来自:博客园,作者:莱布尼茨
链接:
https://www.cnblogs.com/newton/p/9611340.html
本文主要借demo介绍基于Tendermint的区块链应用开发,这个demo很简单,主要包含以下功能:
1、扔漂流瓶
2、捞漂流瓶
3、之后投放者和打捞者可以相互传递[加密]信
代码已上传至Github。
Github地址:
https://github.com/tuoxieyz/driftbottle
Tendermint
Tendermint帮我们实现了PBFT,相当于搭了一个共识框架,包含两部分:
Tendermint-core:
PBFT共识算法实现;
Tendermint-abci:
定义了应用须实现的接口和调用规则,还实现了与外部通信的socket-server。
官方的这部分源码可以看做是Go-abci,我们也可以根据需要编写其它语言的xxx-abci。
可以将其类比为传统应用的开发框架(如MVC),而我们要做的就是基于abci编写具体的区块链逻辑(为方便和清晰起见,本文用Go编写具体逻辑,自然abci就用官方的了),这就实现了服务端,而用户也需要一个客户端用来与区块链交互。
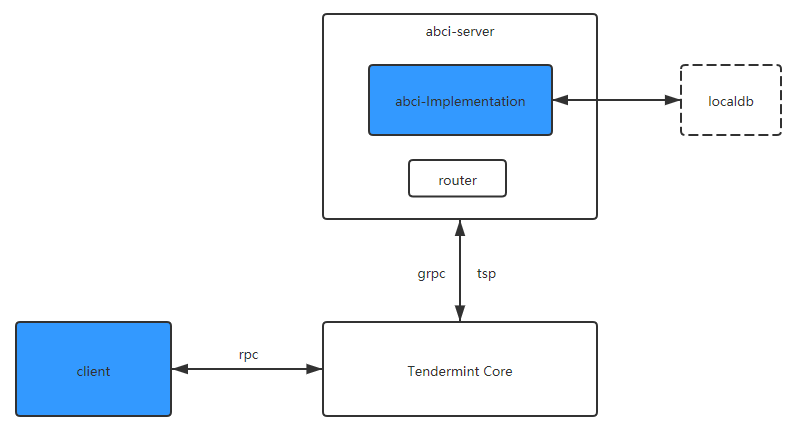
以上,Tendermint、服务端逻辑、客户端,三者组成了一个完整的区块链应用。
数据库
在动手编码之前,要考虑数据存储的问题,选择文本文件还是Oracle呢?区块链网络里大部分是普通电子设备,使用者亦是普通人,让他们事先安装大型数据库显然不现实,更不用说区块链本身不会出现复杂操作数据的业务。
另外由于全节点数据的完备性,用不着通过网络去其它设备上查询数据,很多数据库自带的网络服务也不需要(SPV这种,业务单一,完全可以单独开放一个远程接口)。而文本文件、excel之类的,只适合人类使用,根本不能算作数据引擎。
我们需要的是一个满足基本CUID的高效的本地数据库,目前大多区块链使用LevelDB作为存储引擎,这是C/C++编写的本地kv数据库,原作者也写了Go实现的版本,其原理可参看:
《
半小时学会LevelDB原理及应用
》
godoc地
址:
https://godoc.org/github.com/syndtr/goleveldb/leveldb。LevelDB总体上采用了LSM-Tree的设计思想(LSM-Tree的虽说是数据结构,但更偏重于设计思路)。
LevelDB同时只能被一个进程使用。另,以太坊的数据存储于/chaindata目录下,运行后其下会生成一坨.ldb文件,而非网上常说的sst文件,这可能是跟13年的一次版本更新有关,Release LevelDB 1.14。另:LevelDB的k-v模式(顺序读效率不高)不适合relationship,即不适合有一定数据关联度的业务场景。
为方便使用,可以封装一些常用的数据库操作。顺便尝试下提供新操作的几种思路。
1、直接给leveldb.DB增加新方法:
func (db *leveldb.DB) Set(key []byte, value []byte) {
err := db.Put(key, value, nil)
}
然而,给一个类型新增方法只能在该类型同个package中,否则编译时会报“Cannot define new methods on non-local type XXXX”的错误。此时,可以怀念下C#的扩展方法。
2、既然无法在外部修改leveldb.DB的方法集,那么就在当前package建一个继承leveldb.DB的struct,即内嵌一个leveldb.DB类型字段,
type GoLevelDB struct { *leveldb.DB }
,然后将上述代码的指针类型改为*GoLevelDB即可,很完美。不过,在封装Get方法的时候出问题了:
func (db *GoLevelDB) Get(key []byte) []byte {
res, err := db.Get(key, nil)
return res
}
不支持重载,只能修改子类的方法名,蛋疼;或者改成如下方式。
type GoLevelDB struct {
db *leveldb.DB
}
和第2种的区别就是把is-a改为has-a,也不用担心方法重名的问题。不过我私以为若Go支持重载,第2种方式会好一点,至少不会嵌套太多层。
服务端
abci定义了如下接口:
type Application interface {
Info(RequestInfo) ResponseInfo
SetOption(RequestSetOption) ResponseSetOption
Query(RequestQuery) ResponseQuery
CheckTx(tx []byte) ResponseCheckTx
InitChain(RequestInitChain) ResponseInitChain
BeginBlock(RequestBeginBlock) ResponseBeginBlock
DeliverTx(tx []byte) ResponseDeliverTx
EndBlock(RequestEndBlock) ResponseEndBlock
Commit() ResponseCommit
}
很明显,后面几个方法参与了区块链状态的更迭,我们就来捋捋交易从客户端提交到最终上链的过程(不精确):
1、节点a的客户端发起一笔交易tx;
2、节点a服务端调用CheckTx方法校验tx是否合法,若非法则丢弃,当做什么事都没发生过;
3、若合法,则将tx加入到本地mempool中,并向其它节点广播tx;
4、其它节点接收到tx,同样执行2-3步骤;
5、某轮决议开始,提议者搜集mempool中的txs,并发起投票,达成共识后,各节点调用BeginBlock开始将它们打包;
6、调用DeliverTx执行每笔交易并将其记录到区块中(一笔交易执行一次DeliverTx);
7、调用EndBlock表示打包完成;
8、
发起共识决议,提议者将新区块广播给其它验证者;
(共识决议在第5步完成)
9、
其它验证者接收到区块后,调用DeliverTx执行每笔交易并校验结果,若没问题则广播commit请求(预提交)和新区块;
10、
若节点收到超过2/3验证者的commit请求,调用Commit方法
,更新整个应用状态。
假如将要打包的tx缓存起来,我们就可以在DeliverTx、EndBlock、Commit三个方法中选择其一实际执行tx,但是一般来说,交易执行都是放在DeliverTx,比较符合语义。
EndBlock用于更新共识参数和Val集合,Commit用于更新整个应用状态(apphash),需要注意的是,本次提交的apphash若与上次提交的不同,则会继续产生新的区块(不管有没有新交易,就算设置consensus.create_empty_blocks=false,tendermint也会产生空区块,可参看 Enable no empty blocks #308。),这似乎是tendermint的有意设计,但不知为何。
另Query方法接收的RequestQuery类型参数有Path和Data两个字段,Path是string类型,Data是[]byte,应该是对应于Http的get、post。示例代码中我是通过正则表达式解析Path查询各类数据,其实若是复杂查询/结构化查询,还是Data字段比较实用。
正则表达式的所谓零宽断言:
只匹配位置,而不消费字符。
下面举个例子。如 \b\w*q[^u]\w*\b,它能匹配“Iraq,Benq”。因为[^u]总是匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),接着后面的\w+\b将会匹配下一个单词,于是\b\w*q[^u]\w*\b就能匹配整个Iraq fighting。如果在这个例子中,我们只想匹配到Iraq,那么可以采用零宽负向先行断言(?!exp)的方式,\b\w*q(?!u)\w*\b,它将不会消费Iraq后面的空格或逗号等字符,因此\w*也不会匹配到下一个单词。参看 【详细】正则表达式30分钟入门教程 之位置指定和后向位置指定部分。
客户端
demo采用命令行终端,基于cobra库。
1 var rootCmd = &cobra.Command{
2 Use: "dbcli",
3
4
5
6
7
8
9 }
10
11 func main() {
12 if err := rootCmd.Execute(); err != nil {
13 fmt.Println(err)
