加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都点了这里。
语义理解简单来说,就是让计算机听懂用户说了什么,然后可以进一步回答用户的问题或与用户对话。这类技术在现实场景中的应用有大家比较熟知的微软小冰与百度度秘。锤子手机中 Bigbang 功能也是基于语义理解技术中的语义分析功能进行的创新。本期公开课请到了开放域聊天和 chatbot 顶尖专家——三角兽科技的 CTO 亓超,为大家揭开机器人聊天的秘密。
● ● ●
嘉宾介绍
亓超,自然语言处理方向硕士,AI领域开放域聊天和chatbot顶尖专家,10年科研与工程经验。
曾在佳能、腾讯、阿里负责推荐算法和人机对话系统研发;2014年微软小冰开放域聊天技术创始人;百度T8Lead;度秘聊天技术负责人;从零写了微软小冰和百度度秘唯一两款目前有实际应用的交互系统。

● ● ●
讲课实录整理
雷锋网:可以简单介绍下三角兽吗?
亓超:三角兽科技成立于今年年初,核心技术方向是人工智能交互系统,目标成为智能生活软硬件背后的主流交互系统,团队现接近三十人,以BAT微软乐视等一线AI团队为主。
CEO王卓然,University College London PhD,在英国10年,从事理论机器学、统计机器翻译,自然语言处理、语音聊天系统、统计对话系统、 多模态人与机器人交互、水下无人艇人机交互等多方向研究和实践。在顶级国际会议与期刊上发表多篇论文,曾是百度T8Lead,度 秘App/小度机器人中控策略技术负责人。
COO马宇驰,中国传媒大学新闻媒体管理方向学士,10年市场和品牌经验,连续创业者,曾做过微信微博营销公司,2014年O2O厨师上门公司由 徐小平投资。曾在Viacom集团中国区CBSOut door服务可口可乐、统一、爱国者3年。曾在奥美公关任Intel笔记本处理器公关经 理,主推“酷睿”两个字。曾在Amway China负责企业品牌和广告投放工作。
技术合伙人陈华荣,中国科学院计算机软件与理论专业硕士,在微软工作11年,2013-16年Bing和Office的Exchange部门高级Lead,2005-10年在微软亚 洲研究院研制Exchange12和14,2010-13年,微软西雅图总部研发Exchange15。
技术合伙人王宝勋,哈尔滨工业大学计算机科学博士,微软小冰首席机器学习科学家,发表多篇国际学术论文,学术经验积累深厚。第二到第四代核心高级 研发工程师,负责小冰智能对话引擎、图像智能对话引擎、垂直领域对话引擎等核心技术。
技术合伙人李彦,上海复旦大学计算机科学专业硕士,前乐视推荐算法高级Lead,曾在阿里、人民搜索担任推荐算法方向工程师,后在百度联盟事业部、 360商业产品事业部任高级研发工程师。
战略合伙人何晋,北京科技大学设备工程学士,厨临门战略合作合伙人,灵境VR渠道总监,前百度和美团外卖全国连锁餐饮大客户部项目负责人 。
技术上,在开放领域聊天系统,任务驱动的人机对话系统,搜索及推荐引擎技术等方面有深厚的积累,商业客户,IoT行业标杆客户,如Rokid,锤子,威马汽车,腾讯等,另外为这些客户提供的支持也是不一样的,开放域聊天,锤子领域应用,多轮对话,语义技术都有,证明了我们技术实力和技术到产品落地的能力。
资本融资4月份洪泰和天善1000万天使,8月君联和赛富2000万preA,目前正在A轮的路上,计划春节前close。
锤子新一代手机Big Bang功能的核心算法模块,Rokid机器人聊天系统,威马汽车车载前装的音乐和导航模块,此外,还有一些推进中的项目,其中包括3家巨头公司,4家手机,2家车载后装,和一些机器人公司,以及为消费者提供信息和提供服务的企业客户。
雷锋网:在您看来,目前语义理解技术主要用在哪些场景和应用里?
亓超:语义技术是自然语言处理(NLP)方向很重要的一个部分,三角兽科技优势和积累也主要在NLP方向。
自然语言处理(NLP) 的研发有很久的历史,特别是在互联网发展起来后, 在很多场景里都有应用例如:
搜索引擎中的排序算法及广告推荐系统;
机器翻译, 输入法;
电商, 视频, 及新闻的个性化及推荐系统;
等等。
这些系统的背后都会涉及到NLP问题。
雷锋网:国内语义理解技术的现状是怎样的呢?
亓超:国内NLP及相关的技术目前BAT,360等互联网大企业都有不错的积累。其他互联企业也有非常好的算法团队,例如今日头条等等。
很多产品线,例如百度度搜索,都会有各自的算法团队在支持, 其中NLP的算法支持占了比较大的比例,单从NLP基础技术本身,百度和MSRA的NLP团队无论从规模和深度上都有强大优势,国内的大学里哈工大在这个方向有强大的实力和积累,创业公司在这方面会面临人才稀缺的压力, 比较难形成一个很好的算法团队。
雷锋网:相比做语音识别的公司,提供语义理解的团队看似要少一些,其中的难点是什么?
亓超:两者在各自方向上都有各自的难点。
语音识别和合成相对语义理解来说, 技术上相对成熟。并且很早就作为相对独立的服务进行包装, 较为容易进行产品的落地。例如,地图服务的导航功能 包含了识别与合成两部分。另一方面从事语音技术的公司起步都比较早, 例如科大讯飞, 云知声, 思必驰等, NLP相关技术落地到具体产品也非常依赖于应用场景,相关团队多在大公司里作为某个产品线的算法团队来进行支持 。
虽然越来越受到关注, 但NLP及相关算法人才特别是有经验的从业者仍然非常稀缺, 促使从业者的收入水平较高, 人力成本占了比较大的比例。另外如果是ToC的商业模式, 那么运营成本也会占去较大比例。
雷锋网:理解中的语义理解公司往往需要大量标记好的语料数据,这些数据如何形成?
亓超:
1. 并不是所有NLP问题的解决都要依靠大量标注数据, 问题的解决方案也分统计方法的和规则方法的,这个好比要拧一个螺丝使用普通螺丝刀还是电动螺丝刀,电动螺丝刀需要电,普通的不需要;
2. 数据标注也并不一定是要纯靠人来进行操作, 很多结构化和半结构化的信息可以用来让机器进行学习, 例如电商的打分及评论数据可以用来进行观点分类的学习任务;
3. 未标注的语料很多时候的作用是很大的, 例如目前比较热门的DNN技术, 在很多场景下是使用未标注的数据进行数据及特征的表示学习。
雷锋网:就三角兽而言,我们目前有多少这样的数据?
亓超:数据是我们的核心资源,数据抓取及建设会是我们长期的重点。以我们开放领域聊天系统依赖的数据举例:
百亿级的人人对话数据(未标注生语料);
亿级的面向不同任务的有标签或辅助信息的数据(未标注数据, 但可以进行数据处理后, 针对不同任;务可以用与进行机器学习任务);
千万级的有丰富标签精品数据(采用人机结合的方法进行标注, 形成精品语料);
已有并正在建设的百万级的标注数据(采用人机结合的方法进行标注, 形成精品语料, 每天新增数万条)。
雷锋网:无论小冰还是度秘,都在最初注入了大量关联业务或者公开的数据(据说小冰是微博、度秘是贴吧),三角兽怎么解决冷启动的数据问题的?
亓超:小冰及度秘使用的大部分数据都是互联网公开可见的数据(例如BBS或社区等人与人间的对话数据), 这些数据无论是大公司还是小公司都是可以公平获取的。三角兽成立之初便已开始在各大bbs和社区进行大量的数据的抓取及语料的清洗。
雷锋网:一个完整的聊天机器人或者多轮对话系统,应该包含哪些技术模块?
亓超:聊天系统及对话系统是个庞杂的系统模块 有张技术分解图share给大家来参考。
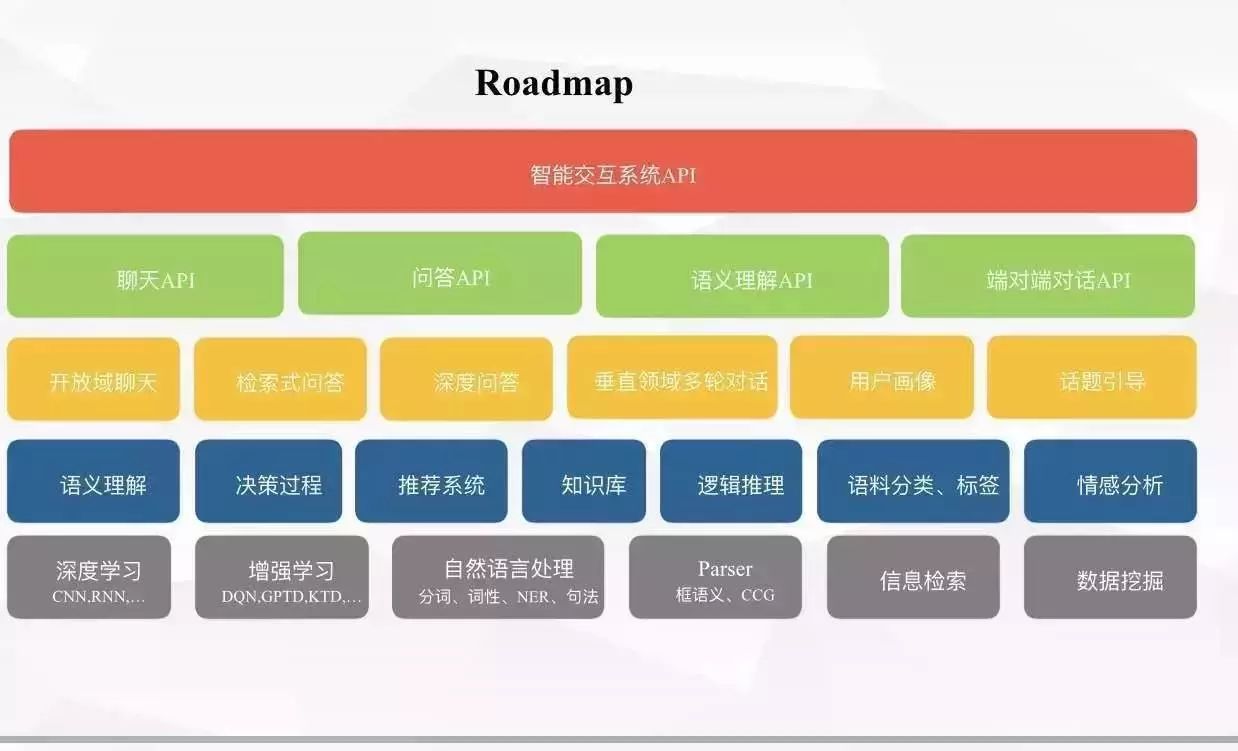
雷锋网:看到图片中对不同的模块进行了颜色区分,可以详细介绍下吗?
亓超:最下面这一层是依赖的基础技术系列 上面蓝色这层是利用基础技术构造的基础技术模块,中间橙色是利用基础技术模块构造的子系统,上面两层是将子系统进行封装 对外提供打包服务 API 应用层。
雷锋网:多轮对话系统开发起来,与单轮对话系统的差异主要是哪些?
亓超:其实严格来讲, 没有单纯的单轮对话系统 涉及对话系统一定是要考虑上下文的处理, 例如订票场景下,用户与机器之间需要进行多次的需求描述、澄清及确认过程来完成订票任务。单轮更偏向于信息获取的系统, 例如搜索引擎及问答系统。
雷锋网:您当时是小冰团队唯一负责核心算法的工程师,开创了开放域聊天系统。可以详细介绍下什么是开放域聊天技术吗?开放域聊天技术与传统用关键字、模板或者人工参与的聊天技术的不同之处是什么?
亓超:开放领域聊天中的开放是指对用户不限定领域, 不会出现像Siri发布之初只能回复特定问题, 超出范围的返回搜索引擎结果, 另一方面聊天以一种模拟人类日常对话的方式进行自然的人机对话, 不同于一个冷冰冰的工具。
开放域聊天系统中也有关键词及模板的方法作为辅助,我们主打的两个技术方向是:
1. 检索式聊天系统: 基于几十亿量级人人对话, 使机器人进行人的聊天模式的模拟;
2. Sequence To Sequnence 端对端的 生成时聊天系统: 利用数据量的精品人人对话语料, 利用RNN等相关技术训练对话模型, 使机器具备对话的能力, 目前主要用于儿童聊天方向。
这两种方法的基础都是统计和机器学习, 关键词及模板的基础是NLP方向中常用的另一种方法规则系统。
无论是检索式还是生成式, 相对于纯规则的聊天系统来讲:
1. 产品体验更好, 聊天回复生动不死板(每个用户的 query 都有较多的回复候选);
2. 系统能力增长空间大, 更易利用到用户反馈及消费大数据的福利;
3. 更易于引入个性化等因素。
雷锋网:在情绪、情感识别一块,国内相对薄弱,我们有哪些技术储备?
亓超:在文本内容中进行情感或观点分类,国内这块其实也不弱。在百度等大的互联网企业这部分也有不少产品点已经商用, 例如百度搜索结果中的观点抽取及聚合。情绪的处理是我们聊天系统中非常重要的模块,目前主流的方法会使用到DNN相关的技术对文本进行表示并进行分类任务, 这块我们也早已用到我们对外的聊天商用服务中, 并会在将来继续扩大这部分的使用场景。例如,情绪分类触发回复中加入表情 及 针对用户情绪分类的结果进行回复的筛选。
雷锋网:Bigbang 以及 Rokid 的产品投入应用之后,有没有发现一些不满意的地方,可否展开讲讲?
