编辑:弗格森
【新智元导读】
近日,新加坡国立大学LV实验室首次提出多人解析(Multi-Human Parsing)任务,对传统的人物解析进行了拓展与延伸,从而更好地匹配现实应用场景。他们构建了一个全新的大规模多人解析数据集(MHP),并给出了相应的评测标准,极大地推进了深度学习与计算机视觉领域相关技术的发展。

基于人物图像的细粒度解析是计算机视觉领域的一个非常重要的任务。人物解析(Human Parsing)指的是将人物图像按像素级别分割成属于身体部位或衣物项目的多个语义一致的区域。人物解析技术是很多实际应用的基础与关键,如虚拟现实、视频监控与群体行为分析。与单人图像解析相比,在多人交互的场景中进行人物解析则更具挑战性、更有现实意义。
为了解决这一难题,近日,新加坡国立大学LV实验室首次提出多人解析(Multi-Human Parsing)任务,对传统的人物解析进行了拓展与延伸,从而更好地匹配现实应用场景。他们构建了一个全新的大规模多人解析数据集(MHP),并给出了相应的评测标准,极大地推进了深度学习与计算机视觉领域相关技术的发展。针对所提出的多人解析任务,他们又提出一个全新的多人解析器(MH-Parser)模型,该模型在端到端训练过程中将全局信息与局部信息进行有机融合,性能远优于简单的“检测+分割”的方法。
作者赵健对新智元介绍说:“之前做Human Parsing这个任务的都是基于single instance,也就是每张图片中只有一个人,然后通过传统方法或者深度学习的方法对图片中的人物进行pixel-wise的dense classification,他们没有考虑更加贴近实际的多人场景。与我们的工作比较类似的还有一个叫做"Instance-Aware Object Segmentation"的任务,相关方法虽然也会针对多人进行检测与分割,但是只能给出以人物为最小单位的分割结果,并不能细化到每个人的衣服、饰品以及人物各个部位。因此,为了弥补这个研究缺口,我们提出“Multi-Human Parsing”这个任务并构建相应的数据集,我们在检测图中出现的所有人物的同时也能够给出像素级精细的分割结果,这对于虚拟现实、监控安防、群体行为分析、服饰识别与检索、自动化产品推荐等场景具有非常大的应用价值与意义。”

作者:李建树(新加坡国立大学)、赵健(新加坡国立大学 & 国防科学技术大学)、魏云超(新加坡国立大学)、郎丛妍(北京交通大学)、李浥东(北京交通大学)、冯佳时(新加坡国立大学)。
注:前两名作者为同等贡献(均为第一作者)。导师冯佳时(https://sites.google.com/site/jshfeng/)是新加坡国立大学助理教授、新加坡国立大学LV实验室(http://www.lv-nus.org/)带头人,,本研究工作受新加坡国立大学启动基金、新加坡教育部学术研究基金资助。
【论文摘要】
近年来,可用的大量数据资源极大驱动了人物解析( Human Parsing )技术的发展。本文阐述了当前一些基准数据集与真实世界的人物解析场景之间的关键差异。比如,当前所有的人物解析数据集仅仅包含单人图像,然而在真实场景中通常会有多个人物同时出现的情况。因此,同时对图像中的多个人物进行解析更为符合实际需求,同时也对已有的人物解析方法提出了更大的挑战。不幸的是,相关数据资源的匮乏严重地阻碍了多人图像细粒度解析方法的发展。
为了进一步推进人物解析研究,作者首创多人解析(MHP)数据集,每张图像均包含现实世界场景中的多个人物。 具体而言,MHP数据集的每张图片包含2-16个人物不等,每个人物按照18个语义类别(背景除外)进行像素级别的标注。此外,MHP图像中的人物有多种姿态、不同程度的遮挡以及多样化的交互。为了解决所提出的多人解析这一难题,作者提出了一个新型的多人解析器 (MH-Parser)模型,在针对每个人物进行端到端解析的过程中,同时考虑全局信息与局部信息。实验结果表明,这一模型远优于简单的“检测+解析”方法,使得其作为一个稳定的基准,助推未来在真实场景中人物解析的相关研究。
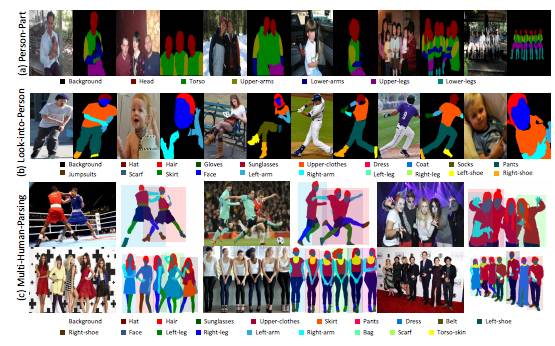
图1:MHP数据集与PASCAL-Person-Part和Look into Person两个Human Parsing数据集部分样本的可视化对比。
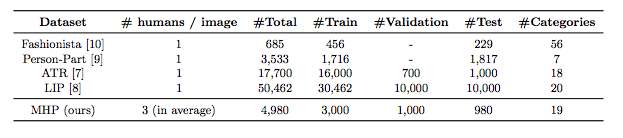
表
1:MHP
数据集与其他
Human Parsing
数据集的统计数据对比
,
其中包括每张图片中平均出现的人物数量、图像总数、训练图像数量、验证图像数量、测试图像数量以及语义类别数量。
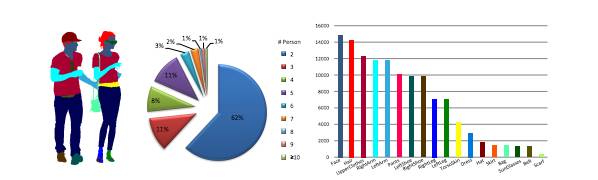
图2:(左)MHP数据集标注示例;(中)每张图片所含人物数量的统计信息;(右)语义类别统计信息。
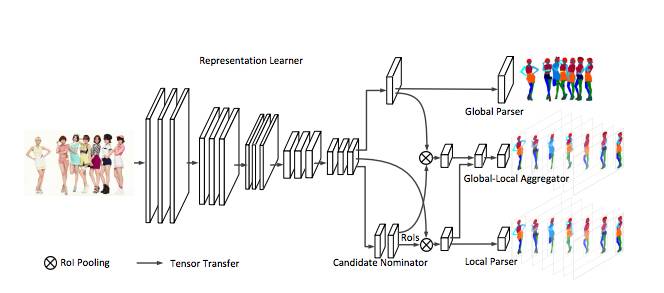
图3 :MH-Parser模型的原理图。
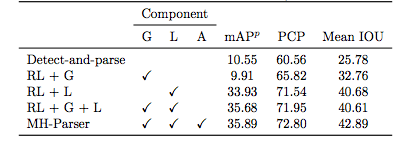
表2:不同模型所取得的解析结果对比。不同的模型使用的是不同的组件(G代表全局解析器,L 代表局部解析器,A 代表聚合器)。
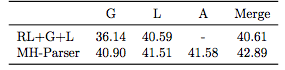
表3 :MH-Parser模型与其他变体的性能指标对比。
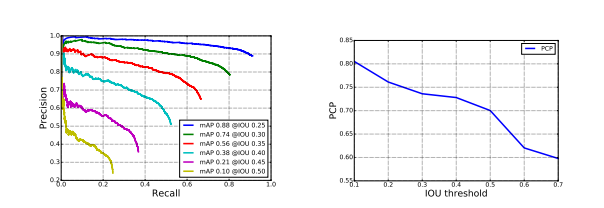
图4:准确率--召回率曲线以及PCP-IOU曲线。

图5:MH-Parser模型在Human Parsing数据集的预测结果可视化。

图6: 错误案例分析。
作者赵健对新智元表示,后续他们的工作还将围绕“Multi-Human Parsing”展开与深入,将提出更加有效的方法来解决这一难题,也将构建更大规模、更加精细的数据集来推动相关技术的发展和进步。
论文原文链接:https://arxiv.org/abs/1705.07206






