不久前百度首席科学家吴恩达在百度语音开放平台上线三周年活动上,发布了百度四项最新语音技术——情感合成、远场方案、唤醒二期技术和长语音方案,并宣布这些技术通过免费接口提供给开发者使用。这在一定程度上促进了语音输入技术的发展,让更多的用户采纳语音输入。再加上这些年移动智能设备的普及,算法模型和语义分析技术的成熟,AI技术的深度使用,帮助输入法在智能化道路上更快发展。
11月26日,由百度开发者中心和极客邦科技、InfoQ联合举办的第68期百度技术沙龙邀请了百度输入法团队的研发工程师们,从三个方面解析百度输入法移动端输入技术,包括对 iOS 输入法启动速度和内存的优化措施;AI 在手写引擎中的应用,输入体验的提升;以及智能语音输入的技术核心,实现方式,优化细节等。
iOS输入法启动速度优化
百度资深研发工程师 范敏虎先是介绍了百度输入法iOS版本是2014年苹果在iOS8上线开放Extension开发之后,上线到AppStore的,它的前身是百度输入法越狱版。由于Extension的特殊性,系统对Extension的运行做了很多限制,首先限制的就是速度,其次就是内存限制。表面上看输入法仅仅是一个面板,但是麻雀虽小五脏俱全,开发输入法甚至会面临比普通app更多的技术问题。
启动过程中,需要进行三个步骤,Extension查找、Extension启动、Host与Extension交互。Host通过xpc的方式请求pkd,找到需要的Extension;Host通过name连接Extension,xpc.launchd启动Extension;在交互过程中,Host远程调用Extension的方法来展示键盘。由下图可见,整个启动过程里可能会遇到四个问题。
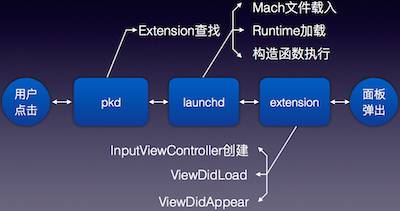
这四个问题包括:皮肤文件解码载入需要大量CPU时间,UI渲染需要一定的CPU时间,内核词库的载入消耗大量I/O时间,静默任务处理也要耗费一定的时间。这里面还需要考虑皮肤文件的大小,词库的大小,I/O的处理方式等等,这些都会直接影响启动速度。
范敏虎说,他们的最终解决方案,就是在皮肤生成的时候把图片进行解码进行保留,然后载入解码信息。其次就是避免频繁创建对象,再次是内核操作在独立线程运行的。第四点就是内部单独调度,每个任务被当成一个进程处理。
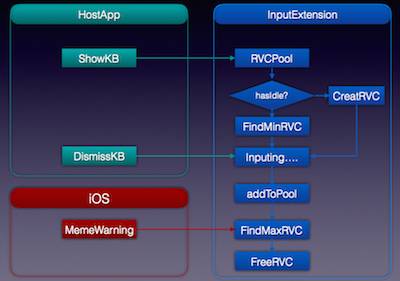
上面提到的一个比较重要的事情就是关于面板重用,在手机上不同的App里面,都会出来一个新的输入面板,势必会影响输入速度。范敏虎的解决方案就是创建一个缓冲池,把面板对象放入缓冲池,同时尽量让数据层独立,好处就是不需要重复创建数据层对象。另外就是做了一个均衡,尽量使所有创建的面板对象占用尽可能相同的内存,其好处就是可以释放更多的内存。(如下图结构)
次任务调度
为了不影响输入,静默任务被添加到面板启动过程中,这会严重影响面板的启动时间和稳定性,同时还会出现面板上多次弹窗等问题。范敏虎说,这个问题的解决方案可以概括为如下:
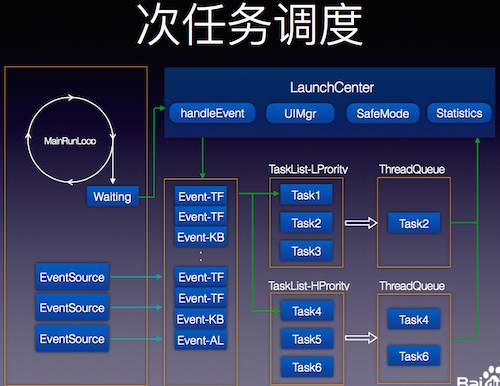
经过各种优化,包括内存和渲染独立,减少执行时间,实现交互流畅,最终给用户一个很好的操作体验。
AI助力手写输入引擎提升输入体验
百度资深研发工程师贺亮说,机器学习是一个重要的领域,百度输入法也在使用机器学习的算法。百度输入法第一代使用的是比较传统的模式识别技术,仅仅是对界面上的笔记轨迹进行处理。现在使用的是基于深度学习网络的技术,就是直接抛到网络里面进行计算,得到一个识别结果。第一代手写引擎的架构(下图)。
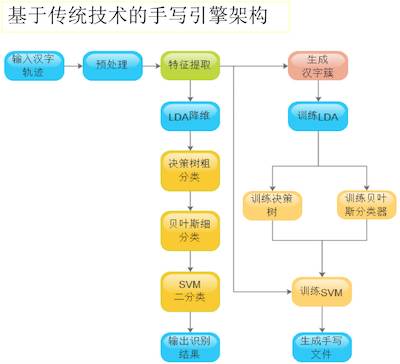
首先,特征提取部分就是一个训练过程和识别过程。训练过程就是先拿到已经标注好的字,对特征进行压缩。训练决策树是对于特征做粗分类,得到一个结果。分类器就是对于两个比较相近的字进行分类,最后得到一个输出结果。
关于轨迹预处理,通常情况下会遇到这些问题: