
如果说印度尼西亚的首都容易洪水泛滥,这种描述其实过于轻描淡写。雅加达40%以上的海拔处于或低于海平面。再加上当地人口快速增长已超过1000万,这使得易发多发的灾难已经司空见惯。于是提高城市居民的抗洪能力成为当务之急。面对灾难的应变能力是一种会影响个体有效自我组织的能力,这需要基于准确、可行、实时的信息进行及时决策。但在灾难发生时,雅加达充斥着大量信息。事实上,印度尼西亚首都是世界上Twitter最活跃的城市。
本文为36大数据专稿

因此,纵然有关不断上升的洪水水位的相关信息可能以某种方式从数百万条Twitter中实时收集,这些报告也可能是不准确或完全错误、南辕北辙的。
此外,平均只有3%的推文是带有定位的地理位置信息的,这意味着任何通过Twitter报道的洪水泛滥的可靠性证据其实都是不可行的——更确切地说,除非当地居民和回应者知道洪水在哪个区域上升,否则他们不可能及时采取战术行动。
这些巨大的挑战解释了为什么大多数社会媒体对灾难响应的价值被大打折扣了。
但雅加达的数字人道主义者并不是普通的平均数字人道主义者。最近这些数字信奉者推出了一种人道主义科技行动,这在我多年看来是最具希望的行动之一。该项目名为“Peta Jakarta”,该项目将社交媒体和数字人道主义行动提高到了一个新的水平。
每当有人在推特上发布带有“banjir”(洪水)关键词的消息时,用户就会收到一条来自@petajkt的推特自动回复消息,邀请对方确认他们是否在自己所处区域看到了洪水的迹象:“洪水?
启用地理位置定位,在推特上@petajkt #banjir,并检查petajakarta.org。“用户可以通过启用定位来确认他们的报告,并简单地回复关键词banjir或洪水。这个结果随后就被添加到一个实时的公共危机地图中,如下图所示。
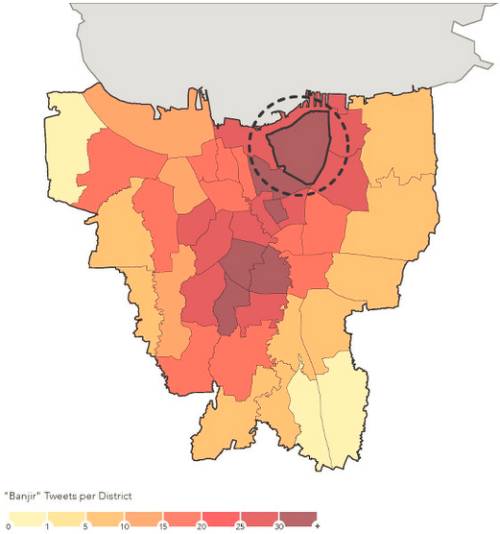
在2014/2015年印度洋季风季节期间,Peta Jakarta自动向雅加达市民发送了8,9000条推文,呼吁市民采取行动确认洪水状况。这些自动邀请推文用于向用户介绍关于这个项目的相关信息,并链接到下面的视频(通过Twitter Cards),以提供关于如何提交一份大致洪水等级的确认报告的简单说明。如果一个Twitter用户忘记打开他们智能手机的定位功能,他们会收到一条自动发送的推文,提醒他们启用地理位置获取并重新提交其推文。
最后,该平台“生成一条感谢消息,确认收到用户的报告,并将其引导至PetaJakarta.org去查看他们对地图的贡献。
”请注意,“发送程序化消息的总体目标不是简单地征求大量回复,而是通过共享重要数据,让积极忠诚的市民用户自愿参与到公民共同管理中来,
以此来帮助其他用户和政府机构在灾难到来时做出决策。”
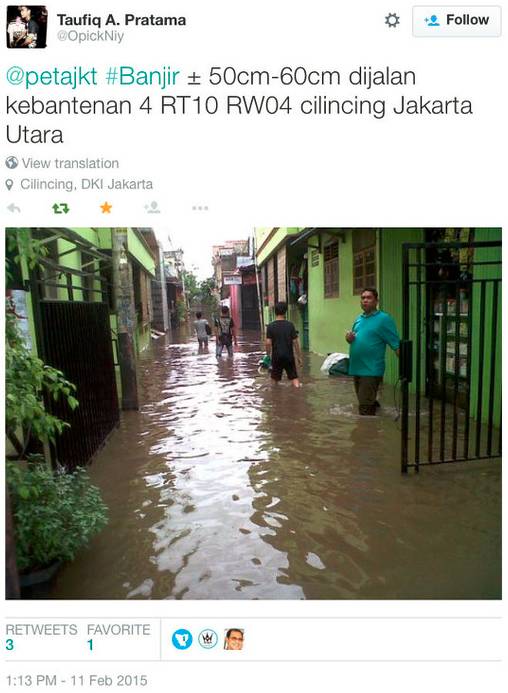
如下图中的推文所示,当一条推文既包含了洪水的图片又确认标记了地理位置时,这份报告就可被视为是经过验证的。这些经过确认和验证的推文会被自动映射,并与雅加达的应急管理机构(BPBD DKI Jakarta)共享。
后者直接参与了这一行动,因为他们“经常面临预测和应对雅加达洪水灾害和相关极端天气事件的艰巨挑战”。
这种直接的伙伴关系还可以限制“数据滥用综合征”,即数据虽被收集但并未被利用的情况。请注意,Peta Jakarta可以通过对来自同一地区的其他Twitter报告进行交叉检查,并通过监控“电视和互联网新闻网站,追踪洪水泛滥地区并交叉核查报告”,以手动评估推文和图片的有效性。
在最近一次季风季节中,Peta Jakarta“收到并绘制了1119份确认的洪水报告。
这些报告由877名用户组成,平均每个用户1.27条twitter。另外虽然还收到了2091份经过确认的报告,但因为其中缺少必要的地理位置元数据不能进行标记,这充分显示出了发送程序化的获取地理位置“提醒消息”的价值。
在整个季风过程中,Peta Jakarta还记录并绘制了25584份未经证实的报道。”
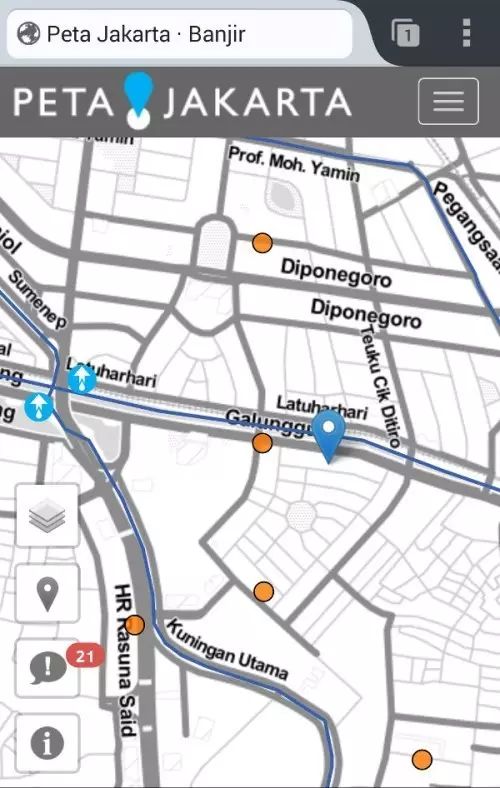
根据最终用户不同,“实时危机地图”可以通过两个不同的接口进行查看。对于当地居民来说,可以通过智能手机访问地图,其视觉显示器是专门为更多的战术决策而设计的,依地区水平分类显示洪水报告,
并且只显示过去一小时内的洪水情况。
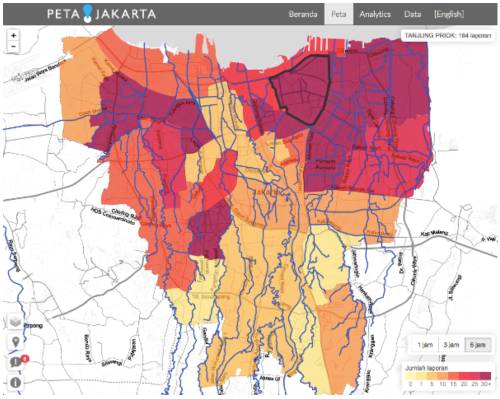
为机构合作伙伴提供的接口,数据则更全面地进行了可视化,以辅助基于趋势分析和数据整合进行战略决策。
“当你在台式电脑上浏览地图时,网页应用会按比例缩放地图来显示整个城市的情况。”
Peta Jakarta已经“证明了社交媒体作为一种大城市方法论的价值和实用性,它可以应用于众包相关情境信息,以辅助在极端天气事件中做出决策和响应协调。
”这项举措使“自主的用户能够实时基于安全和导航对洪水做出独立决策,从而帮助提高城市居民的抗洪能力和随之而来的困难。”此外,通过“在城市中不同参与者所需的各种空间和时间尺度上给予决策支持,Peta Jakarta为在灾情来临时众包具有严格时间要求的情景信息提供了一种创新又廉价的方法。
”经BPBD DKI Jakarta使用的确认和验证的推文被 “来自传统数据源的洪水正规报道进行交叉验证,以支持实时的洪水评估、响应和管理信息的创建。”
我的博客文章是基于我与Peta Jakarta团队的几次对话,以及一周前刚刚发表的这篇白皮书。这份报告的篇幅接近100页,对于所有数字人道主义者和批评人士来说,绝对应该被视为必读书目。这篇论文包含了几十个观点,远非一篇短小的博客文章所能说清道明的。如果你找不到阅读报告的时间,请参阅下面的关键摘录。
-
从社交媒体的“噪音”中提取知识,这需要设计参与和过滤过程,以消除不需要的信息,奖励有价值的报告,并显示有用的数据,从而使用户、政府或其他机构能够以一种注重时效性的方式做出有意义的、可执行的决策。
-
虽然被动挖掘的社交媒体数据在规划的未来场景中还可以提供离线分析和衍生研究等见解
,但前线应急响应人员的关键问题是组织和协调与灾难情况有关的、可操作的实时数据。
-
Peta Jakarta项目在进行报告的过程中一直贯彻用户匿名性的原则。数据源于Twitter的洪水报告尽管属于公共内容,但其目标并不是在Twitter平台之外创建一个提交过涉及洪水事件的潜在敏感报告的用户档案。Peta Jakarta于是将报告的收集过程设计成匿名的,把报告和各自的用户分离开来
。此外,仅当报告被确认时,即当用户已经选择向@petajkt帐户发送消息来描述他们的情况时,才存储推文的文本内容。类似地,用户名在存储时采用单向哈希函数进行加密。
-
在开发Peta Jakarta品牌作为该项目的公众形象时,重要的是要确保界面和地图被呈现为社会公共所有,而不是作为政府产品或学术研究工具。为了吸引第一批用户——年轻的、精通科技的雅加达Twitter用户——在所有对外材料中使用的语言(Twitter回复、宣传视频、图片和印刷广告)都是有意表现的随意和简洁。由于季风期间多次发生洪水事件,以及围绕洪水事件周边地区持续进行的日常活动,这些消息有意被设计成更像正常的twitter闲聊,而不是公共服务公告。
-
用户与PetaJakarta.org的交互设计是非常重要的,创建用户体验,着重强调项目的社区资源元素(类似于Waze流量应用程序),紧急公告或信息服务的用户体验反倒无关紧要了。考虑到这一点,图文设计都是随意和轻量级的。在视频、自动回复和平面广告中,
PetaJakarta.org从来没有使用过耸人听闻或道德说教的语言;相反,图形界面是一种随意的、可选择的、社区参与的形式。
-
Twitter上关于@petajkt的最常见问题是如何激活推文中的地理位置功能。到目前为止,这个问题已经通过发送一条带有图片指示的回复推文来描述如何激活地理位置功能的。
-
该项目成功的关键是由官方公开发布,并由州长进行推广。这种认可和支持使该平台在其他政府机构和公共用户中获得了很高的知名度和合法性;它也成功成为了一件媒体盛事,引起了媒体的广泛报道和随后的公众关注。
-
Twitter消息的聚合(设计用于匹配雅加达灾难管理机构系统中的洪水报告的时空结构)在浏览社交媒体时仍然显示出不足,因为它可能忽略掉那些Twitter特别不活跃地区的报告。相反,该机构使用@petajkt的Twitter流来指导他们使用地图,并实时验证和互查有关受洪水影响地区的信息。
虽然社交媒体的这种使用在整体上看是具有生产力的,但联合试点研究的结果仍然提议制定一个更健壮的风险评价矩阵(REM)
,使Peta Jakarta能够为更广泛的用户群体提供服务,并通过开放的API优化数据收集过程。
-
发展一个更强大的社交媒体数据集成也意味着利用其他潜在的数据集,通过混合来增加系统的智能性;其他数据来源可能包括但不限于政府、私营部门和非政府组织的应用(“应用程序”)提供的实地数据采集,
使用激光雷达或无人机采集到的高程数据,以及安装了各种传感设备的地面控制点的传感数据。
如果其他类型的传感器及其随附的数据源与社交媒体所采集信息一致,则城市数据收集的“市民即传感器”的模式将最有效得以推进。
End
为了让大家能有更多的好文章可以阅读,36大数据联合华章图书共同推出「祈文奖励计划」,该计划将奖励每个月对大数据行业贡献(翻译or投稿)最多的用户中选出最前面的10名小伙伴,统一送出华章图书邮递最新计算机图书一本。投稿邮箱:[email protected]
点击查看:你投稿,我送书,「祈文奖励计划」活动详情>>>
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
排名前50的开源Web爬虫用于数据挖掘
33款可用来抓数据的开源爬虫软件工具
在中国我们如何收集数据?全球数据收集大教程










