来源:南方都市报
唐朝诗人最喜欢的季节是春天,最钟意的动物是龙、马,最喜欢提及的地名是江南……
这不够,他还要告诉你全唐诗中排名第一的“好基友”是哪两位;初唐、盛唐、中唐、晚唐各时期诗坛社交网络如何,分别产生了以谁为中心的“朋友圈”……程序员的文章发表后,引发不凡的阅读量与回应,同时有人文领域的研究者指出其不足之处。高呼“代码改变世界”操之过急,技术的进步带给人文社科领域巨大的推力却是不争的事实:跨界研究有益亦有趣。
2017年2月26日,“前进四先生”终于在自己的微信公众号“前进日志”上贴出了《当我们在读唐诗时,我们在读什么》。说起他的职业“航天工程师”,似乎和唐诗没有任何关联,日常工作围着数据分析、写程序转,是标准的“程序员”。用“前进四先生”(以下简称“前进四”)的话来说:“这是一个非常严谨的行业,容不得半点差错。”
能写出这篇文章,和他另一个身份定位有关:古典诗词爱好者。平日对诗词抱有浓厚兴趣,读过不少相关书籍,在心情不好时喜欢读诗的他和千千万万观众一样,在春节期间关注到一档综艺节目《中国诗词大会》。节目的热度刺激了他的职业习惯:用数据分析遇到的各类问题,唐诗也包括在内。“前进四”对记者表示,用科技手段来分析文艺作品在学术界并不新鲜,其之前也读过相关论文,如浙江大学徐永明《中国古典文学研究的几种可视化途径———以汤显祖研究为例》。只不过这些文章多流传在学术圈中,并没有流传开来。
“程序员”开始行动了。为分析唐朝诗歌,他先从网上找来一份全唐诗,其使用的版本共2609位作者,收录42974首诗。通过Python(一种计算机程序设计语言)这种工具,他决定小试牛刀,分析唐诗中出现的字、词,找找有哪些好玩的点。
第一个问题,唐朝诗人谁的作品数量最多?程序统计的结果前三名是:白居易(2643首)、杜甫(1151首)、李白(897首)。而位居第四的是NA(843首),即“无名氏”。“前进四”后来告诉南都记者,这个统计只局限在全唐诗里,存在的不足是各个作者流传至今的诗词数量不一,提醒读者其中可能存在误差:“比如全唐诗中白居易的诗最多,这是因为白居易生前自己编纂过文集,李杜则没有,所以白的文章流传到后世的就比李杜的多一些”。
接着,他用计算机统计全唐诗中常见的字、词,例如出现最多的字、季节、颜色、植物、动物等词汇分别是哪些。“前进四”称,这些检索十分简单,只需要几行代码就可以实现;而检索的关键词是他本着对于诗歌常见意象的阅读经验想出来的。让我们看看他得出的结论:唐诗中出现最多的字是“不”字;四季出现的频率中,“春”和“秋”呈现出压倒性的场面;颜色中,诗人用的最多的是“白”色;植物中,“松”“竹”最受诗人喜爱;动物中,“龙”“马”出场次数高于其他种类,对此“前进四”开玩笑———“难道唐朝也讲龙马精神”?
