来源:Github,OpenAI blog
编译:文强
【新智元导读】
OpenAI 日前提出了一类强化学习替代方法,号称能与最先进的方法相媲美乃至更好。但是,昨天却有用户在 Github 表示“他们有点儿作弊了”,称结果无法复现。这究竟是怎么回事?

OpenAI 日前发布了一类新的强化学习算法——近端策略优化(Proximal Policy Optimization,PPO),称这类算法的实现和调参更加简单,并且性能与当前最佳方法相当乃至更好。PPO 也是如今 OpenAI 默认使用的强化学习算法。
昨天,一位用户在 Github 上提出质疑,表示根据他的使用经验,PPO 并没有 OpenAI 说的那么好。
“OpenAI 日前提出了一种号称比强化学习速度更快、需要较少超参数调整的替代方案。到目前为止,我的经验并不支持这些说法。”Github 用户 peastman 留言说:“在我的大部分测试中,它比 A3C 慢,而不是更快。并且,它和 A3C 有相同的超参数,还添加了几个新的参数。”
当然,peastman 也表示,也许他的情况是个例,其他人或许能成功复现 OpenAI 的论文。
peastman 表示,OpenAI PPO 论文的作者“有点作弊了”(kind of cheat)。“他们并没有把 PPO 与 A3C 进行比较。相反,作者比较的是他们称为‘A2C’的单线程版本,并且仅仅基于性能如何随着训练步骤数量增多而提升。作者没有考虑性能与时钟时间的关系。这隐去了一个非常重要的问题:PPO 无法并行运行,因为它在一个线程上执行所有优化,所有其他线程都处于空闲状态。”
“此外,PPO 每一组 rollout 都运行几个优化周期,因此每步的 CPU 时间要高得多。作者在论文中的比较再次产生了很大的误导。他们说,PPO 在 100 万次训练步骤后,比‘A2C’性能更好,但并没有提到 A3C 可以在相同的时钟时间内完成 400 万次的训练步骤。”
“每次迭代,都必须先生成所有的 rollout,然后在多个 epoch 中重复在优化器里运行所有这些。而且,你需要先把这些都完成了,才能开始生成下一组 rollout。”
让 peastman 如此纠结的 PPO 究竟是什么呢?

摘要
我们为强化学习提出了一类新的策略梯度法,可以通过与环境的交互在样本数据(sampling data)中进行转换,使用随机梯度下降优化替代目标函数(surrogate objective function)。标准的策略梯度法是在每一个数据样本上执行一次梯度更新,而我们提出的新目标函数可以在多个训练步骤(epoch)中实现小批量(minibatch)的更新。这种新方法称为近端策略优化(proximal policy optimization,PPO)。PPO 拥有置信域策略优化(TRPO)的一些好处,但更加容易实现,也更通用(general),并且根据我们的经验有更好的样本复杂度。我们在一组基准任务上测试了 PPO,包括模拟机器人运动和玩 Atari 游戏,这些基准测试表示 PPO 要比其他在线策略梯度法更好。考虑到总体的复杂度、操作简便性和 wall-time,PPO 是一种更好的选择。
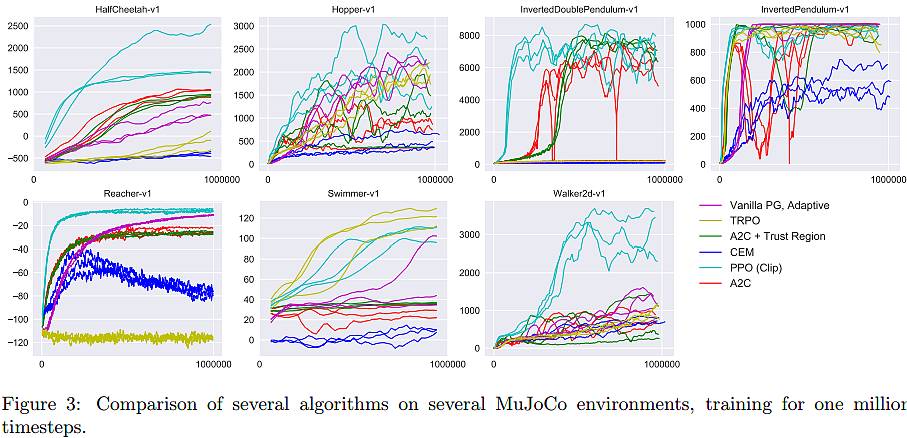
上图显示了 PPO(浅蓝色线条) 与 Vanilla PG (Adaptive)、TRPO、A2C + Trust Region、CEM 和 A2C 的对比。
论文地址:https://arxiv.org/pdf/1707.06347.pdf
OpenAI 官方博文:PPO 在实现简单性、样本复杂度和调参难度之间取得了平衡





