
The Data Incubator 中,有着最新的数据科学(data science)课程。其中大部分的课程都是基于企业和政府合作伙伴的需求而设立的。现在他们希望开发一更偏向数据为驱动的方式,以了解应该为数据科学企业的培训(data science corporate training,以及享受其提供的免费助学金的有意愿进入业界数据科学领域的硕博士生们教授什么样的内容。结果如下。
排名
什么是最流行的机器学习包(ML packages)?让我们来看一下基于包下载量(package downloads)和社交网站活跃度的排名。
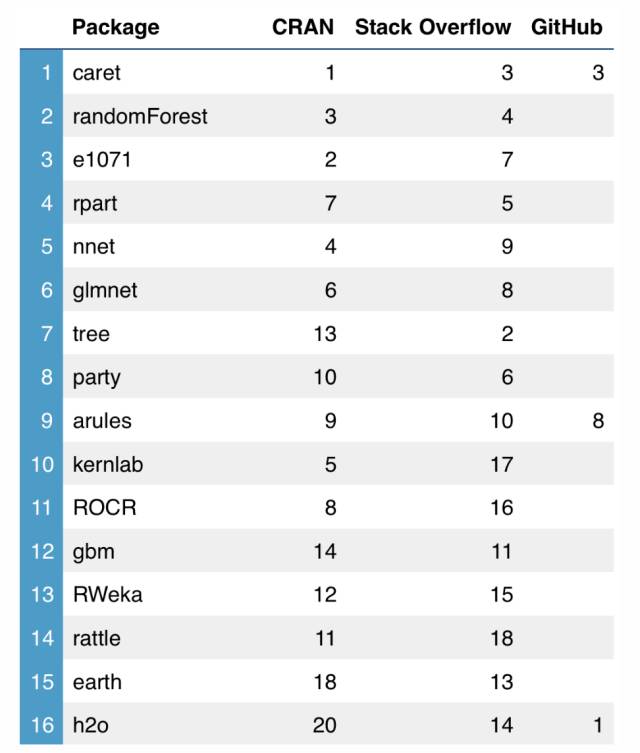
注:OneR: 1 (SO); mlr: 2 (Github); ranger: 4 (Github); SuperLearner: 5 (Github)
该排名基于 CRAN ( The Comprehensive R Archive Network (https://cran.r-project.org/) ) 下载量和 Stack Overflow 活跃性的平均排名(完整排名 [CSV] (https://github.com/thedataincubator/data-science-blogs/blob/master/ranking.csv)))。
其中 CRAN 的下载量是过去一年的数据。Stack Overflow 则是根据基于问题正文中下载包的名称并以 『R』进行标记的结果数进行排名。
GitHub 的排名则是由存储库中的星星数而来。有关方法的详细信息,请参阅下文
CARET 排名第一,多个神经网络排名靠前
caret 排名第一也许并不奇怪。它是一个用于创建机器学习工作流的通用软件包,能很好地与一些算法特定的软件包(排名靠后)整合在一起。
这些包括了 e1071 ( 用于支持向量机,SVMs), rpart (trees), glmnet ( 正则化回归,regularized regressions), 也许还有 R,神经网络 (nnet)。有关软件包的详细信息如下
排名说明了 R 软件包社区的碎片化程度。一些顶级的软件包,比如 rpart 和 tree,部署了相同的算法,这与 Python 的 scikit-learn 的一致性和宽度形成对比。
但是,如果你喜欢 R 的数据操作能力(就像在 tidyverse 中),那么你就可以使用这些软件包做一些功能强大的模型,而不用切换到 python。此外,随着 modelr (https://github.com/hadley/modelr) 中添加了更多的功能,我们也许很快能在此列表中看到 tidy tool。
包的细节
caret 是一个用于创建机器学习工作流的一般包,并且它已经处于这个排名的首位置。接着的是实现特定机器学习算法的几个包:随机森林(Random Forests)(randomForest), 支撑向量机(Support Vector Machines)(e1071), 分类和回归树(Classification and Regression Trees)(rpart), 和 正则化回归模型(regularized regression models)(glmnet).
nnet 实现了神经网络,而 tree 包同样实现了树的功能。party 用于二叉树的递归分割和可视化,arules 则用于关联挖掘。支持向量机(SVMs)和其他的内核方法则部署在 kernlab 中。h2o 包用于可扩展的机器学习,而且是更大的 H2O 项目的一部分。ROCR 用于模型评估,包括 ROC 曲线(接收者操作特征曲线,receiver operating characteristic curve),gbm 实现梯度推进。更多的分割算法(partitioning algorithms)可以使用 RWeka 进行访问,而 rattle 是数据挖掘中的 R 的一个图形用户界面(GUI)。
一些包则只在 Github 中发挥强大功能: mlr 和 SuperLearner 是另外两个元包(meta-package),为 caret 提供类似的符号插入的功能,ranger 提供了随机森林(random forests)的 C++ 实现。
最后,OneR 在 Stack Overflow 中排名第一,但是 SO API 经常将其自动修正为「one」,所以结果并不可信。
方法
接下来,我们描述一下这种排名所使用的方法。
步骤 1: 获得 机器学习包的详尽列表
一开始,我们设想我们的排名综合考虑了包下载量、Stack Overflow 和 Github 活跃度。我们知道能为我们提供这些指标的 API 已经存在了
然而,获得机器学习的所有 R 包的初始列表是一件更加艰巨的任务。我们需要一份详尽客观的并且是最新的一份列表。一份不好的初始化列表将会严重影响我们的排名。
寻求帮助。一个朋友把一篇文章「CRAN 任务视图:机器学习和统计学习 (CRAN Task View: Machine Learning & Statistical Learning)」介绍给我,该文章底部有一份非常不错的列表,并且很容易入手。
这样做的好处是包列表的来源非常具有权威性(CRAN 是官方 R 包存储库)并且它会经常更新(最近的更新:2017 年 1 月 6 日)。感谢作者,Torsten Hothorn 通过邮件提供的帮助。
以前的想法是使用 Google 来寻找「顶级 R 机器学习包」的列表,然后试着从列表上抓取所有包的名称,将它们结合起来,并使用该列表作为起点。但是抛开工程任务来说,当前可用的列表质量相对较差,不能满足我们的需求。它们过时了,没有明确的说明方法,并且往往是极其主观的。
确定客观指标
一个好的排名需要一个对于「最佳(best)」的定义,这需要用良好的指标来搭建。我们将「最佳」定义为「最流行」。这并不一定意味着这个包是广受欢迎的(由于糟糕的 API,用户可能经常会搜索 Stack Overflow)
我们为我们的排名选取了 3 个因素:
CRAN 下载
有一些 CRAN 的镜像,而我们使用的是 R-Studio 镜像,因为它有一个便捷的 API。RStudio 一定是 R 中使用最广泛的 IDE,但却并非是唯一的。如果我们从其他 CRAN 的镜像统计下载量,我们的排名可能会更好(但并不会有显著变化)。
GitHub
最初,我们通过在 Github 的 search API 上查询包的名字来寻找包的 Github 页面,可能会使用「language:R」,但这么做是不可靠的。有时候很难选择正确的 Github 库,而且不是所有的 R 包都是用 R 语言来实现的(在该搜索 API 中,「language:R」参数似乎指的是该存储库写入所使用的最流行的语言)
相反,我们返回 CRAN 来寻找这些 URL。每个包都有一个官方的 CRAN 页面,其中包括了一些有用的信息,比如源代码链接。这就是我们得到的包的 Github 存储库的位置。
在这之后,使用 API 就可以容易地得到 Github 的星星数。
Stack Overflow
从 Stack Overflow 获取有用的结果需要技巧。一些 R 包的名称,比如 tree 和 earth,存在着明显的困难:Stack Overflow 的结果可能不会被筛选到 R 包的结果当中,所以我们首先在查询中添加一个 「r」 字符串,这非常有帮助。
一个好的(最优的?)策略是在问题主题中查询包的名字,然后添加一个 『r』标签(这与添加 『r』 字符串不同)
建立排名
我们简单地将包按照 3 个指标中的每一个来排名,并取其平均值。该方法没什么特别的地方。
杂注
所有的数据都是在 2017 年 1 月 19 日下载的。CRAN 的下载量则是统计了过去 365 天的数据:从 2016 年 1 月 19 日 到 2017 年 1 月 19 日。
数据科学领域最顶级的 R 包?
一开始,这个项目是要将「数据科学」领域中所有顶级的包进行排名,但我们很快发现这个范围太大。
数据科学家做了很多不同的事情。要帮助一个数据科学家,你要将几乎所有的 R 包进行分类。那么,我们应该包含字符串操作包吗?包是如何从数据库中读取数据的呢?
也许有一天,会有一个更长的项目,它会更多地使用 「Data Science」 来为「数据科学」工作得出一个顶级 R 包的排名。
资源:
源代码请查看 The Data Incubator (https://www.thedataincubator.com/) 的 Github (地址:https://github.com/thedataincubator/data-science-blogs/)。如果有兴趣学习更多,请参考:
1.Data science corporate training
(www.thedataincubator.com/training.html)
2. Free eight-week fellowship for masters and PhDs looking to enter industry
(www.thedataincubator.com/fellowship.html)
3. Hiring Data Scientists
(www.thedataincubator.com/hiring.html)
原文链接:http://www.kdnuggets.com/2017/02/top-r-packages-machine-learning.html
源自:kdnuggets,作者:Michael Li 、Paul Paczuski,机器之心编译,参与:王宇欣、杜夏德
阅读原文,更多热门;扫码识别,关注“机器人网”





