1. 扑克牌54张,平均分成2份,求这2份都有2张A的概率。
2. 男生点击率增加,女生点击率增加,总体为何减少?
-
因为男女的点击率可能有较大差异,同时低点击率群体的占比增大。
-
如原来男性20人,点击1人;女性100人,点击99人,总点击率100/120。
-
现在男性100人,点击6人;女性20人,点击20人,总点击率26/120。
-
即那个段子“A系中智商最低的人去读B,同时提高了A系和B系的平均智商。”
3. 参数估计
4. 假设检验
-
参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,但推断的角度不同。
-
参数估计讨论的是用样本估计总体参数的方法,总体参数μ在估计前是未知的。
-
而在假设检验中,则是先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立。
5. 置信度、置信区间
-
置信区间是我们所计算出的变量存在的范围,
水平就是我们对于这个数值存在于我们计算出的这个范围的可信程度。
-
举例来讲,有95%的把握,真正的数值在我们所计算的范围里。
-
在这里,95%是置信水平,而计算出的范围,就是置信区间。
-
如果置信度为95%, 则抽取100个样本来估计总体的均值,由100个样本所构造的100个区间中,约有95个区间包含总体均值。
6. 协方差与相关系数的区别和联系
7. 中心极限定理
(1)任何一个样本的平均值将会约等于其所在总体的平均值。
(2)不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的平均值周围,并且呈正态分布。
(1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体。
(2)根据总体的平均值和标准差,判断某个样本是否属于总体。
8. p值的含义。
基本原理只有3个:1、一个命题只能证伪,不能证明为真 2、在一次观测中,小概率事件不可能发生 3、在一次观测中,如果小概率事件发生了,那就是假设命题为假
证明逻辑就是:我要证明命题为真->证明该命题的否命题为假->在否命题的假设下,观察到小概率事件发生了->否命题被推翻->原命题为真->搞定。
结合这个例子来看:证明A是合格的投手→证明“A不是合格投手”的命题为假
→
观察到一个事件(比如A连续10次投中10环),而这个事件在“A不是合格投手”的假设下,概率为p,
小于0.05->小概率事件发生,否命题被推翻。
可以看到p越小→这个事件越是小概率事件→否命题越可能被推翻→原命题越可信
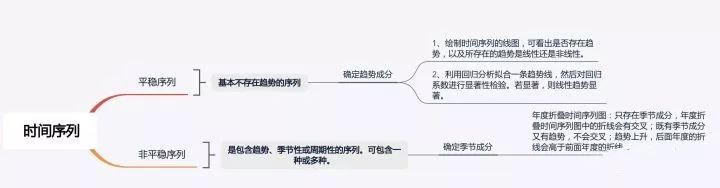
9.时间序列分析
是同一现象在不同时间上的相继观察值排列而成的序列。
10.怎么向小孩子解释正态分布
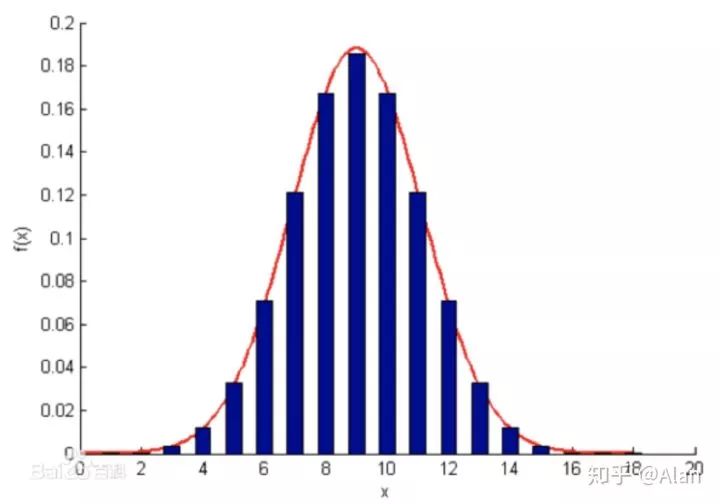
(随口追问了一句小孩子的智力水平,面试官说七八岁,能数数)
拿出小朋友班级的成绩表,每隔2分统计一下人数(因为小学一年级大家成绩很接近),画出钟形。然后说这就是正态分布,大多数的人都集中在中间,只有少数特别好和不够好
拿出隔壁班的成绩表,让小朋友自己画画看,发现也是这样的现象,
然后拿出班级的身高表,发现也是这个样子的
大部分人之间是没有太大差别的,只有少数人特别好和不够好,这是生活里普遍看到的现象,这就是正态分布
11. 下面对于“预测变量间可能存在较严重的多重共线性”的论述中错误的是?