亓超:Big Bang 发布后, 我们受启发和鼓励很大, 后续我们会进一步将对话系统中成熟的模块及技术, 拆解出来, 与手机系统绑定, 实现更多更好的手机体验, 同时也能将真实场景下技术迭代带来的收益反馈到对话系统里。
Rokid 与我们的合作在三角兽成立之初的 4 月份便开始合作,一直非常愉快, 后续我们会进一步加大在儿童及家庭场景下聊天及对话系统的研发投入。
雷锋网:感谢亓超老师的精彩分享,以上是雷锋网准备的所有问题,本次课程主干部分结束,亓超老师还有什么要分享的吗?
亓超:我补充两张聊天系统架构图给大家参考。
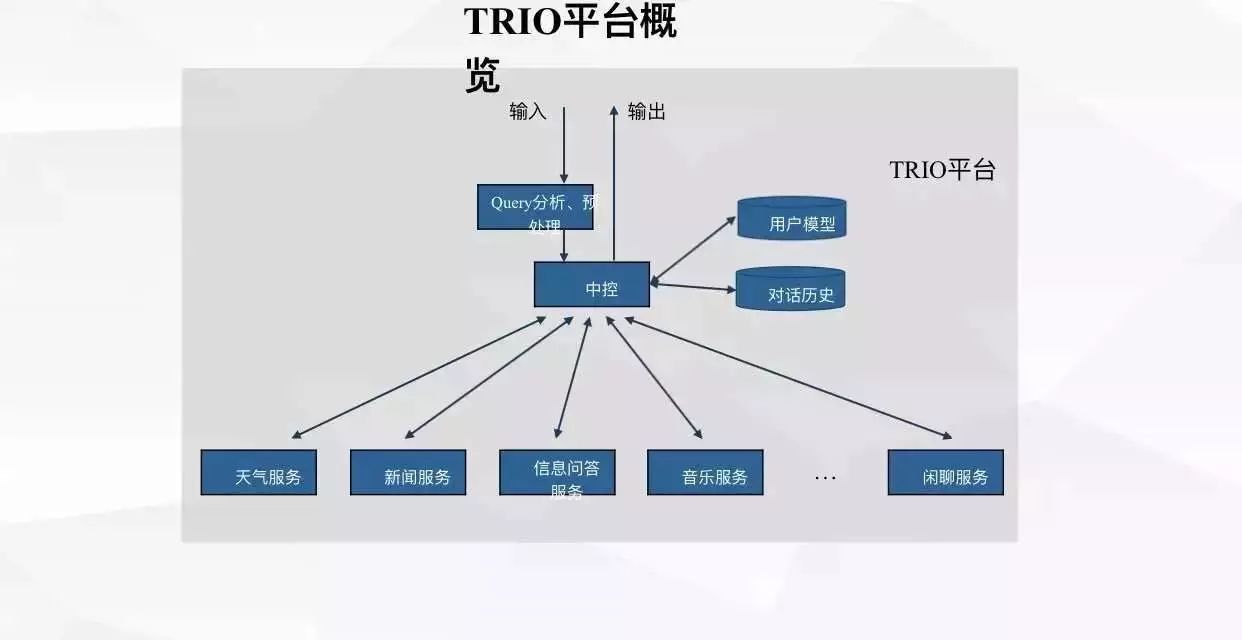
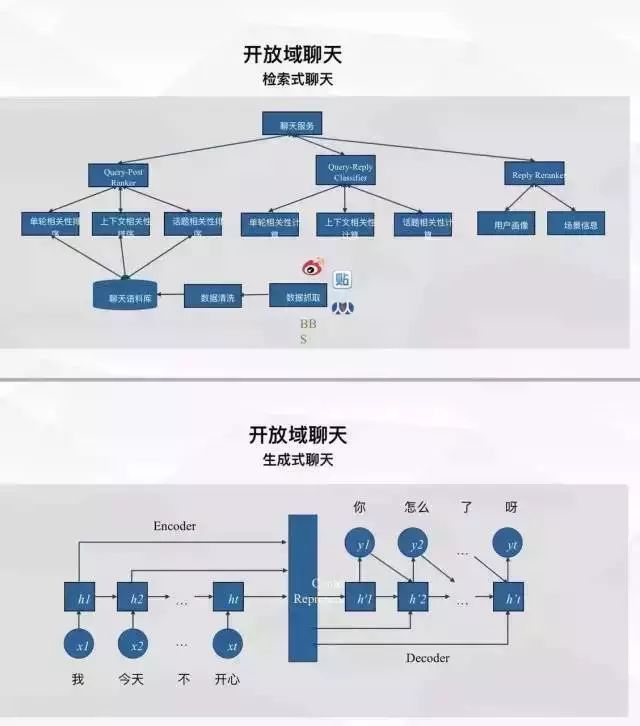
第一张图是我们服务整体架构的示意图 解释依赖的模块以及服务间的关系,另一张图分别介绍了检索式聊天和生产式聊天的原理。
● ● ●
听众问答整理
Q:“语义理解有很多公司再做,图灵,讯飞等,三角兽跟他们有什么不同呢?”