14 os.Exit(-1)
15 }
16 }
原本我想实现交互模式(类似mysql>),但cobra似乎没有提供相关方法,我们只好自己想办法,需要注意的是需要自解析用户输入,比如用户输入有空格,该空格是分隔参数还是参数内部的,要做区分。
原本打算参考cobra解析命令行的源码,发现实际解析使用的是spf13/pflag库,而pflag只是加强了go标准库flag,而flag库也并没有涉及到参数值本身的具体解析,这部分工作依靠的是oa库,主要是oa.Args属性,它依赖更底层的代码。
var Args []string
func init() {
if runtime.GOOS == "windows" {
return
}
Args = runtime_args()
}
func runtime_args() []string // in package runtime
如注释所示,windows下是在exec_windows.go中实现,其它操作系统的实现没找到,应该是使用其它语言编写或直接调用的系统api。进exec_windows.go中,发现关键函数readNextArg:
1
2
3 func readNextArg(cmd string) (arg []byte, rest string) {
4 var b []byte
5 var inquote bool
6 var nslash int
7 for ; len(cmd) > 0; cmd = cmd[1:] {
8 c := cmd[0]
9 switch c {
10 case ' ', '\t':
11 if !inquote {
12 return appendBSBytes(b, nslash), cmd[1:]
13 }
14 case '"':
15 b = appendBSBytes(b, nslash/2)
16 if nslash%2 == 0 {
17
18
19
20 if inquote && len(cmd) > 1 && cmd[1] == '"' {
21 b = append(b, c)
22 cmd = cmd[1:]
23 }
24 inquote = !inquote
25 } else {
26 b = append(b, c)
27 }
28 nslash = 0
29 continue
30 case '\\':
31 nslash++
32 continue
33 }
34 b = appendBSBytes(b, nslash)
35 nslash = 0
36 b = append(b, c)
37 }
38 return appendBSBytes(b, nslash), ""
39 }
其中对双引号做了处理,注释中还提供了一个网址How Command Line Parameters Are Parsed,应该是关于这方面的算法说明。
网址:
http://daviddeley.com/autohotkey/parameters/parameters.htm
序列化
当我们在说序列化的时候,我们在说什么。序列化说白了就是数据转化,或者说一一对应的映射关系。就内存场景来说,一个对象序列化为另一个对象,本质上它们都一样,都是存储在内存中的0、1序列,只是同一个东西不同的数据表达。比如将一个数值序列化(或者说转化)成字符串类型,或者将数值int32转为数值int8,那么内存中的存储空间和存储数据都不会一样,字符串还要看用的什么编码。再如我们将一个对象序列化为byte[],不同的方案会产生不同的结果。比如使用C指针将物理数据直接映射出来,或者以json方式序列化,或者protobuf序列化,会产生不同的byte[];反之亦然。
不管是json编码还是二进制编码,物理上存储的都是二进制,json编码包含于二进制编码,我们可以根据需要自定义二进制编码,一般是为了减少存储占用的空间。比如json编码,对1、2等数值类型是按字符串格式编码(如utf8格式,1编码的就是0x31,12占两个字节0x310x32),而我们自定义二进制,完全可以把12存储在一个字节里面,该字节值就是数值本身;就算不是数值,而是字符串本身编码,我们也可以在utf8编码后再压缩,类似gzip。










