
大数据文摘出品
编译:王一丁、蒋宝尚
人工智能领域的迅速发展,相关人才不能满足需求已经成为业界共识。有报道称,因为人工智能工程师庞大的缺口,一些公司为了获得人才不得不支付数百万美元的薪水。如何满足对人工智能工程师不断增长的招聘和培训的需求,英特尔人工智能事业部副总裁兼架构总经理Gadi Singer及英特尔人工智能人才招聘主管Chris Rice发表了他们的看法。
Rice说:“新闻报道中所呈现情况基本上是事实。”一个有趣的事是:
人工智能不再仅仅在科技公司发挥作用,在金融、医疗、零售、移动、制造业等行业中都开始招募人工智能工程师,不仅是开发方面的人才,应用技术方面的人才也非常抢手。因此,全球范围内对人工智能工程师需求不断的增加,推动他们身价的增值。
“2016年深度学习的最先进技术在2018年被称为'遗产'”
—Gadi Singer
虽然相关领域一片火热,Singer也说:“
要知道AI不是一种技能,而是一种对于工作的描述,这是一套多样化的技能。为了实现目标,你得有硬件架构师,还有设计师,软件开发人员,数据科学家和研究人员。
”

鉴于人工智能中最热门的领域是深度学习,包含所有与神经网络相关的技术,Singer认为,最具价值一直是那些了解如何开发新技术以及可以灵活运用其专业知识的人才。
据Singer说,
推动价值增长的另一个原因是,“这个领域的前沿知识的更新要比我见过的任何领域的都要快。2016年深度学习的最先进技术在2018年被称为‘遗产’。因此,那些有能力不断学习并且始终在这个快速发展时代中保持领先的人才显然具有非常大的价值。
”
“这有几个问题,”Rice说。“全球学术机构在这一技能领域方面已经开始做得很好。但是由于快速的创新周期,很多研究实际上是在工业中进行的,所以行业实际上是从学术界招聘了很多教授。这是一个令人困惑的问题:工业界正在努力以更快的速度吸引越来越多的人离开学术界。”
“过去数据科学被认为是沉闷的......但今天,数据科学真的很酷”
—Gadi Singer
积极的方面是,Singer说他看到相关领域的课程与学生数量都在增长。
Singer说:“过去,数据科学及统计学的一些领域被认为是枯燥乏味的。但如今,数据科学真的很酷。这也吸引了众多学者涌入工业界。”
Singer表示,“所以,即使目前人才需求很大,行业本身吸引力也会在学术界和更大的人口中转化为驱动力,从而增加从业人员的数量。”

Rice说,“
在数据科学领域,人们平均每21个月就会换工作,有更高的跳槽率的原因不是因为人们只是想换工作,而是因为他们尝试着解决多样化的问题。他们从一个地方到另一个地方去研究新的和有趣的问题。
”他说,结果是公司很难找到留住他们的方法。Rice认为当一个人进入一个组织时,公司负责人必须更加积极地构建职位升迁路径。
工程师们想要感受到“他们做的事不仅仅是坐在工位上敲代码,而是做出可以对社会有更多影响的“家伙”
—Chris Rice
道理很朴素,但却很真实,Singer说:“让工作成为一种有趣的体验。
因此,对于许多顶尖人才来说,最重要的因素不是谈论工资待遇,而是他们是否觉得自己正在做一些处于技术前沿的事情?他们是否觉得有所获益?以及,他们所做的工作很重要吗?”
今天的顶级工程师想要做的不仅仅是坐在一个小隔间里一行一行的打代码。相反,他们希望做更多有助于社会进步的事情。
训练机器学习的方式影响着“机器”看待世界的方式,通过基于样本的监督学习,所使用的样本会影响其分析方式。处理防止偏见的最佳方法是拥有多元化的团队。当团队具有多样性,并从多个角度审视问题时,就会创造具有全面视野的解决方案。
从长远来看,未来复杂人工智能系统的偏见是什么,如何发现它,以及如何避免它。“对于今天的技术而言,这不是可以做到的,但从长远来看,我看到这种能力在不断发展,”
Singer
说。

关于,为什么今天的孩子应该考虑以人工智能为作为行业选择,Singer说,“人工智能具有高度影响力和多学科的优势”。这意味着它可以支持各种各样的兴趣:“无论你是想在互动的人性方面做得更多,还是更多的统计数据,或者更多地去编程;每个选择都对应人工智能的一个分支。所以,将来很难有哪个职业不涉及人工智能。”
相关报道:
https://spectrum.ieee.org/view-from-the-valley/robotics/artificial-intelligence/intel-execs-address-the-ai-talent-shortage-ai-education-and-the-cool-factor
本文为 AI 研习社编译的技术博客,原标题 The Artificial Intelligence dictionary for beginners,作者为
Heuritech
。
翻译 | nick李、Reidw 整理 | 凡江
在人工智能的领域下,有许多经常被公众所错误理解并且误用的概念。
本术语词典的主要目的是用一种简单精确的方式来解释人工智能的术语。
我们欢迎你的反馈,请联系[email protected]。那么现在让我们开始!
A
人工智能(AI)
从这个开始可能显得有点复杂,因为关于人工智能没有一个一致的定义。我们咨询了我们的R&D团队,他们也激烈地辩论了很久。这是他们讨论出的结果:
算法(Algorithm)
算法是指一串能够完成某个既定目标的简单指令序列。让我们看一个比较接地气的例子:每天早上穿衣服(因为每个人都会穿衣服啊)。穿衣服时你会遵循一个严格的流程:首先穿内衣,然后穿衣服,最后才穿鞋。这就是算法所做的工作:遵循指令来回答一个问题。
属性(Attribute)
某个对象(object)的特征:它可以是从颜色到纹理、形状的任何东西。例如,下图中Jeanne Damas穿了什么?你可以在图旁边找到她的穿着的所有属性。
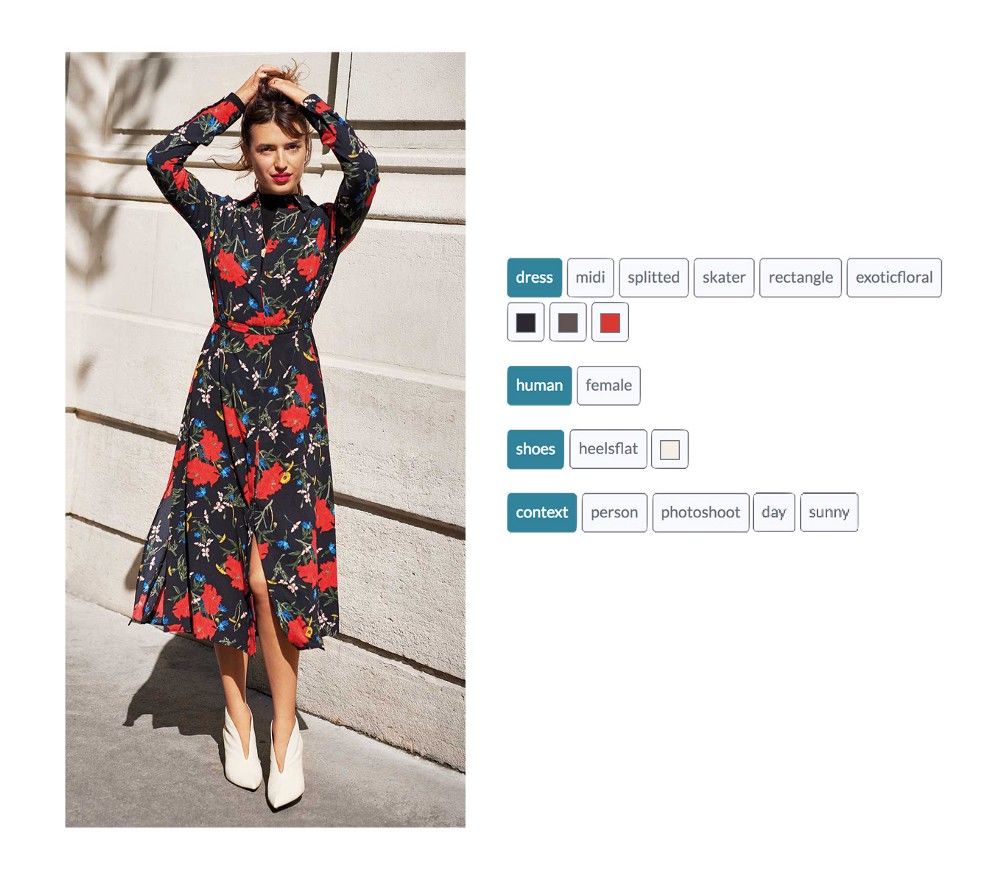
根据Heuritech的模型,Jeanne Damas穿着一条有异国鲜花图案的半开叉
C
分类(Classification)
分类是指将零散的数据组织成类。在Heuritech的案例中,这些零散的数据就是图片,而类别就是不同的服饰(例如背包,鞋子,裙子和裤子)。数据科学家需要有标记的数据以训练分类模型。
聚类(Clustering)
聚类模型自主地将有相似特征的图片归为一组。有趣的是,这些模型不需要训练就可以对图片进行聚类。

一个聚类的实例
计算机视觉(Computer Vision)
计算机视觉是一个人工智能的分支,它着重于图片与视频,又称为视觉识别*
D
识别(Detection)
识别模型能够对图像中的一个或多个物体进行定位并分类。为了可视化表示识别模型的输出,长方形(也称包围盒)被画在识别出的物体周围。

数据集(Data set)
是指一个整理在一起的数据列表,可以被用来训练模型或评估一个模型的效果。在我们的案例中,数据集由图像组成,其中大部分都是和时尚有关。更多的解释,详见标记数据(labelled data)*。
深度学习(Deep Learning; 机器学习的一个分支)
深度学习是机器学习*的一个子领域,它的出现使得近十年的人工智能*发生了剧变。
视觉识别*尤其收益于深度学习。深度学习让识别、检测并且分割图像中的物体成为可能,并且具有较好的表现。一个深度学习模型学习去识别对人类有意义的概念,例如风景、手包、笑脸等。
为了完成这些任务,深度学习模型找到最重要的基础轮廓和形状,并且将它们结合在一起组成复杂的模式,而这些模式又将组合起来形成更复杂的模式,以此类推。在这个多层的过程最后,模型能够对它训练过的类别进行预测。