A:讯飞的在语音技术方面有绝对领先的优势,我们目前主要焦点在文本内容的处理,语义技术是其中核心技术之一,我们颇为互补,目的是做整套自然语音交互系统。图灵跟我们的业务有较大重叠,三角兽科技的团队成员在之前经历并打磨出市面上两款较为成熟的产品,小冰和度秘在对人机交互系统的理解上相对较深 并由此也有很多应用与基础技术的积累。
Q:设计聊天机器人最重要的因素是什么?to b 端和 to c 端的有什么区别?
A:聊天机器人要体现智能的特点:死板一问一答,缺少变化,只能回答特定问题等等都会体验很差。另一方面,要有“学习”能力,通过人机对话数据的积累和反馈得到能力的提升。额外,在不同场景下,聊天机器人的角色也要实时发生转变 提供服务功能。这好比,餐厅服务员在上班的时候要提供点餐的功,下班后角色发生转变,会跟朋友一起聊天分享。
Q:对语义理解是基于大量的语料,而互联网词汇翻新速度这么快,并且有大量矛盾的语义理解,这些要如何判断处理?
A:互联网数据的大量更新累计是我们能做好聊天机器人的基础。好比是招待客人,没有菜,就算厨艺再好,也没办法做一桌菜出来。我们在数据处理上已经建立起了一套数据处理的系统 能很快消化新的语料和数据 。
Q:在industry中,比较热门的NLP算法有哪些?有什么优点和缺点?
A:目前比较热门的方法大多是统计机器学习的方法 其中近几年逐渐兴盛的 DNN 相关技术 (在文本上长使用 CNN 和 RNN)占了主导。主流学术会议上 DNN 相关的论文,占了非常大比例。另一方面,在之前里,规则专家系统占主导,一个完整的系统两种方法都需要用到,一般情况是用统计机器学习的方法,砍大刀处理大部分问题,规则的方法作为补充,来剃小刀,处理一些 exception 的问题。
机器学习用到的数据来源,有分人工标注的和非人工标注的数据,机器学习的方法也会分为有监督的和无监督的,数据准备并没有特定统一的原则和标准要根据任务情况来定。举例说明,我们在训练用于判断两句话是否在语义一致的模型上(例如不客气 是否能回答 谢谢),用大量的人与人之间的真实对话,去除掉含有对话背景(例如具体人名 具体时间),后拿了训练 RNN 和 CNN 模型 。
Q:请问嘉宾,对模型进行训练的数据准备方面,能否介绍一下?
A:机器学习用到的数据来源,有分人工标注的和非人工标注的数据,机器学习的方法也会分为有监督的和无监督的,数据准备并没有特定统一的原则和标准,要根据任务情况来定 举例说明 我们在训练用于判断两句话是否在语义一致的模型上(例如不客气 是否能回答 谢谢)用大量的人与人之间的真实对话 去除掉含有对话背景 (例如具体人名、具体时间)后拿了训练 RNN 和 CNN 模型。
Q:我一直很好奇微软小冰的开放式回答结果该如何调教,比如对某个答案不满意,要怎样让她修改?
A:小冰目前应该不支持来自用户的调教。研发的调教会从两个方面进行:语料扩充,模型迭代。
Q:在车载的语音交互的使用场景中,您认为是开放式的交互比较好,还是封闭式的交互比较好。开放式指的是随便用户怎么说,封闭式指的是用户只能说固定的指令。
A:指令性式必须的。例如导航、音乐这些主功能。从我们跟车载设备商的沟通中反应,其实司机在开车过程中,还挺爱聊的。所以只有指令性的功能,无法满足这个场景下的所有需求。我们也在跟车载设备的合作伙伴合作打磨开放式的交互系统。
最后亓超老师说:智能交互系统技术的广度与深度方面都比较复杂。以上单纯一个点展开来讲,也都需要很长时间,在这里 抛砖引玉,详细细节也希望在今后能跟大家经常一起讨论。










