抽奖是一个典型的高并发场景应用,平时流量不多,但遇到大促活动,流量就会暴增,今年的周年庆期间的日均UV就超过百万。在过去的一年里,负责过这个项目的多次重构工作,期间各种踩坑无数,就以此文当做总结,来聊聊我们是如何架构这个高并发系统吧。
在我看来,能提高服务器应对并发的能力的方式无非两种:
-
限流削峰:通过降低实际抵达服务器的并发量,降低服务器处理压力;
-
性能优化:从前台到硬件,优化系统各方面性能,提高服务器处理能力。
接下来我们围绕这两个方面谈谈在1号店抽奖系统中所做的工作和遇到的坑。
整体架构如下图:

1. 服务器层的限流削峰
我们的负载服务器使用的是A10,商业的负载均衡硬件,相比Nginx,虽然花不少钱,但在使用配置等方面简单,便于维护,Web服务器自然是Tomcat。这里我们优化了两件事情。
a) 防cc
负载均衡作为分布式系统的第一层,本身并没有好说的。唯一值得一提的是针对此类大流量场景,我们特意引入了防cc机制,策略为单ip限制200/每分钟的最高访问次数,超出频率的请求直接拒绝,防止用户使用脚本等方式刷请求。这个在我们使用的负载均衡器A10上可以自行配置,如果是Nginx也有限制连接模块可以使用,这也是流量削峰的第一层。
b) Tomcat并发参数
我们之前线上的Tomcat是使用默认的参数maxThreads=500,在流量没有上来之前没什么感觉,但大流量情景下会抛出不少异常日志。在通过性能压测后发现,在并发请求超出400+后,响应速度明显变慢,后台开始出现数据库,接口等链接超时,因此将maxThread改为了400,限制tomcat处理量,进一步削减流量。
2. 应用层的限流削峰
从这里开始,请求就进入应用代码中了,在这一层,我们可以通过代码来进行流量削峰工作了,主要包括信号量,用户行为识别等方式。
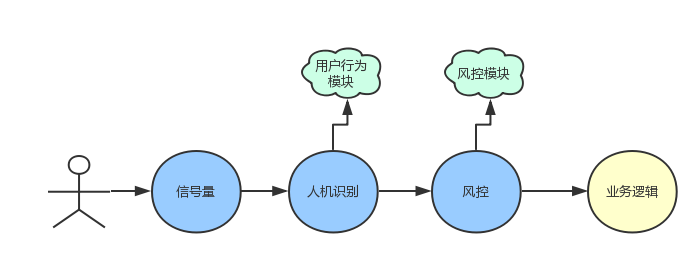
a)信号量
前面谈到了通过Tomcat并发线程配置来拦截超出的流量,但这里有一个问题是超出的请求要么被阻塞,要么被直接拒绝的,不会给出响应。在客户端看到的是长时间没有响应或者请求失败,然后不断重试,我们更希望在这个时候响应一些信息,比如说直接给出提示没有中奖,通知客户端不再请求,从而提高用户体验。因此在这里我们使用了Java并发包中的Semaphore,伪代码如下:

由于通过压测得出的Tomcat最大线程数配置为400,这里的信号量我们设成了350,剩下50个线程用来响应超出的请求。在这种情景下,我们曾用800个并发做过测试,由于请求还未抵达复杂的业务逻辑中,客户端可以在10ms内收到错误响应,不会感到延迟或请求拒绝的现象。
b) 用户行为识别
Tomcat及信号量进行的并发控制我称之为硬削峰,并不管用户是谁,超出设置上限直接拒绝。但我们更想做的是将非法的请求拦截掉,比如脚本,黄牛等等,从而保证正常用户的访问,因此,在公司风控等部门同学的协助下,引入一些简单的用户行为识别。
-
实时人机识别:在用户请求过程中,我们可以得到这么一些数据,点击行为、IP、userAgent、设备码等等,将这些加密之后推送到人机识别模块,如果发现用户没有点击操作,UA,设备码等缺失或不一致,自然就可以将这个请求标识为非法请求,直接拦截。
-
风控列表:除了实时的人机识别,根据还可以根据一些账号或者ip平时的购物等行为进行用户画像识别出其中的黄牛,机器账号等等,维持着一个列表,对于列表中的账号可以按风险等级进行额外的拦截。
下图一个接入用户行为识别前后的一个流量对比图。

可以明显的看到,两天的同一时刻,在未接入识别时流量峰值为
60w
,接入识别后流量降为
30w
。也就意味着有人通过脚本等工具贡献了超过一半的请求量;另一个比对是,在没有接入识别时,我们一个活动数万奖品,在活动开始
3秒钟
就已经被抽光,而接入之后,当活动结束时刚好被抽完。
所以,如果没有行为识别的拦截,不少正常用户根本抽不到奖品,这点跟春节抢火车票是一样的场景。
c) 其他规则
其他规则包括缓存中的活动限制规则等等,根据一些简单的逻辑,也起到一定作用的流量削峰。
至此,我们所有的流量削峰思路都已经解释完了,接下来是针对性能优化做的一些工作。
3. 应用层的性能优化
性能优化是一个庞大的话题,从代码逻辑,缓存,到数据库索引,从负载均衡到读写分离,能谈的事情太多了。在我们的这个高并发系统中,性能的瓶颈在于数据库的压力,这里就聊下我们的一些解决思路。
a) 缓存
缓存是降低数据库压力的有效手段,我们使用到的缓存分为两块。
-
分布式缓存:Ycache是1号店基于Memcache二次开发的一个分布式缓存组件,我们将跟用户相关的,数据规模大的数据缓存在Ycache中,减少不必要的读写操作。
-
本地缓存:使用分布式缓存降低数据库压力,但仍然有一定的网络开销,对于数据量小,无需更新的一些热数据,比如活动规则,我们可以直接在web服务器本地缓存。代表性的是EhCache了,而我们那时比较直接粗暴,直接用ConcurrentHashMap造了个轮子,也能起到同样的效果。
b) 无事务
对于并发的分布式系统来说,数据的一致性是一个必须考虑的问题。
在我们抽奖系统中,数据更需要保证一致,活动奖品是1台iPhone,就绝不能被抽走两台。常见的做法便是通过事务来控制,但考虑到我们业务逻辑中的如下场景。
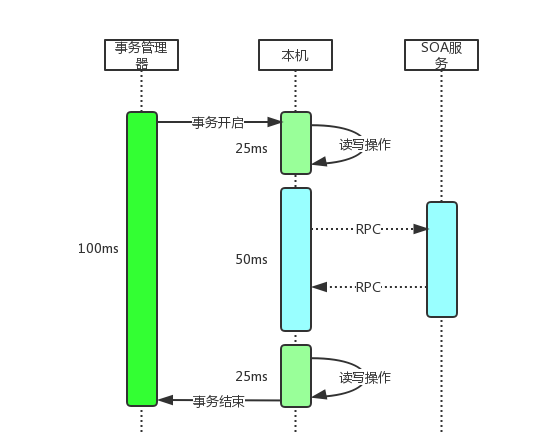
在JDBC的事务中,事务管理器在事务周期内会独占一个connection,直到事务结束。
假设我们的一个方法执行100ms,前后各有25ms读写操作,中间向其他SOA服务器做了一次RPC,耗时50ms,这就意味着中间50ms时connection将处于挂起状态。
前面已经谈到了当前性能的瓶颈在于数据库,因此这种大事务等于将数据库链接浪费一半,所以我们没有使用事务,而是通过以下两种方式保证数据的一致性。
-
乐观锁:在update时使用版本号的方式保证数据唯一性,比如在用户中奖后减少已有奖品数量。
update award set award_num=award_num-1 where id=#{id} and version=#{version} and award_num>0
-
唯一索引:在insert时通过唯一索引保证只插入一条数据,比如建立奖品ID和用户ID的唯一索引,防止insert时插入多条中奖记录。
4. 数据库及硬件
再往下就是基础层了,包括我们的数据库和更底层的硬件,之所以单独列一节,是为了聊聊我们踩的一个坑。
当时为了应对高并发的场景,我们花了数周重构,从前台服务器到后台业务逻辑用上了各种优化手段,自认为扛住每分钟几十万流量不成问题,但这都是纸上谈兵,我们需要拿数据证明,因此用JMeter做了压测。