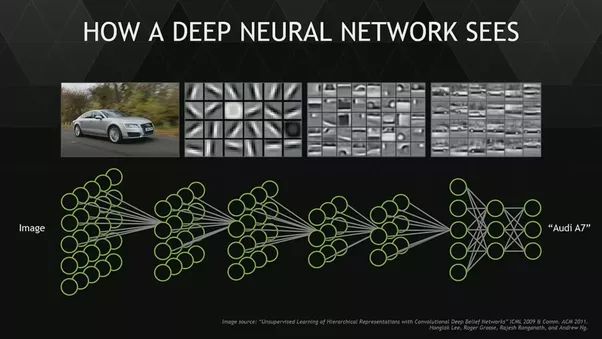
来源:Analytics Vidhya
G
泛化(Generalization)
指的是一个机器学习算法能在它从未见过的图像也表现良好的能力。如果模型在一个具有1000个图像的数据集上训练,它能否在每个其他图像上都具有较好的表现呢?
H
启发式(Heuristic)
指的是进行发现的科学艺术。它来自于希腊词"eurisko"(我相信),并引申到"Eureka"(我找到)。这个词汇由阿基米德在洗澡时发现Pi的概念而推广。启发式方法包括排除其他方法来获得一个可用的解决方式以此来推动进展。
Heuritech
有两个名字组成:启发式和科技。有25位团队大脑组成,Heuritech作为一个初创公司的使命是建立消费行业最好的视觉识别系统。通过独特地应用顶尖水平的技术于数百万计的Instagram图片,我们能够对商品和趋势进行监控。这要感谢由35%的人工智能PhD组成的Heuritech团队持续5年的研究与开发。
L
标签数据(Labelled data)
机器学习*模型*的目标是根据一个输入预测正确的输出。例如,我们在Heuritech所使用的某些模型能够根据一个图像(输入)来预测具体的手包类别(输出)。这些模型在有标签的数据上训练,比如,一些有标签的图片。
训练一个模型是耗费巨大的,一部分是因为它需要数以千计的标签数据,而这些数据通常需要人工来逐一标记。在Heritech的例子中,标签数据主要是一些标记好时尚方面属性的图像。
M
机器学习(Machine Learning)
首先,人工智能技术研究的是如何通过程序来自动完成那些通常需要人工处理的任务。实现它的一种方式就是使用机器学习模型,这些模型可以在打好标签的数据中自主学习特征。举个栗子,如果你想使用机器学习模型来自动识别照片中的裙子的种类,就需要将成百上千的带有种类标签的裙子照片输入模型进行训练,直到模型能够正确识别照片中那些训练集中不包含的裙子种类为止(详见泛化能力一章)。
模型(Model)
一个数学模型就是通过方程来理解世界的一种方式。但是,组成现实世界的数据种类是非常有限的,我们可以使用模型来读取这些数据(比如图像、声音、文本、股价......)。
给定一个输入,训练模型来得到一个合适的输出。在下面的例子中,输入就是这张图像,输出的就是局部物品的种类。例如手提袋。
在机器学习领域,所有的模型都是针对某一具体领域中的数据进行训练的。
