构建智能运维平台,运行监控和故障报警是两个绕不过去的重要部分。本次分享主要是介绍引入SRE理念后的基于时间序列数据存储的报警工程实践。
SRE报警介绍

今天我分享的主题是SRE基于时间序列数据的报警实践,既然是基于时间序列。
首先,我先简单介绍一下什么是时间序列数据。
时间序列(time series)数据是一系列有序的数据。通常是等时间间隔的采样数据。时间序列存储最简单的定义就是数据格式里包含timestamp字段的数据。时间序列数据在查询时,对于时间序列总是会带上一个时间范围去过滤数据。同时查询的结果里也总是会包含timestamp字段。
监控数据大量呈现为时间序列数据特征,所以,为了应对复杂的监控数据格式,在每一份数据中加上时间字段。区别于传统的关系型数据库,时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别契合需要处理海量时间序列数据的物联网应用场景。
Google的监控系统经过10年的发展,经历了从传统的探针模型、图形化趋势展示的模型到现在基于时间序列数据信息进行监控报警的新模型。这个模型将收集时间序列信息作为监控系统的首要任务,同时发展了一种时间序列信息操作语言,通过使用该语言将数据转化为图标和报警取代了以前的探针脚本。
监控和报警是密不可分的两个部分,之前我们公司的CTO肖德时曾经做过关于基于时间序列数据监控实践的分享,在本次分享中就不重复介绍前面的监控部分,感兴趣的同学可以去看看老肖的文章(http://blog.dataman-inc.com/shurenyun-sre-207/)。
运维团队通过监控系统了解应用服务的运行时状态,保障服务的可用性和稳定性。监控系统也通常会提供Dashboard展示服务运行的指标数据,虽然各种折线图看着很有趣,但是监控系统最有价值的体现,是当服务出现异常或指标值超过设定的阀值,运维团队收到报警消息,及时介入并恢复服务到正常状态的时候。
SRE团队认为监控系统不应该依赖人来分析报警信息,应该由系统自动分析,发出的报警要有可操作性,目标是解决某种已经发生的问题,或者是避免发生的问题。
监控与报警
监控与报警可以让系统在发生故障或临近发生故障时主动通知我们。当系统无法自动修复某个问题时,需要一个人来调查这项警报,以决定目前是否存在真实故障,采取一定方法缓解故障,分析故障现象,最终找出导致故障的原因。监控系统应该从两个方面提供故障的信息,即现象和原因。
黑盒监控与白盒监控
黑盒监控: 通过测试某种外部用户可见的系统行为进行监控。这是面向现象的监控,提供的是正在发生的问题,并向员工发出紧急警报。对于还没有发生,但是即将发生的问题,黑盒监控无能为力。
白盒监控依靠系统内部暴露的一些性能指标进行监控。包括日志分析,Java虚拟机提供的监控接口,或者一个列出内部统计数据的HTTP接口进行监控。白盒监控能够通过分析系统内部信息的指标值,可以检测到即将发生的问题。白盒监控有时是面向现象的,有时是面向原因的,这个取决于白盒监控提供的信息。
Google的SRE大量依赖于白盒监控。
设置报警的几个原则
通常情况下,我们不应该仅仅因为“某个东西看起来有点问题”就发出警报。
紧急警报的处理会占用员工宝贵的时间,如果该员工在工作时间段,该报警的处理会打断他原本的工作流程。如果该员工在家,紧急警报的处理会影响他的个人生活。频繁的报警会让员工进入“狼来了”效应,怀疑警报的有效性和忽略报警,甚至错过了真实发生的故障。
设置报警规则的原则:
-
发出的警报必须是真实的,紧急的,重要的,可操作的。
-
报警规则要展示你的服务正在出现的问题或即将出现的问题。
-
清晰的问题分类,基本功能是否可用;响应时间;数据是否正确等。
-
对故障现象报警,并提供尽可能详细的细节和原因,不要直接对原因报警。
基于时间序列数据进行有效报警
传统的监控,通过在服务器上运行脚本,存储返回值进行图形化展示,并检查返回值判断是否报警。Google内部使用Borgmon做为监控报警平台。
在Google之外,我们可以使用Prometheus作为基于时间序列数据监控报警的工具,进而实践SRE提供的白盒监控理念。
监控报警平台架构图:
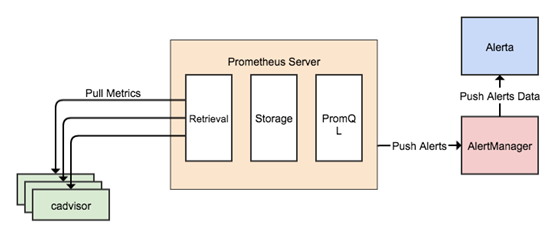
为了方便测试,我们在测试服务器上用容器运行以上组件,测试服务器地址192.168.1.188。
-
启动两个Nginx容器,并分配不同的label标识一个属于Dev组的应用,一个属于Ops组的应用
-
启动cAdvisor容器,端口映射8080
-
启动Alertmanager容器,端口映射9093,配置文件中指定Alerta的地址作为Webhook的通知地址。
-
启动Prometheus容器,端口映射9090,CMD指定“-alertmanager.url”地址为Alertmanager的地址。
-
启动MongoDB作为alerta的数据库
-
启动Alerta,端口映射为8181
容器运行截图:
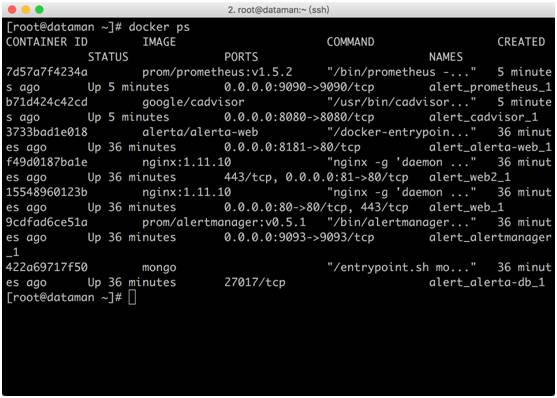
cAdvisor原生提供http接口暴露Prometheus需要收集的metrics,我们访问http://192.168.1.188:8080/metrics。





