(点击上方蓝字,快速关注我们)
来源:JackieFang
segmentfault.com/a/1190000010800119
如有好文章投稿,请点击 → 这里了解详情
在Keras环境下构建多层感知器模型,对数字图像进行精确识别。
模型不消耗大量计算资源,使用了cpu版本的keras,以Tensorflow 作为backended,在ipython交互环境jupyter notebook中进行编写。
1.数据来源
在Yann LeCun的博客页面上下载开源的mnist数据库:
http://yann.lecun.com/exdb/mnist/
此数据库包含四部分:训练数据集、训练数据集标签、测试数据集、测试数据集标签。由于训练模型为有监督类型的判别模型,因此标签必不可少。若使用该数据集做k-means聚类,则不需要使用标签。将数据整合之后放入user\.keras\datasets文件夹以供调用。
也可以直接从keras建议的url直接下载:https://s3.amazonaws.com/img-datasets/mnist.npz
其中训练数据集包含了60000张手写数字的图片和这些图片分别对应的标签;测试数据集包含了10000张手写数字的图片和这些图片分别对应的标签.


2.数据格式和前期处理(在此不涉及)
训练数据集包含60000张图片,测试数据集包含10000张,所有图片都被当量化为28pixel*28pixel的大小。为减少向量长度,将图片灰度处理,每个像素用一个RGB值表示(0~255),这是因为灰度处理后的RGB值加了归一约束,向量长度相是灰度处理前的1/3。至此,每个图片都可以用28*28的向量表示。
3.导入依赖库
打开jupyter notebook后导入依赖库numpy,此处的seed为随机量的标签,可随意设置:
from __future__ import print_function
import numpy as np
np.random.seed(9999)
继续从keras中导入使用到的模块:
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD, Adam, RMSprop
from keras.utils import np_utils
mnist为之前准备的数据集,Dense为全连接神经元层,Dropout为神经元输入的断接率,Activation为神经元层的激励函数设置。
导入绘图工具,以便之后绘制模型简化图:
from keras.utils.vis_utils import plot_model as plot
4.处理导入的数据集
处理数据集
为了符合神经网络对输入数据的要求,原本为60000*28*28shape的三维ndarray,改变成了尺寸为60000*784的2维数组,每行为一个example,每一列为一个feature。
神经网络用到大量线性与求导运算,将输入的feature的数值类型改变为32位float。
将feature值归一化,原本0~255的feature归一为0~1。
测试数据集同理。
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 28*28)
X_test = X_test.reshape(10000, 28*28)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
处理标签
文本识别问题本质是一个多元分类问题。将类向量转换为二进制数表示的类矩阵,其中每一行都是每一个example对应一个label。label为10维向量,每一位代表了此label对应的example属于特定类(0~10)的概率。此时Y_train为60000*10的向量,Y_test为10000*10的向量
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
5.用keras建立神经网络模型
batch_size = 128
nb_classes = 10
nb_epoch = 20
model = Sequential()
model.add(Dense(500, input_shape=(28*28,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(500))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(500))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