Heuritech公司的模型:
输入:来自Instagram的一张照片
输出:图中的手提包
N
神经网络(Neural network)
想象一下,大脑中有一个庞大的神经网络,它由数以百万计的神经元组成,它们通过层级运算实现决策。这就像我们实际思考时,我们的大脑的工作方式一样。
自然语言处理(NLP)
人工智能领域的一个分支主要把文本作为研究对象。技术的名字就做出了明确的解释:让机器处理自然(人类)语言。例如,这就是为何垃圾邮件会出现在邮箱的垃圾箱中:因为你的电子邮件使用了训练过的自然语言处理系统来识别和筛选垃圾邮件。
P
模式(Pattern)
数据*中自我重复的结构。模型*能够自动地学习如何提取、识别并描述模式。
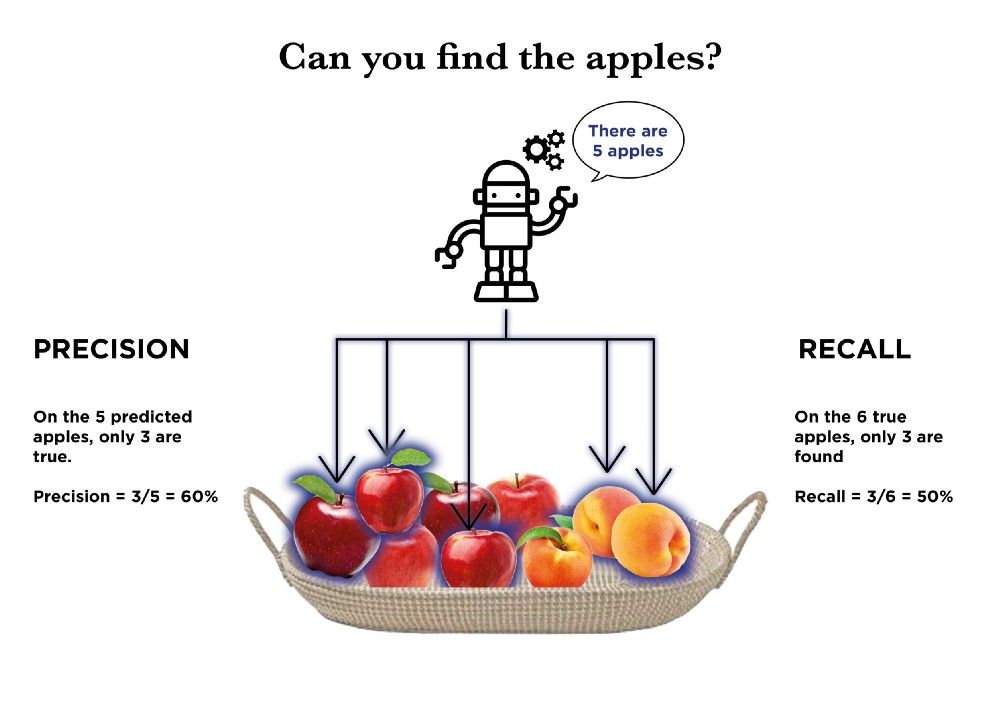
准确率&召回率(Precision&Recall)
准确率和召回率是用以评测一个模型*表现好坏的度量标准。
准确率:在你的模型预测出的所有结果中,正确结果的百分比。
召回率:在你的模型试图找出的类别(数据集中)里,被模型成功找出的百分比。
让我们看个更具体的例子。
如下是一个有6个苹果和3个桃子的篮子。我们需要模型找出所有苹果。这个表现不是很好的模型,挑出了5个苹果。但实际上这是3个苹果和2个桃子。
S
分割(Segmentation)
图像分割可以自动地将图像中物体的轮廓描画出来。分割在实际中有许多使用,例如色彩提取和衣物识别。
在下图这个gif中,你能看到包围盒(物体周围的长方形)和图像分割(物体本身的轮廓图)。这些都是由机器学习*模型*自动生成的。

来源: Mask-RCNN 在4K视频中的开源应用,由Karol Majek开发。
T
标记(Tagging)
标记之于人工智能*如同主题标签之于Instagram。每一个图像都可以被打上标记,例如,#T恤,#红色,#短款等。
另见:分类
V
视觉识别(又称作计算机视觉;Visual Recognition)
人工智能*的一个分支着重于图像,因此也被称为视觉+识别。一个模型经过训练,可以识别出图片中的具体物体:例如在Heuritech的例子中,就是对衣物进行识别。
我们由衷希望你喜欢这个人工智能术语词典。
衷心欢迎你的反馈,也欢迎提出新的术语定义,详情联系[email protected]
这个术语词典会定期更新。如果你希望收到最新的消息,请订阅我们关于人工智能与时尚的简讯。
原文链接:








