主题:模式识别与智能感知分论坛
时间:2017年5月22日下午
地点:国家会议中心401
本文根据速记进行整理
文字识别:技术现状、挑战及机遇
金连文
华南理工大学电子与信息学院信息工程系主任、教授
刘成林/主持人:下一位报告人是华南理工大学的金连文教授。

金连文:谢谢成林老师的介绍,大家下午好,今天非常高兴在这里做一个文字识别的技术现状、目前存在的问题及挑战、学术研究和商业应用机遇,以及未来技术发展趋势的报告。

首先简要谈一下人工智能。去年3月份,美国纽约时报采访了硅谷一些IT的大神们,请他们谈一下未来IT领域当中什么方向是潜在的爆发点,当时很多专家都不约而同谈到一个观点,就是人工智能很可能是未来IT领域的大事件。其实不仅仅是在工业界,在计算机学术界乃至整个科学界,人工智能过去几年都是非常热门的研究话题,举例来说,在过去两年,与深度学习和机器学习相关的文章已经有5次上了Nature或Science的封面文章。难怪科普期刊《Scientific American》去年撰文说人工智能的春天来到了。在国内,我们发现人工智能的春天似乎也正在悄悄来临,从中国工程院、科技部以及政府,都在积极推动人工智能学术研究及其在产业中的应用发展。

视觉感知是人工智能当中特别重要的问题之一,为什么这么说呢,我们人类对世界的感知大约80%是通过眼睛获取的。计算机视觉使得人工智能看懂世界,典型的技术包括图像识别,人脸识别,视频监控等等,这里还想强调一点,文字识别也是非常重要的计算机视觉技术。因为文字是我们感知这个世界最重要的手段,无论是从小学习知识到长大进行交流,衣食住行都离不开文字。在生活当中,文字也无处不在,离开了文字有时候我们很难理解整个社会和世界。文字的重要性还表现在很多方面,它是人类文明的标志,是信息交流的途径,学习知识的重要渠道,是记录历史、思想、文化的载体,文字和文明、文化还有很大的关系,现在很多人用惯了拼音输入法,很可能造成提笔忘字等现象,这是挺遗憾的一件事情。


有一句话这样说,一图胜千言,但是有时候如果图片当中没有文字,我们很难理解这个图片的含义。这里有两幅图,左边图是我在法国一家酒店里拍的照片,右边是一个漫画,大家能够猜到它们表达什么意思吗?特别是左边这个图,当时坑了我很久。右边图中配文是“心中的天气是晴是雨全在自己”。没有图片我们可能表达起来不是那么生动,但是没有文字,有时可能无法理解其含义。比如这幅图,没有文字说明很难猜其表达什么含义,其实它的配文是来自《金刚经》中的一句话“一切法无我,得成于忍”,讲凡事包容、忍耐的道理。再举个例子,这是个一个商品、商品包装的里面的正反面,大家第一眼看到可能想到这一定是药品或保健品,但是实际上它是一个食品---葡萄干。所以,我这里想表达一个观点就是,文字的重要性是非常大的,某种意义上来讲,如果给你一张图,若图上有文字,80%以上的情况下,图上的文字信息是最重要最有信息量的。所以文字识别这个问题是一个重要的人工智能问题,从这个角度看,文字识别的问题如果没有解决好,人工智能就不能称得上真正的、完整的人工智能。
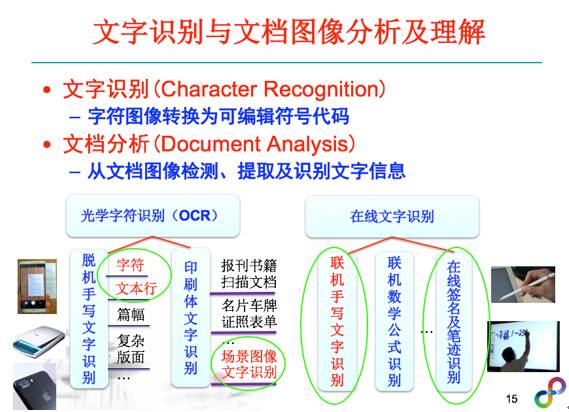
下面我讲讲文字识别的一些技术的现状。文字识别包括文档分析和文字识别两个部分。从文字获取的途径可以把文字识别分成OCR和在线文字识别两大类。OCR是处理及识别通过光学设备如数码相机、扫描仪获取的文档图像,在线文字识别是处理通过数字笔、触摸屏捕捉的文字数据。两类问题都有很多不同的研究子问题及应用场景,今天由于时间关系,我重点给大家介绍一些领域的现状、和它面临的挑战和机遇。
文字识别的研究发展历史已经有很多年的历史,最早可以追溯到上世纪20年代,上世纪80年代90年代是文字识别的重要发展时期,那时候在图书报刊数字化、邮政编码及自动分拣、表单名片识别等都产生了非常广泛的应用,2000年以后,随着智能手机和移动互联网的兴起,基于拍照和OCR以及手写识别及Ink理解受到了更多的关注。
我先讲一下手写文字识别,这个技术现在在手机、平板电脑的为输入法相当普及,基本上是标准的配置功能之一,另外一方面就是OCR的手写文字识别,如快递单识别理解等等这样的问题,也是有很多的应用场景。传统的手写文字识别的一般框架包括预处理、特征提取、分类器设计等三个主要模块,每个模块技术都需要仔细设计,比如图像归一化做的不好就会明显影响识别性能。
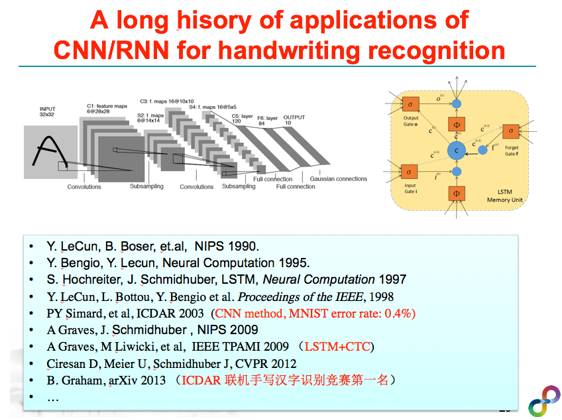
自从有了深度学习技术之后,文字识别这个事情变得简单多了,我们现在利用相关的深度学习技术如CNN、DNN、RNN,可以把这个问题解决的很好。当然我后面也会讲,只是简单直接应用CNN等技术或许可以达到还不错的结果,但是你要达到State-of-the-art的结果,还是需要一定的领域知识来辅助你做解决这个问题。我这里还想说一下,其实在文字识别一直是深度学习一个主要的应用方向,深度学习如CNN/LSTM等模型在文字识别的应用有很长的历史,上世纪90年代,深度学习的先驱者如Y. Lecun,很早就用神经网络来解决文字识别,1998年,Lecun和Bengio合作设计了LeNet5解决了手写数字识别问题,这是他们在贝尔实验室做的Demo。后来包括微软剑桥研究院的学者在2003年就用CNN将MNIST的错误率做到了很低的程度(0.4%)。
刚才说了,简单利用深度学习解决手写汉字这些比较难的问题,效果并不是很理想,所以过去两年国内有很多研究团队,针对手写写文字的识别做了大量的工作,包括我们团队做的一些针对汉字识别的DropSample训练新方法,还有一些领域知识与CNN的结合,如英国华威大学的Graham教授、我们团队在CNN中引入了路径积分特征图这样的领域知识层,可以进一步提升文字识别的准确率。大家知道,在2012年CVPR的文章,直接用CNN网络来解决手写汉字识别还干不过传统的Bayes方法,但是现在我们可以把CNN/RNN等用的更好,远超过传统的方法。这是中科院自动化所做的最新的工作,他们也发现加上一些领域知识,结合CNN的方法,可以更好把文字识别这个问题解决的更好。这个是中科院自动化所基于循环神经网络,针对文字识别提出的一种Sequential Dropout 方法,使得模型的鲁棒性做的更好,这个结果是目前文字识别中识别率最高的。
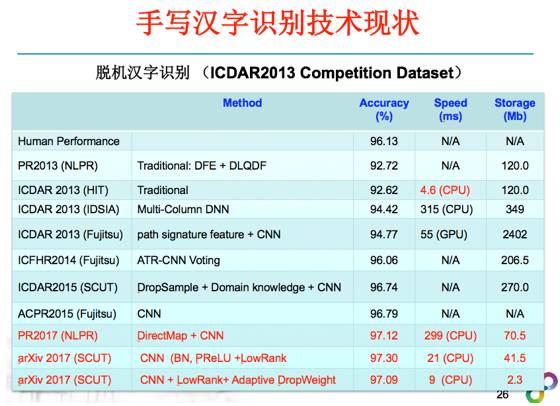
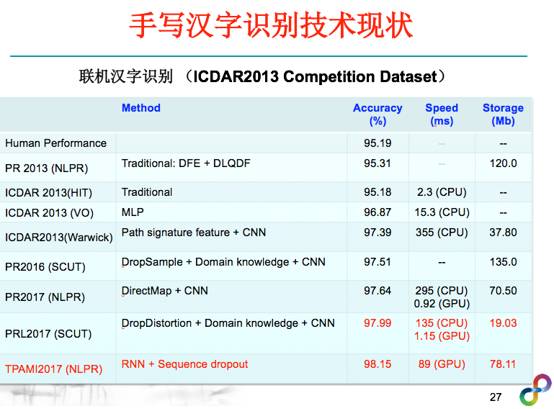
有了深度学习的技术和我们的领域知识相结合以后,单字符的文字识别技术现在基本上解决的差不多了,这是联机汉字识别在公开评测集的技术指标现状,深度学习的结果基本上都超过了人眼识别的水平。
手写识别另外一个有用的方向就是在签名识别,或者笔迹鉴定领域,今天国内外特别是国外大超市购物刷卡的时候,收银系统已经在开始使用数字化的签名,但目前这个签名目前还没有办法做自动的识别和鉴别,实际上本来签名是一种有效的身份认证技术。传统的方法需要做很多特征的分析及提取,相似度的判断等等。过去几年我们发现,利用深度学习也可以有效的解决笔迹识别的问题。笔迹识别比较大的挑战就是训练样本很少、很难获取。我们针对这个问题提了一些数据增广方法,并结合领域知识,目前基本上可以把这个问题解决的很好。这是中科院自动化所做的另外一种方法,是利用RNN做的,结果做的特别好。在书写者识别的一个数据集上,识别率已经做的很高了,但是值得指出的是,这个数据还是很小,只有不到200人的规模,实际应用能否经受得起考验,这可能还有很长的路要走。
签名的数据很难获取,因为涉及到个人的隐私,这两年也有一些学者开始用深度学习的方法解决,而且解决的还不错,这是一种基于深度学习的度量学习方法。另外我们团队做了一种基于RNN深度网络的方法,看一下在SVC数据库,基于深度学习的方法也可以做到很高的准确度。这里还想给大家一个信息就是,一般而言深度学习需要大数据才能进行有效训练,但在签名识别这个小数据问题上,我们发现通过数据增广等方法,深度学习也大有用武之地。
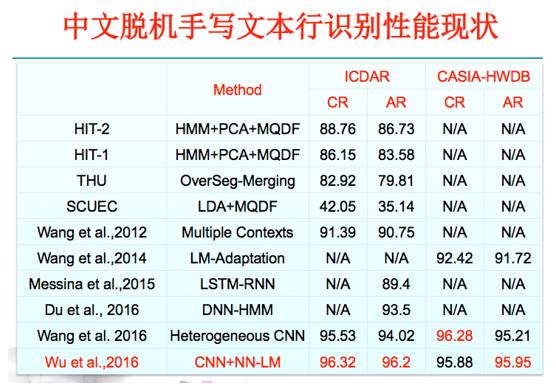
文本行识别是文字识别中另外一个传统的问题,包括有基于分割和无分割的方法。这个是传统的基于过切分的中文脱机无手写文本行识别的一些典型方法,后面的两种用了CNN分类器;这是基于HMM无切分的识别。这是法国的学者在2015年用多方向LSTM的方法来解决中文脱机手写文本行识别,但是当时的性能还干不过传统的方法。当然现在富士通及中科院的团队把传统方法结合CNN以后,现在的性能有了明显的提升。
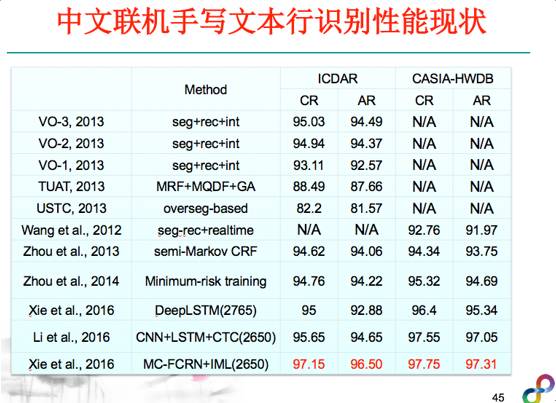
在联机文本行识别方面思路和脱机识别一样,这两年也有很多关于深度学习方面的文章应用,这里举个例子,比如哈尔滨工业大学的研究团队提出的多层LSTM识别模型,模型虽然很简单,但是效果非常好。这是我们团队做的工作,基于全卷积回归神经网络中文联机手写文本行识别,可能是目前公开文献报道中最好的结果,我们也把这个系统实现到云端了。和三年的技术相比,目前手写文本行这个技术有了显著进步。但在篇幅级的识别,比如给你一段文档,特别是图文混排版面复杂情况,这个问题还比较难。虽然已经有很多学者在关注这个问题,这个问题还没有得到彻底的解决,其中一个一方面的原因是目前学术界还缺乏足够多的真实数据。这是一种利用attention机制和MDLSTM来解决篇幅级的文字识别的方法,可以进行整行的检测,然后再做识别。不过这个法文数据集的挑战还不是特别大,就算这样的数据集目前也没有做的特别好,针对手写中文的篇幅级研究报道还不多见,所以还有很多研究的机会。
对于手写识别研究还有另外一个重要的问题,就是要解决移动端实时应用问题,因为手机的输入法必须实时处理,这方面我们做了一些相关的工作,我们利用了矩阵分解和自动裁剪网络链接的方法,在3755类汉字识别的问题上,可以把模型大小压缩到2M左右,速度在CPU上可以做到9.7毫秒每个字,可以达到实用化的程度。在联机汉字识别方面我们采用相关的技术也可以把CNN模型大小压到很低,一般的文字识别CNN网络模型大小有几十MB甚至上百MB,但是我们可以压到0.6M左右而精度损失不到1%。基于这样的技术,我们实现了面向移动端和网络端的识别引擎,左边是手机端的SCUT gPen手写输入法的Demo,右边是网络端(www.deephcr.net),识别精度还不错,只要你写得基本上像一个汉字,一般都可以识别出来。我们移动端的识别引擎目前已经授权给搜狗公司使用,搜狗Android端及iOS端的手写输入法目前采用了我们提供的识别引擎。
虽然手写输入法已经广泛普及,其实无约束手写识别尚未完成解决,例如国家标准GB/T18790—2010联机手写汉字识别系统技术要求与测试规程,要求手写输入软件及设备需支持识别正负45度的手写样本。这个问题消费者可能没有觉得很重要,所以目前的许多产品都还没有解决好。在整个文本行识别当中,我们测了五种主流的输入法,(在iPad装了相关的手写输入法软件),这里是五种软件识别的情况,有个别的输入法根本不让你进行整行无约束的书写,有一些能够识别一些字,但整体而言识别率还不高,所以这个问题离真正的解决,还有一定的距离。最下面识别得最好的是我们实验室做的网络版的Demo。另外,有一些输入法对生僻字以及常见的符号的识别支持也并不太好,最常用的一些符号如“√” 的识别都不支持。
第二个方面给大家介绍一下场景文字的检测与识别,这是一个典型的OCR问题,在计算机视觉里近年来广泛受关注的一个研究问题,包括场景图像中文字的检测,文字识别,端到端的解决技术等。场景文字检测面临的挑战,包括有不同的语种、任意的长度、形状、颜色,复杂背景、复杂字体、光照、噪声干扰等等。
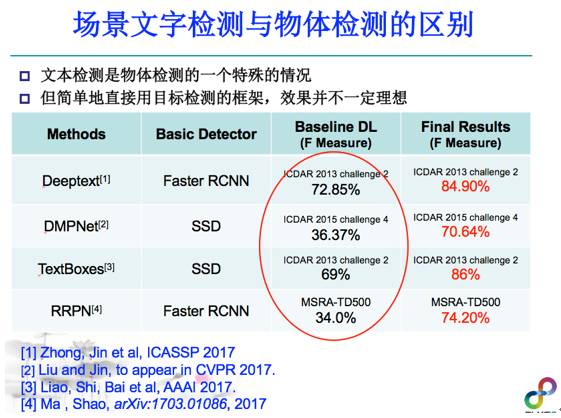
传统的文字检测方法主要包括基于滑窗的方法和基于连通域分析的方法。其优点是速度快,无需大量的数据来进行模型训练,但缺点是识别性能不够高。近年来基于深度学习的物体检测方法如Faster R-CNN/YOLO/SSD/R-FCN等为解决此问题提供了全新的解决思路。虽然文字检测可以看成是物体检测的特殊例子,但是简单的把深度学习中的物体检测的框架做检测是达不到理想的效果的,这是四篇最新的文章给出的对比实验结果,可以看到如果直接用Faster R-CNN、SSD甚至干不过传统的方法,但是如果针对文本检测的问题做一些特殊的设计,检测效果就会得到明显提升。
这是去年CVPR提出的一种基于FCN深度网络来进行场景文字检测的方法,是华中科技大学学者发表的文章,这个方法比之前的结构的有了很大的提升。另外,他们今年在AAAI上还提出了一种基于深度学习的TextBox文本检测方法,针对文字检测设计了特别的Text-box layer。这是我们实验室今年CVPR2017录用论文的一个工作,我们基于SSD框架提出使用任意四边形回归的方法检测场景文本,主要的优点是可以把文字检测更加紧密一点,方便做后面的识别,在ICDAR2015年挑战4的检测效果当时在公开文献报道中是最好的。但是今年我们发现有很多相关工作,把这个准确度快速提升上来了,比如华中科技大学研究团队也基于SSD的框架,采用多个小框回归及合并的方法,在ICDAR 2014挑战4上F Measure做到了75%;复旦大学的研究团队提出了一种RRPN及旋转矩形RoI Pooling的方法,做到77%;这是Face++今年CVPR的论文,基于PVANet,设计了多种不同的损失函数来进行多方向文字检测,做到了80.72%;这是中科院自动化的研究团队所做的工作,也是利用类似FCN等深度学习的方面,ICDAR2014挑战4上做到了81%左右,可能是目前公开文献报道中最好的结果。
这里我给出了ICDAR场景文字检测及识别竞赛(ICDAR 2015)官网上最新公开的一些结果。我们看到挑战2的问题基本上得到了不错的解决,挑战4最近两年之内检测识别性能指标也有很大的提升。当然值得提一下这两个数据集的规模其实都还很小。图片数量都不到1000张。

文字和检测识别另外一个问题就是端到端的解决方案,牛津大学VGG实验室第一次提出了结合传统方法和CNN做端到端的可学习的解决方案。针对场景文字当中的识别,华中科技大学研究团队提出一个很好的框架叫CRNN,提出了一个端到端的解决框架,他们的网站可以下载到相关的实现代码。
场景文字还有很多有趣的应用,比如可以辅助我们进行图像的搜索和图像的分类,这篇华中科技大学研究人员的论文,通过文本检测识别输出的编码Word Vector以及图像识别网络GoogleNet的输出编码Vision Vector,两者拼在一起再进行最后做图像的细粒度分类。举个例子,这里是一大堆的瓶子,这里面有可口可乐、有饮料瓶,还有啤酒瓶等等,上面有文字信息可以辅助来进行图像的细粒度分类,极大的提升它的分类准确度。

第三个方面我讲一下文字识别的市场机遇,这方面包括图像搜索引擎、自动驾驶、金融保险、AR、智能机器人、教育医疗等等很多领域都有很多应用。比如OCR技术,在移动办公、远程开户,智慧物流都有应用。像名片识别这种比较成熟的技术,我们一般联系人信息输入名字和电话号码就完了,利用这个技术就可以把联系人的各种信息包括单位、职务、email地址等完整保留起来。场景文字检测还可以用来做辅助图像搜索,包括以词搜图,更好的提升图像搜索的用户体验;另外一个典型应用是AR眼镜实现实时场景包括街景的文字翻译,这里还可以产生很多创新应用,例如可以让盲人看懂世界、盲人看大片等等。另外,笔计算与数字墨水也是一个有很大潜在应用的市场,今天的触摸屏及数字笔的书写体验和传统纸张书写体验还有很大差距,如果这方面的硬件技术做好的话,Ink识别理解及搜索都会有很大的各种不同应用场景。另外,还需说一下其实国内从事文字识别及应用的企业也有不少,同学们如果从事这个领域的研究,将来找工作完全不用担心,这里我列举了一些,比如国际国内专门做文字识别及应用的公司,还有很多大公司像微软、Google、三星、BAT等也有文字识别的部门或小组。用“早稻”这个企业搜索网站以关键词OCR进行搜索,可以找到100多家相关的企业。
下面举一些成功应用的例子,比如车牌识别这个比较成熟的技术,据搜狐网上面的一篇文章报道,2014年国内车牌识别收费系统的市场容量大于37亿,随着车辆的普及以及智慧小区、智能停车场的大量普及,而且未来5年以年均17.4%的复合增长率在发展,早稻网中输入“车牌识别”,也可以找到好几百家公司,所以我们看到OCR相关技术已经逐渐走入了市场。
在证照识别、银行卡的识别方面也有很多成功应用的,例如腾讯的微信添加银行卡功能就利用OCR来自动识别录入银行卡,三星做了一个SamsungPay,拍一下卡就可以支付了,不需要刷卡机了。别的应用包括还有金融保险集团的应用,这是我从商汤公司以及上海合合信息公司网站上的截图,可以看到他们利用OCR技术和金融保险行业的业务进行结合应用。
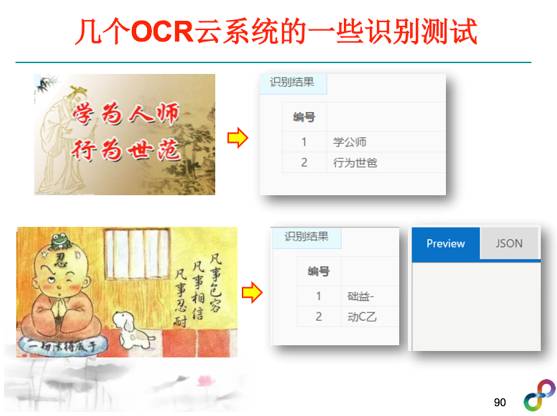
某些特定的垂直领域的OCR技术解决差不多了,但是对于更通用的场景文字OCR解决怎么样了呢?我们测试了百度、微软、谷歌几个主流的OCR云端识别情况,在背景比较简单、字体比较规范情况下,即使字有倾斜,这几个引擎识别的还不错,虽然偶尔有一点小错误,其中这个是做的最好的,我就不说是哪家公司了。但如果字体不是很常见,例如这是一个茶馆的标牌,我们看到不少文字都识别错了。图像分辨率不太高情况下,几个引擎识别率都不高。这个图中的文字按理说很规范,但八个字就错了三个字。另外,图像中有手写体文字的情况下,基本上大多无法进行正确检测及识别。所以我们看到场景文字OCR这个问题目前还远远没有得到解决。

文字识别还有很多困难和挑战,比如金融票据的识别、签名识别(主要是我们缺乏足够的数据)、混合手写印刷体的邮政快递表单识别、书法古迹文献识别、教育文档例如中小学生的手写作业及试卷(特别是数理化文档)的OCR,这些问题都有很大挑战性,就更不要说医疗行业中医生写的处方病历等手写体字符了。另外还有来自网络的一些奇特或者艺术化的文字图像,人虽然能轻松辨识,但这样的图像文字识别,未来5年都不一定能得到解决。
最后我谈一点个人对此领域未来技术发展的趋势和展望,要解决我刚才讲的OCR和文字识别的技术,第一方面就是要有更好的技术理论和方法,除了目前的深度学习之外,我们也期待别的新理论方法的出现,还有无监督学习、弱标注学习、One-shot Learning方法等等。第二个方面是自主学习、长效学习或终身学习这些新方法,都可能会为我们解决大数据无标注或弱标注情况下的OCR问题提供新的解决思路。第三方面,现在人工智能还处于刚刚起步的阶段,离强人工智能还很远。在OCR领域我们今天也只能做一些简单的识别感知问题,从感知到智能理解再到高层认知,还有很长的路要走。第四方面,对文字识别仍然需要更好的端到端的解决方案,例如对场景文字OCR,我们需要把检测和识别做成完全可学习的端到端的解决方法;图文混排复杂版面的手写及印刷体OCR,也可尝试进行版面分析加自动分割加识别的端到端可学习方法的研究探讨。第五方面,从应用角度看,我认为垂直行业的有非常多的行业应用机会,例如金融、保险、自动驾驶、医疗、教育、机器人、AR、智慧城市等等。第六方面,手写体的识别,尤其是复杂版面下的手写体OCR,这个问题远远没有得到解决。第七个方面,刚才我讲了数据,高质量的数据和大数据是非常关键的,我们现在很难获取一些特定领域的文档数据,例如金融文字图像数据,快递表单文档图像数据等等,这需要学术界和工业界一起合作解决相关问题。未来有没有更多更好的数据非常值得我们期待。
最后谈一个观点,我们今天的针对一些典型的模式识别问题的解决方案还做得不够智能及通用,针对不同的视觉识别问题都需要设计不同的识别模型,例如人脸有人脸识别引擎,图像有图像识别引擎,文字有文字识别引擎,这相当于我们今天的人工智能其实是需要很多只不同的眼睛来解决不同的视觉感知问题。将来有没有可能设计一个通用的解决方案,哪怕针对文字OCR这个特定领域的问题,把手写、场景文字、表单、名片、证照等等用一个通用的统一方案来解决这些问题,无论从理论和技术上都值得研究,这样我们文字识别这个眼睛才真正称得上是人工智能领域中的一只智慧的眼睛。
我的报告就到这里,谢谢大家!
刘成林/主持人:谢谢金教授的报告,在技术和应用方面介绍的很全面,对未来的发展也有很多的思考。
提问:我有两个问题,第一个问题,您对整篇文档级的文字识别有什么看法?
金连文:国内外学者例如法国的研究人员做过相关的研究工作,但是数据做的比较简单,传统的印刷体识别版面分析已经有很多年的研究历史了。针对复杂版面混合手写图文的情况,我们现在还缺乏足够的数据,如果有数据以后,有没有可能用深度学习这样的思路来解决是值得做的一个方向。
提问:您有做尝试吗?
金连文:目前还没有开始。
提问:我也是没有数据,所以一直没有动手做。第二个问题,就是上一位嘉宾华老师PPT里有一张写的是char-Gan关于车牌的文字生成问题,这种技术可能对OCR有用吗。
金连文:我们试过手写OCR的情况,也许我们做的还不是特别深入特别对,目前的结论是GAN看起来很美好,但对识别率提升并不是很明显。
提问:对,比如像印刷体,都是99%的识别率,错误率很小,这种情况如何呢?
金连文:如果已经99%就没特别的必要用GAN合成样本了。针对复杂背景场景文字的合成,我们也初步尝试过,从对检测识别的角度来看,目前至少我们还没有试成功,GAN目前的技术有没有实际应用价值还有待观察。这方面我不是专家,我的经验只能到这里,谢谢。
提问:金教授,我刚才听了您的演讲,涉及到了手写体,我是做金融和合同一些比对数字识别的,在识别当中我发现一个问题,无论国内和国外,都说对印刷体的识别率可以达到99.9%几,但是在实际过程当中,真正要用的时候,按照10个字段测试,他们的识别率最高只有百分之七十几,我想知道一下,国内公司哪一个公司做的比较好?
金连文:这个我不能给他们做广告,我了解也不一定不全,比如汉王文通好像有做金融票据处理的解决方案,其他还有上海合合信息、微模式等等。你用通用的OCR肯定不行的,为什么之前报道的识别率那么高,可能因为那些数据规模很小,而且很干净,和实际应用差距很大。所以我希望你们公司也能公开一些数据,学术界很难拿到这些数据,如果把数据脱敏以后,希望公开一些数据,这样工业界和学术界可以一起来把这些问题解决好。
提问:在我们所有的识别里,我们最感兴趣的是可信研究,每个汉字的识别结果要非常可信,不需要人工介入的处理,您有什么建议?
金连文:像深度学习模型本身你用Softmax层的输出是可以获得识别结果的置信度描述的,当然不能百分之百的可信,百分之九十多还是可以的,我们团队在ICDAR 2015的一篇论文中研究过这个问题。另外,在机器学习、模式识别等领域,研究置信度的工作有很多,您可以查查相关的文献。
CAAI原创 丨 作者金连文
未经授权严禁转载及翻译
如需转载合作请向学会或本人申请
转发请注明转自中国人工智能学会