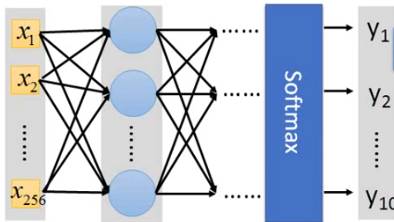
三层的神经网络,其中输入层为28*28=784维的全连接层。
Hidden Layer有3层,每一层有500个神经元,input layer->hidden layer->output layer都是全连接方式(DENSE)。
hidden layer的激活函数采用ReLu函数,表达式:
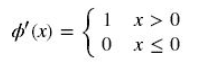
如下图所示:
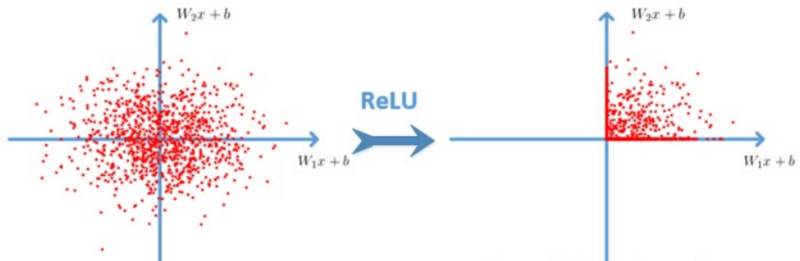
相比与传统的sigmoid函数,ReLU更容易学习优化。因为其分段线性性质,导致其前传、后传、求导都是分段线性。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢弃信息。且Relu在x
文本识别本质是多元分类(此处为10元分类),因此输出层采用softmax函数进行feature处理,如下图所示:
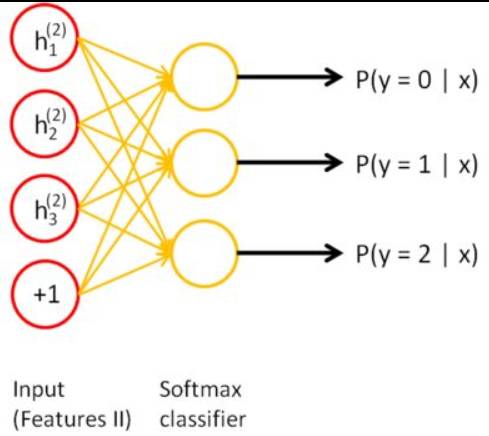
其中第j个输出层神经元输出值与当层输入feature的关系为:
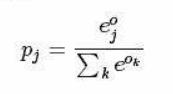
该神经网络示意图如图所示:
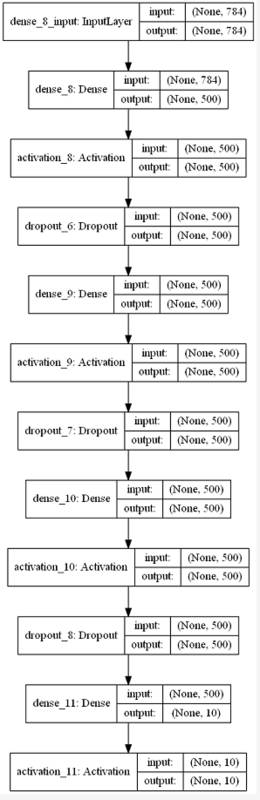
调用summary方法做一个总览:
model.summary()
结果如下:

该神经网络一共有898510个参数,即在后向反馈过程中,每一次用梯度下降都要求898510次导数。
用plot函数打印model:
plot(model, to_file='mlp_model.png',show_shapes=True)
如下图所示:
编译模型,使用cross_entropy交叉熵函数作为loss function,公式如下图所示:
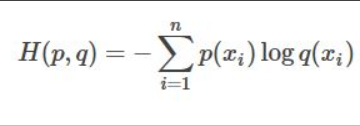
用交叉熵可量化输出向量与标签向量的差异,p与q分别为输出向量与标签向量。对于每一个example,其交叉熵值就是要通过迭代尽量往小优化的值。优过程使用梯度算法,计算过程中使用反向传播算法求导。
交叉熵的作用如下图所示:
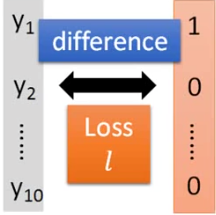
在此分类神经网络中,使用判别结果的accuracy作为参数值好坏的度量标准。
6.用数据训练和测试网络
history = model.fit(X_train, Y_train,
batch_size=batch_size, nb_epoch=nb_epoch,
verbose=1, validation_data=(X_test, Y_test))
在这个地方运行碰到warning,原因是最新版的keras使用的iteration参数名改成了epoch,而非之前沿用的nb_epoch。将上面的代码作修改即可。
训练结果如下所示。第一次迭代,通过对60000/128个的batch训练,已经达到了比较好的结果,accuracy已经高达0.957。之后Loss值继续下降,精确度继续上升。从第9个itearation开始,loss函数值(交叉熵cross_entropy)开始震荡在0.05附近,accuracy保持在0.98以上。说明前9次迭代就已经训练了足够好的θ值和bias,不需要后11次训练。
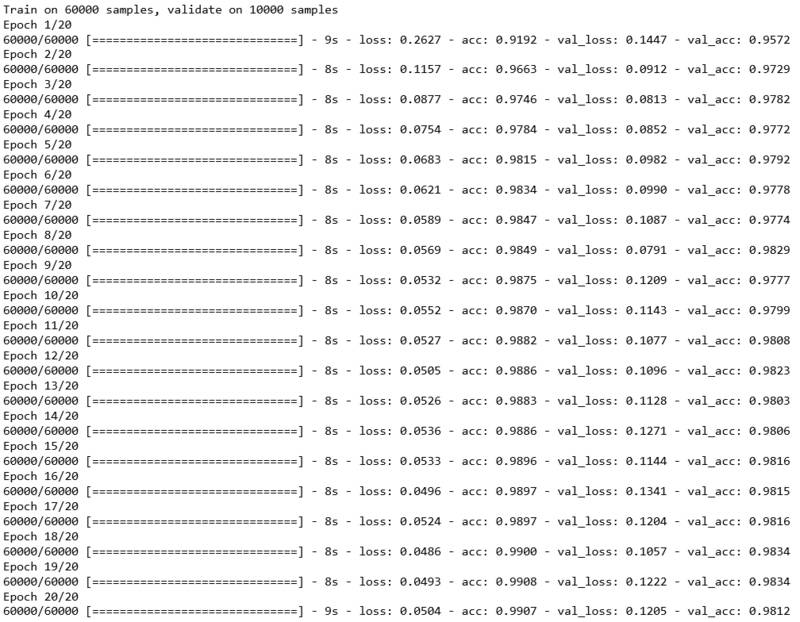
7.评估模型
用score函数打印模型评估结果:
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
输出结果如下图所示:
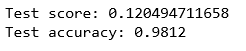
训练的multi-layer_perceptron神经网络在对数字文本识别时具有98.12%的准确率。
手写数字图片数据库和Iris_Flower_dataset一样,算是dl界的基本素材,可以拿来做很多事情,比如k-means聚类,LSTM(长短记忆网络)。
看完本文有收获?请转发分享给更多人
关注「大数据与机器学习文摘」,成为Top 1%