A. 回归系数的符号与专家经验知识不符(对)
B. 方差膨胀因子(VIF)<5(错,大于10认为有严重多重共线性)
C. 其中两个预测变量的相关系数>=0.85(对)
D. 变量重要性与专家经验严重违背(对)
12. PCA为什么要中心化?PCA的主成分是什么?
因为要算协方差。
单纯的线性变换只是产生了倍数缩放,无法消除量纲对协方差的影响,而协方差是为了让投影后方差最大。
在统计学中,主成分分析(PCA)是一种简化数据集的技术。它是一个线性变换。
这个变换把数据变换到一个新的坐标系统中,
使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。
主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。
主成分分析的原理是设法将原来变量重新组合成一组新的相互无关的几个综合变量
,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。
通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Va(rF1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。
如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,
为了有效地反映原来信息,F1已有的信息就不需要再出现再F2中,用数学语言表达就是要求Cov(F1,F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分。
13. 极大似然估计
利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
1. 不用任何公开参考资料,估算今年新生儿出生数量。
采用两层模型(人群画像x人群转化):新生儿出生数=Σ各年龄层育龄女性数量*各年龄层生育比率
(一般面试中采用这种方法,即费米估计问题,可以参考《这也能想到?——巧妙解答无厘头问题》)
从数字到数字:
如果有前几年新生儿出生数量数据,建立时间序列模型(需要考虑到二胎放开的突变事件)进行预测
找先兆指标,如婴儿类用品的新增活跃用户数量X表示新生儿家庭用户。Xn/新生儿n为该年新生儿家庭用户的转化率,如X2007/新生儿2007为2007年新生儿家庭用户的转化率。该转化率会随平台发展而发展,可以根据往年数量推出今年的大致转化率,并根据今年新增新生儿家庭用户数量推出今年估计的新生儿数量。
2. 如果次日用户留存率下降了 5%该怎么分析?
a:内部因素分为获客(渠道质量低、活动获取非目标用户)、满足需求(新功能改动引发某类用户不满)、提活手段(签到等提活手段没达成目标、产品自然使用周期低导致上次获得的大量用户短期内不需要再使用等);
b:外部因素采用PEST分析(宏观经济环境分析),政治(政策影响)、经济(短期内主要是竞争环境,如对竞争对手的活动)、社会(舆论压力、用户生活方式变化、消费心理变化、价值观变化等偏好变化)、技术(创新解决方案的出现、分销渠道变化等)。
3. 卖玉米如何提高收益?价格提高多少才能获取最大收益?
提高单位溢价的方法:
(1)品牌打造获得长期溢价,但缺陷是需要大量前期营销投入;
(2)加工商品占据价值链更多环节,如熟玉米、玉米汁、玉米蛋白粉;重定位商品,如礼品化等;
(3)价格歧视,根据价格敏感度对不同用户采用不同定价。
销售量=流量x转化率,
上述提高单位溢价的方法可能对流量产生影响,也可能对转化率产生影响。
4. 类比到头条的收益,头条放多少广告可以获得最大收益,不需要真的计算,只要有个思路就行。
5. APP激活量的来源渠道很多,怎样对来源渠道变化大的进行预警?
6. 用户刚进来APP的时候会选择属性,怎样在保证有完整用户信息的同时让用户流失减少?
技术接受模型提出了两个主要的决定因素:
①感知的有用性(perceived usefulness),反映一个人认为使用一个具体的系统对他工作业绩提高的程度;
②感知的易用性(perceived ease of use),反映一个人认为容易使用一个具体的系统的程度。
(1)感知有用性:
a. 文案告知用户选择属性能给用户带来的好处
(2)感知易用性:
a. 关联用户第三方账号(如微博),
可以冷启动阶段匹配用户更有可能选择的属性,推荐用户选择。
(3)使用者态度:用户对填写信息的态度
a. 这里需要允许用户跳过,后续再提醒用户填写
b. 告知用户填写的信息会受到很好的保护
(4)行为意图:用户使用APP的目的性,难以控制
(5)外部变量:如操作时间、操作环境等,这里难以控制
7. 如何识别作弊用户(爬虫程序, 或者渠道伪造的假用户)
分类问题可以用机器学习的方法去解决,下面是我目前想到的特征:
(1)渠道特征:渠道、渠道次日留存率、渠道流量以及各种比率特征
(2)环境特征:设备(一般伪造假用户的工作坊以低端机为主)、系统(刷量工作坊一般系统更新较慢)、wifi使用情况、使用时间、来源地区、ip是否进过黑名单
(3)用户行为特征:访问时长、访问页面、使用间隔、次日留存、活跃时间、页面跳转行为(假用户的行为要么过于一致,要么过于随机)、页面使用行为
(正常用户对图片的点击也是有分布的,假用户的行为容易过于随机)
(4)异常特征:设备号异常(频繁重置idfa)、ip异常(异地访问)、行为异常(突然大量点击广告、点赞)、数据包不完整等
8. 怎么做恶意刷单检测?
分类问题用机器学习方法建模解决,我想到的特征有:
-
商家特征:商家历史销量、信用、产品类别、发货快递公司等
-
用户行为特征:用户信用、下单量、转化率、下单路径、浏览店铺行为、支付账号
-
环境特征(主要是避免机器刷单):
地区、ip、手机型号等
-
异常检测:
ip地址经常变动、经常清空cookie信息、账号近期交易成功率上升等
-
评论文本检测:
刷单的评论文本可能套路较为一致,计算与已标注评论文本的相似度作为特征
-
图片相似度检测:
同理,刷单可能重复利用图片进行评论
9. 一个网站销售额变低,你从哪几个方面去考量?
10. 用户流失的分析,新用户流失和老用户流失有什么不同?
(1)用户流失分析: