背景
相信大家在项目开发中,在页面较复杂的情况下,往往会遇到一个问题,就是在页面组件之间通信会非常困难。
比如说一个商品列表和一个已添加商品列表:
假如这两个列表是独立的两个组件,它们会共享一个数据 “被选中的商品”,在
商品列表
选中一个商品,会影响
已添加商品列表
,在
已添加列表
中删除一个商品,同样会影响
商品列表
的选中状态。
它们两个是兄弟组件,在没有数据流框架的帮助下,在组件内数据有变化的时候,只能通过父组件传输数据,往往会有
onSelectedDataChange
这种函数出现,在这种情况下,还尚且能忍受,如果组件嵌套较深的话,那痛苦可以想象一下,所以才有解决数据流的各种框架的出现。
本质分析
我们知道 React 是
MVC
里的
V
,并且是数据驱动视图的,简单来说,就是
数据
=>
视图
,视图是基于数据的渲染结果:
V = f(M)
数据有更新的时候,在进入渲染之前,会先生成 Virtual DOM,前后进行对比,有变化才进行真正的渲染。
V + ΔV = f(M + ΔM)
数据驱动视图变化有两种方式,一种是
setState
,改变页面的
state
,一种是触发
props
的变化。
我们知道数据是不会自己改变,那么肯定是有“外力”去推动,往往是远程请求数据回来或者是
UI
上的交互行为,我们统称这些行为叫
action
:
ΔM = perform
(action)
每一个
action
都会去改变数据,那么视图得到的
数据(
state
)
就是所有
action
叠加起来的变更,
state = actions.reduce(reducer, initState)
所以真实的场景会出现如下或更复杂的情况:
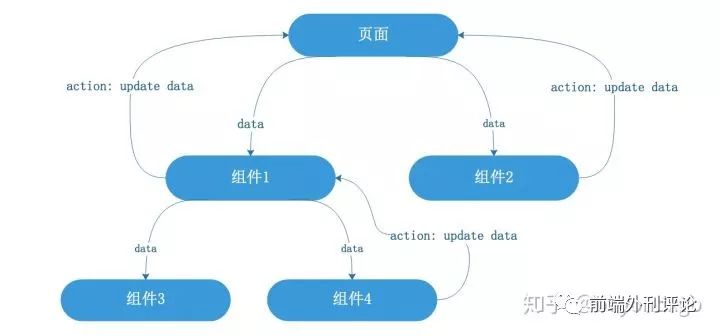
问题就出在,更新数据比较麻烦,混乱,每次要更新数据,都要一层层传递,在页面交互复杂的情况下,无法对数据进行管控。
有没有一种方式,有个集中的地方去管理数据,集中处理数据的接收,修改和分发?答案显然是有的,数据流框架就是做这个事情,熟悉
Redux
的话,就知道其实上面讲的就是
Redux
的核心理念,它和
React
的数据驱动原理是相匹配的。
数据流框架
Redux
数据流框架目前占主要地位的还是 Redux,它提供一个全局
Store
处理应用数据的接收,修改和分发。
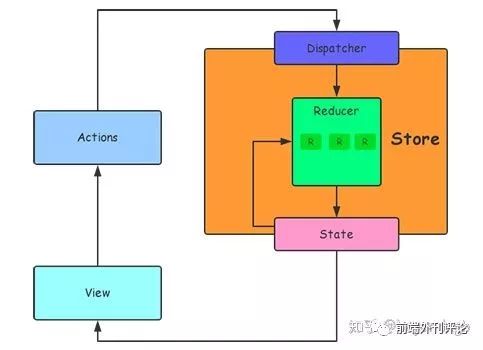
它的原理比较简单,
View
里面有任何交互行为需要改变数据,首先要发一个
action
,这个
action
被
Store
接收并交给对应的
reducer
处理,处理完后把更新后的数据传递给
View
。
Redux
不依赖于任何框架,它只是定义一种方式控制数据的流转,可以应用于任何场景。
虽然定义了一套数据流转的方式,但真正使用上会有不少问题,我个人总结主要是两个问题:
-
定义过于繁琐,文件多,容易造成思维跳跃。
-
异步流的处理没有优雅的方案。
我们来看看写一个数据请求的例子,这是非常典型的案例:
actions
.
js
export
const FETCH_DATA_START = 'FETCH_DATA_START';
export const FETCH_DATA_SUCCESS = 'FETCH_DATA_SUCCESS';
export const FETCH_DATA_ERROR = 'FETCH_DATA_ERROR';
export function fetchData() {
return dispatch => {
dispatch(fetchDataStart());
axios.get('xxx').then((data) => {
dispatch(fetchDataSuccess(data));
}).catch((error) => {
dispatch(fetchDataError(error));
});
};
}
export function fetchDataStart() {
return {
type: FETCH_DATA_START,
}
}
...FETCH_DATA_SUCCESS
...FETCH_DATA_ERROR
reducer
.
js
import { FETCH_DATA_START, FETCH_DATA_SUCCESS, FETCH_DATA_ERROR } from 'actions.js';
export default (state = { data: null }, action) => {
switch
(action.type) {
case FETCH_DATA_START:
...
case FETCH_DATA_SUCCESS:
...
case FETCH_DATA_ERROR:
...
default:
return state
}
}
view
.
js
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
import reducer from 'reducer.js';
import
{ fetchData } from 'actions.js';
const store = createStore(reducer, applyMiddleware(thunk));
store.dispatch(fetchData());
第一个问题,发一个请求,因为需要托管请求的所有状态,所以需要定义很多的
action
,这时很容易会绕晕,就算有人尝试把这些状态再封装抽象,也会充斥着一堆模板代码。有人会挑战说,虽然一开始是比较麻烦,繁琐,但对项目可维护性,扩展性都比较友好,我不太认同这样的说法,目前还算简单,真正业务逻辑复杂的情况下,会显得更恶心,效率低且阅读体验差,相信大家也写过或看过这样的代码,后面自己看回来,需要在
actions
文件搜索一下
action
的名称,
reducer
文件查询一下,绕一圈才慢慢看懂。
第二个问题,按照官方推荐使用 redux-thunk 实现异步
action
的方法,只要在
action
里返回一个函数即可,这对有强迫症的人来说,简直受不了,
actions
文件显得它很不纯,本来它只是来定义
action
,却竟然要夹杂着数据请求,甚至
UI
上的交互!
我觉得
Redux
设计上没有问题,思路非常简洁,是我非常喜欢的一个库,它提供的数据的流动方式,目前也是得到社区的广泛认可。然而在使用上有它的缺陷,虽然是可以克服,但是它本身难道没有可以优化的地方?
dva
dva 的出来就是为了解决
redux
的开发体验问题,它首次提出了
model
的概念,很好地把
action
、
reducers
、
state
结合到一个
model
里面。
model
.
js
export default {
namespace: 'products',
state: [],
reducers: {
'delete'(state, { payload: id }) {
return state.filter(item => item.id !== id);
},
},
};
它的核心思想就是一个
action
对应一个
reducer
,通过约定,省略了对
action
的定义,默认
reducers
里面的函数名称即为
action
的名称。
在异步
action
的处理上,定义了
effects
(副作用)
的概念,与同步
action
区分起来,内部借助了 redux-saga 来实现。
model
.
js
export default {
namespace: 'counter',
state: [],
reducers: {
},
effects: {
*add(action, { call, put }) {
yield call(delay, 1000);
yield put({ type: 'minus' });
},
},
};
通过这样子的封装,基本保持
Redux
的用法,我们可以沉浸式地在
model
编写我们的数据逻辑,我觉得已经很好地解决问题了。
不过我个人喜好问题,不太喜欢使用
redux
-
saga
这个库来解决异步流,虽然它的设计很巧妙,利用了
generator
的特性,不侵入
action
,而是通过中间件的方式进行拦截,很好地将异步处理隔离出独立的一层,并且以此声称对实现单元测试是最友好的。是的,我觉得设计上真的非常棒,那时候还特意阅读了它的源码,赞叹作者真的牛,这样的方案都能想出来,但是后来我看到还有更好的解决方案(后面会介绍),就放弃使用它了。
mirrorx
mirrorx 和
dva
差不多,只是它使用了单例的方式,所有的
action
都保存了
actions
对象中,访问
action
有了另一种方式。还有就是处理异步
action
的时候可以使用
async
/
await
的方式。
import mirror, { actions } from 'mirrorx'
mirror.model({
name: 'app',
initialState: 0,
reducers: {
increment(state) { return state + 1 },
decrement(state) { return state - 1 }
},
effects: {
async incrementAsync() {
await new Promise((resolve, reject) => {
setTimeout(() => {
resolve()
}, 1000)
})
actions.app.increment()
}
}
});
它内部处理异步流的问题,类似
redux
-
thunk
的处理方式,通过注入一个中间件,这个中间件里判断 当前
action
是不是异步
action
(只要判断是不是
effects
里定义的
action
即可),如果是的话,就直接中断了中间件的链式调用,可以看看这段代码。
这样的话,我们
effects
里的函数就可以使用
async
/
await
的方式调用异步请求了,其实不是一定要使用
async
/
await
,函数里的实现没有限制,因为中间件只是调用函数执行而已。
我是比较喜欢使用
async
/
await
这种方式处理异步流,这是我不用
redux
-
saga
的原因。
xredux
但是我最终没有选择使用
mirrorx
或
dva
,因为用它们就捆绑一堆东西,我觉得不应该做成这样子,为啥好好的解决
Redux
问题,最后变成都做一个脚手架出来?这不是强制消费吗?让人用起来就会有限制。了解它们的原理后,我自己参照写了个 xredux 出来,只是单纯解决
Reudx
的问题,不依赖于任何框架,可以看作只是
Redux
的升级版。
使用上和
mirrorx
差不多,但它和
Redux
是一样的,不绑定任何框架,可以独立使用。
import xredux
from "xredux";
const store = xredux.createStore();
const actions = xredux.actions;
// This is a model, a pure object with namespace, initialState, reducers, effects.
xredux.model({
namespace: "counter",
initialState: 0,
reducers: {
add(state, action) { return state + 1; },
plus(state, action) { return state - 1; },
},
effects: {
async addAsync(action, dispatch, getState) {
await new Promise(resolve => {
setTimeout(() => {
resolve();
}, 1000);
});
actions.counter.add();
}
}
});
// Dispatch action with xredux.actions
actions.counter.add();
在异步处理上,其实也存在问题,可能大家也遇到过,就是数据请求有三种状态的问题,我们来看看,写一个数据请求的
effects
:
import xredux from 'xredux';
import
{ fetchUserInfo } from 'services/api';
const { actions } = xredux;
xredux.model({
namespace: 'user',
initialState: {
getUserInfoStart: false,
getUserInfoError: null,
userInfo: null,
},
reducers: {
// fetch start
getUserInfoStart (state, action) {
return {
...state,
getUserInfoStart: true,
};
},
// fetch error
getUserInfoError (state, action) {
return {
...state,
getUserInfoStart: false,
getUserInfoError









