
最近在合并文件的时候,遇到一个诡异的问题。以下边数据为例:
想以第一列基因名称为key,将文件Batata
N215-01-T01
good.count和Batata
N215-01-T02
good.count 第二列的基因表达量合成一个表达量矩阵。
先来看一眼数据的样子:
$ head Batata_N215-01-T01_good.count
G1 1123
G10 46
G100 99
G1000 290
G10000 464
G10001 608
G10002 10
G10003 2629
G10004 6
G10005 0
$ head Batata_N215-01-T02_good.count
G1 831
G10 34
G100 95
G1000 236
G10000
381
G10001 557
G10002 4
G10003 2602
G10004 12
G10005 0
当我用awk进行合并,发现两列数据以极其诡异的形式合在一起。
$ awk -F '\t' 'ARGIND==1{a[$1]=$0}ARGIND==2{print a[$1]"\t"$2}' Batata_N215-01-T01_good.count Batata_N215-01-T02_good.count|head
G1 8313
G10346
G1095 99
G10236 290
G10381 464
G10557 608
G10402 10
G102602 2629
G10124 6
G10005 0
为了确保不是命令的问题。我又找来另一组数据SRR6354710
2M.htseq.count.txt 和SRR6354711
2M.htseq.count.txt 同样进行合并。数据如下:
$ head SRR6354710_2M.htseq.count.txt
ENSG00000000003 0
ENSG00000000005 0
ENSG00000000419 188
ENSG00000000457 38
ENSG00000000460 50
ENSG00000000938 2521
ENSG00000000971 0
ENSG00000001036 249
ENSG00000001084 160
ENSG00000001167 162
$ head SRR6354711_2M.htseq.count.txt
ENSG00000000003 0
ENSG00000000005 0
ENSG00000000419 158
ENSG00000000457 40
ENSG00000000460 47
ENSG00000000938 2315
ENSG00000000971
0
ENSG00000001036 238
ENSG00000001084 183
ENSG00000001167 154
看起来一切正常.
$ awk -F '\t' 'ARGIND==1{a[$1]=$0}ARGIND==2{print a[$1]"\t"$2}' SRR6354710_2M.htseq.count.txt SRR6354711_2M.htseq.count.txt|head
ENSG00000000003 0 0
ENSG00000000005 0 0
ENSG00000000419 188 158
ENSG00000000457 38 40
ENSG00000000460 50 47
ENSG00000000938 2521 2315
ENSG00000000971 0 0
ENSG00000001036 249 238
ENSG00000001084
160 183
ENSG00000001167 162 154
不死心的我,把命令换成下边的。当然,一样的结局。
awk -F '\t' 'NR==FNR{a[$1]=$0;next}NR>FNR{if($1 in a)print a[$1]"\t"$2}' Batata_N215-01-T01_good.count Batata_N215-01-T02_good.count|head
于是跑到小编群去求助大家。小编靠谱熊用我的数据测试了一下,很快给了我回复。是文件格式的问题。
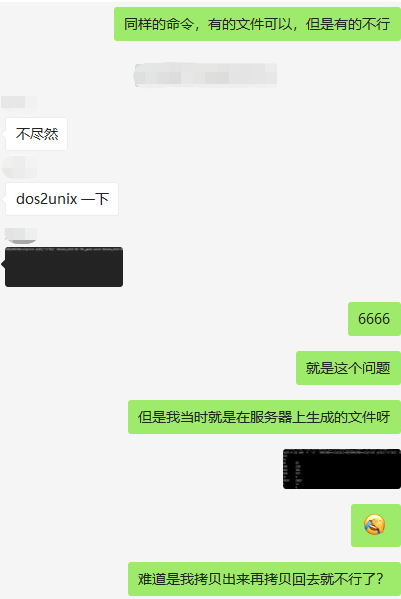
得到真传,赶紧测试一下。果然dos2unix一下,一切正常了。
dos2unix *
$ awk -F '\t' 'ARGIND==1{a[$1]=$0}ARGIND==2{print a[$1]"\t"$2}' Batata_N215-01-T01_good.count Batata_N215-01-T02_good.count|head
G1 1123 831
G10 46 34
G100 99 95
G1000 290 236
G10000
464 381
G10001 608 557
G10002 10 4
G10003 2629 2602
G10004 6 12
G10005 0 0
使用cat -A查看一下隐藏的字符。
dos2unix之前:
$ cat -A Batata_N215-01-T01_good.count |head
G1^I1123^M$
G10^I46^M$
G100^I99^M$
G1000^I290^M$
G10000^I464^M$
G10001^I608^M$
G10002
^I10^M$
G10003^I2629^M$
G10004^I6^M$
G10005^I0^M$
dos2unix之后
2$ cat -A Batata_N215-01-T01_good.count |head
G1^I1123$
G10^I46$
G100^I99$
G1000^I290$
G10000^I464$
G10001^I608$
G10002^I10$
G10003^I2629$
G10004^I6$
G10005^
I0$
当然,另一个小编也提出来,不用dos2unix,也可以。
sed -i 's/\r$//' 需要转换的文件名
真是太坑了。我的数据只是从linux服务器拷贝到windows下,再拷贝到linux服务器。路过而已,路过而已,路过而已。
最后,借用更更的话送给大家。
最后的最后,附送dos2unix的安装方法,常备常安心。
下载dos2unix
curl -L https://sourceforge.net/projects/dos2unix/files/dos2unix/7.4.1/dos2unix-7.4.1.tar.gz/download -O
mv download dos2unix.tar.gz
# 或者
# git clone git://git.code.sf.net/p/dos2unix/dos2unix
安装
tar -zxvf dos2unix.tar.gz
cd dos2unix-7.4.1/
make
# 指定安装路径
make DESTDIR=/×××/×××/ install
echo 'export PATH=/×××/×××/usr/bin:$PATH' >> ~/.bashrc
source ~/.bashrc
dos2unix -h
# OK





