原文来自Nvidia开发者社区:Deep Learning in a Nutshell: Core Concepts
作者:Tim Dettmers, Author at Parallel Forall
翻译:Kaiser
本文旨在提供直观简明的深度学习引导,涵盖深度学习的基本概念,而不涉及很多数学和理论细节。当然如果要做更深入的研究,数学肯定是必不可少的,但是本系列主要还是用图片和类比等方式,帮助初学者快速建立大局观。
核心概念
机器学习(Machine Learning)
在机器学习中,我们(1)读取数据,(2)训练模型,(3)使用模型对新数据做预测。训练可以看作是当模型拿到新数据的时候、逐步学习一个的过程。在每一步,模型做出预测并且得到准确度的反馈。反馈的形式即是某种衡量标准(比如与正确解的距离)下的误差,再被用于修正预测误差。
学习是一个在参数空间里循环往复的过程:当你调整参数改正一次预测,但是模型却可能把原先对的又搞错了。需要很多次的迭代,模型才能具有良好的预测能力,这一“预测-修正”的过程一直持续到模型再无改良空间。
特征工程(Feature Engineering)
特征工程从数据中提取有用的模式,使之更容易被机器学习模型进行分类。比如,把一堆绿色或蓝色的像素区域作为标准,来判断照片上是陆生动物还是水生动物。这一特征对于机器学习模型十分有效,因为其限制了需要考虑的类别数量。
在多数预测任务中,特征工程是取得好结果的必备技能。然而,因为不同的数据集有着不同的特征工程方法,所以很难得出普遍规律,只有一些大概的经验,这使得特征工程更是一门艺术而非科学。一个数据集里极其关键的特征,到了另一个数据集里可能没有卵用(比如下一个数据集里全是植物)。正因为特征工程这么难,才会有科学家去研发自动提取特征的算法。
很多任务已经可以自动化(比如物体识别、语音识别),特征工程还是复杂任务中最有效的技术(比如Kaggle机器学习竞赛中的大多数任务)。
特征学习(Feature Learning)
特征学习算法寻找同类之间的共有模式,并自动提取用以分类或回归。特征学习就是由算法自动完成的特征工程。在深度学习中,卷积层就极其擅长寻找图片中的特征,并映射到下一层,形成非线性特征的层级结构,复杂度逐渐提升(例如:圆圈,边缘 -> 鼻子,眼睛,脸颊)。最后一层使用所有生成的特征来进行分类或回归(卷积网络的最后一层,本质上就是多项式逻辑回归)。
 图1:深度学习算法学得的层级特征。
图1:深度学习算法学得的层级特征。
每个特征都相当于一个滤波器,
用特征(比如鼻子)去过滤输入图片。
如果这个特征找到了,相应的单元就会产生高激励,
在之后的分类阶段中,就是此类别存在的高指标。
图1显示了深度学习算法生成的特征,很难得的是,这些特征意义都很明确,因为大多数特征往往不知所云,特别是循环神经网络、LSTM或特别深的深度卷积网络。
深度学习(Deep Learning)
在层级特征学习中,我们提取出了好几层的非线性特征,并传递给分类器,分类器整合所有特征做出预测。我们有意堆叠这些深层的非线性特征,因为层数少了,学不出复杂特征。数学上可以证明,单层神经网络所能学习的最好特征,就是圆圈和边缘,因为它们包含了单个非线性变换所能承载的最多信息。为了生成信息量更大的特征,我们不能直接操作这些输入,而要对第一批特征(边缘和圆圈)继续进行变换,以得到更复杂的特征。
研究显示,人脑有着相同的工作机理:视锥细胞接受信息的第一层神经,对边缘和圆圈更加敏感,而更深处的大脑皮层则对更加复杂的结构敏感,比如人脸。
层级特征学习诞生在深度学习之前,其结构面临很多严重问题,比如梯度消失——梯度在很深的层级处变得太小,以致于不能提供什么学习信息了。这使得层级结构反而表现不如一些传统机器学习算法(比如支持向量机)。
