一个向量表示,通过类别向量与对应的词汇向量进行点乘,然后归一化,将得到的结果作为这个词的注意力权重,最后将通过注意力机制的词的加权表示送给当前最好的句子表示模型(图 2)中,得到句子的语义表示。