至于以词为单位的分析,他告诉记者,实际与字的分析原理相同,但借助了THULAC这个分词工具。“前进四”解释,THULAC在分词之后,还能同时得到词的词性(同时他提到,此分词工具有缺陷。计算机之所以能分词,是因为它从大量的人工分词结果中学习了规律。THULAC是用现代语文分词的材料训练出来的,相应的,THULAC也就在现代语文材料分词中表现良好,针对古代文献没那么理想)。比如这个词到底是形容词,动词还是名词?THULAC的词性划分得非常细致,其中就有地名词性、时间词性、处所词性等,因此统计唐诗中出现的地名、时间、场景等也较为简单。
根据“前进四”的统计,唐诗中最常出现的地名是“江南”和“长安”,他在文中如是说———“毕竟一个地方环境好,一个地方是首都,想必这两个地方的房价一定也很贵。”那么,什么具体场景能引发诗人们的兴致呢?门前、海上、江边、楼上,“这就跟我们现在到景区门前要合影留念,到海边、河边、高楼上都要拍照发朋友圈是一个意思吧”。
更进一步,通过word2vec这个工具,实现词到向量的转换,即所有词可转换成一长串数字。由此,计算机以数字之间的相似度可以简单分析诗句中词与词之间的关联。“前进四”向记者解释,这个转化过程非三言两语能说清楚。粗略来讲,不同词的上下文是不一样的,但是又有一定的相关性。比方说“苹果”和“梨”,这两个词出现的语境应该会很相似,比如:“我们去水果店买苹果/梨吧”,“午饭后再吃个苹果/梨”。在这两个句子中,苹果和梨都是可以互换的词。而“苹果”和“猫”就基本不可能出现在相同的上下文语境中。计算机通过分析每个词上下文出现的词,最后可以每个词转换为一串数字。上下文比较接近的词,这串数字就比较接近。
以此手段,“前进四”找出了与“寂寞”关联密切的10个词:唯有、今夜、摇落、怅望、故国、伴、惆怅、深春、明日、旅。他在文中这样写道:“能看出来,诗人们往往在春日的深夜里,在树叶摇落的季节里,在旅途中,怀念故国的时候,最容易寂寞。这也难怪,我写完上个句子,都感觉有点寂寞了呢。”
3月12日,“前进四”又贴出另一篇分析成果《计算机告诉你,唐朝诗人之间的关系到底是什么样的》,超高的阅读量让他感到惊讶:“最初只是为了好玩,没想到有这么多人喜欢。”他告诉记者,这篇文章写的时候其实很随意,远没有之前写数学类文章那么认真。如果能知道有这么大的传播度,就会更加认真些。
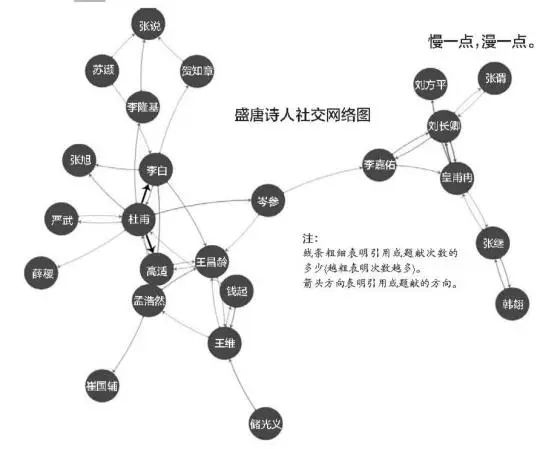
这篇文章,他把关注焦点放在诗人身上,试图理清两个诗人以至于多个诗人间的关系。如何解决呢?借助全唐诗,他把“关系”简化为“引用关系”,即诗的标题和正文中只要提到过对方,那么两者之间的引用关系加1。一首诗如果提到多次对方,只算一次引
用。“前进四”对记者说,“这种引用关系的分析只是大体上的分析。如果要认真分析两位诗人之间的关系,势必要按年代顺序来分析两者之间的唱和作品,这工作量有点大,并且不是我擅长的内容”。计算机无法对引用的诗做细微的情感分析,因此文中的诗坛“社交网络”“朋友圈”都只是以“引用关系”为依托。
全唐诗共2000多名作者,诗人的别称又很多,比如杜甫字子美,按排行称为杜二,按官职称为杜工部。为了让他们对号入座、不重复、不遗漏,“前进四”使用CBDB(中国历代人物传记资料库,系统性收录中国历代名人传记资料)查询诗人的主要信息及别名,排除年代不符的重名,手动补充遗漏部分。由于把全唐诗所有诗人关系都理出来会很乱,借助CBDB来的筛选,“前进四”将762位诗人纳入社交网络的关心范围。
范围既定,程序运行。首先,看一下著名的李白与杜甫。全唐诗中,杜甫写了12首与李白有关的诗,李白则只有3首与杜甫有关的诗。虽然“前进四”也调侃“李白这种朋友确实差劲了一点”,但对于近来网上流传的李杜二人的段子,他觉得“看看笑笑就好”。“前进四”表示,杜甫写李白的诗多,一方面因为李白是长辈,比杜甫大了十来岁,成名时间也早得多,更多的是因为杜甫和李白的性格不同:李白飘逸,杜甫深情。