为解决梯度消失问题,以便我们能够训练几十层的非线性层及特征,很多新的方法和策略应运而生,“深度学习”这个词就来自于此。在2010年代早期,研究发现在GPU的帮助下,激励函数拥有足以训练出深层结构的梯度流,从此深度学习开始了稳步发展。
深度学习并非总是与深度非线性层级特征绑定,有时也与序列数据中的长期非线性时间依赖相关。对于序列数据,多数其他算法只有最后10个时间步的记忆,而LSTM循环神经网络(1997年由Sepp Hochreiter和Jürgen Schmidhuber发明),使网络能够追溯上百个时间步之前的活动以做出正确预测。尽管LSTM曾被雪藏将近10年,但自从2013年与卷积网络结合以来,其应用飞速成长。
基本概念
逻辑回归(Logistic Regression)
回归分析预测统计输入变量之间的关系,以预测输出变量。逻辑回归用输入变量,在有限个输类别变量中产生输出,比如“得癌了” / “没得癌”,或者图片的种类如“鸟” / “车” / “狗” / “猫” / “马”。
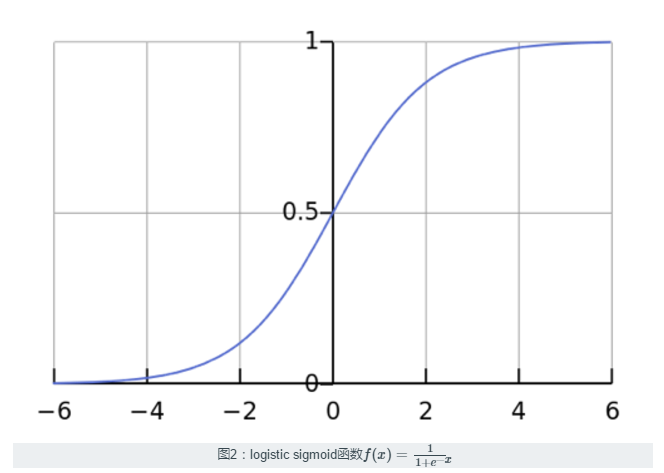
逻辑回归使用logistic sigmoid函数(见图2)给输入值赋予权重,产生二分类的预测(多项式逻辑回归中,则是多分类)。
逻辑回归与非线性感知机或没有隐藏层的神经网络很像。主要区别在于,只要输入变量满足一些统计性质,逻辑回归就很易于解释而且可靠。如果这些统计性质成立,只需很少的输入数据,就能产生很稳的模型。因而逻辑回归在很多数据稀疏的应用中,具有极高价值。比如医药或社会科学,逻辑回归被用来分析和解释实验结果。因为逻辑回归简单、快速,所以对大数据集也很友好。
在深度学习中,用于分类的神经网络中,最后几层一般就是逻辑回归。本系列将深度学习算法看作若干特征学习阶段,然后将特征传递给逻辑回归,对分类进行输入。
人工神经网络(Aritificial Neural Network)
人工神经网络(1)读取输入数据,(2)做计算加权和的变换,(3)对变换结果应用非线性函数,计算出一个中间状态。这三步合起来称为一“层”,变换函数则称为一个“单元”。中间状态——特征——也是另一层的输入。
通过这些步骤的重复,人工神经网络学的了很多层的非线性特征,最后再组合起来得出一个预测。神经网络的学习过程是产生误差信号——网络预测与期望值的差——再用这些误差调整权重(或其他参数)使预测结果更加准确。
Kaiser:以下为几个名词的辨析,包括最近几年的习惯变迁,我认为不需要深究。
单元(Unit)
单元有时指一层中的激励函数,输入正是经由这些非线性激励函数进行变换,比如logistic sigmoid函数。通常一个单元会连接若干输入和多个输出,也有更加复杂的,比如长短期记忆(LSTM)单元就包含多个激励函数,并以特别的布局连接到非线性函数,或最大输出单元。LSTM经过对输入的一系列非线性变换,计算最终的输出。池化,卷积及其他输入变换函数一般不称作单元。
人工神经元(Artificial Neuron)
人工神经元——或神经元——与“单元”是同义词,只不过是为了表现出与神经生物学和人脑的紧密联系。实际上深度学习和大脑没有太大关系,比如现在认为,一个生物神经元更像是一整个多层感知机,而不是单个人工神经元。神经元是在上一次AI寒冬时期被提出来的,目的是将最成功的神经网络与失败弃置的感知机区别开来。不过自从2012年以后深度学习的巨大成功以来,媒体经常拿“神经元”这个词来说事儿,并把深度学习比作人脑的拟态。这其实是具有误导性,对深度学习领域来讲也是危险的。如今业界不推荐使用“神经元”这个词,而改用更准确的“单元”。









