随机森林在过去几年里得到了蓬勃的发展。它是一种非线性的基于树的模型,往往可以得到准确的结果。但是,随机森林的工作过程大都处于黑箱状态,往往难以解读和完全理解。近日,Pivotal Engineering Journal 网站发表了一篇文章,对随机森林的基础进行了深度解读。该文从随机森林的构造模块决策树谈起,通过生动的图表对随机森林的工作过程进行了介绍,能够帮助读者对随机森林的工作方式有更加透彻的认识。本文内容基于 Ando Saabas 的一个 GitHub 项目。另外,你也能在 GitHub 上找到用于创建本文中各种图表的代码。
决策树的工作方式
决策树可以看成为一个 if-then 规则的集合,即由决策树的根节点到叶节点的每一条路径构建一条规则,路径上内部节点的特征对应着规则的条件,而叶节点的类对应于规则的结论。因此决策树就可以看作由条件 if(内部节点)和满足条件下对应的规则 then(边)组成。
决策树的工作方式是以一种贪婪(greedy)的方式迭代式地将数据分成不同的子集。其中回归树(regression tree)的目的是最小化所有子集中的 MSE(均方误差)或 MAE(平均绝对误差);而分类树(classification tree)则是对数据进行分割,以使得所得到的子集的熵或基尼不纯度(Gini impurity)最小。
结果得到的分类器可以将特征空间分成不同的子集。对某个观察的预测将取决于该观察所属的子集。
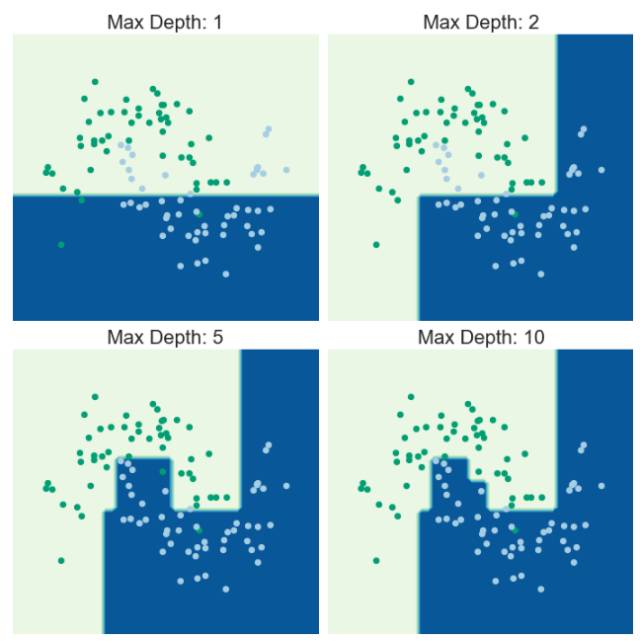
图 1:一个决策树的迭代过程
决策树的贡献
以鲍鱼数据集(https://archive.ics.uci.edu/ml/datasets/abalone)为例。我们将根据壳的重量、长度、直径等变量来预测鲍鱼壳上环的数量。为了演示,我们构建了一个很浅的决策树。我们可以通过将树的最大层数限制为 3 而得到这个树。
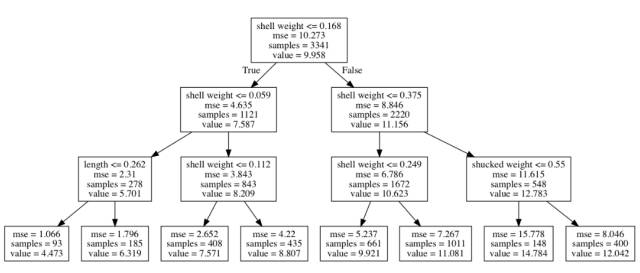
图 2:预测不同环数的决策树路径
要预测鲍鱼的环的数量,决策树将沿着树向下移动直到到达一个叶节点。每一步都会将当前的子集分成两个。对于一次特定的分割,我们根据平均环数的改变来定义对该分割做出了贡献的变量。
比如说,如果我们拿到一个壳重 0.02、长度为 0.220 的鲍鱼,那么它就将落在最左边的叶节点上,预测的环数是 4.4731。壳重对预测环数的贡献为:
(7.587 - 9.958) + (5.701 - 7.587) = -4.257
长度的贡献为:
(4.473 - 5.701) = -1.228
这些贡献都是负数,说明对于这个特定的鲍鱼,壳重和长度值会使预测的环数下降。
我们可以通过运行以下代码得到这些贡献。
from
treeinterpreter
import
treeinterpreter
as
ti dt_reg_pred, dt_reg_bias, dt_reg_contrib = ti.predict(dt_reg, X_test)
其中变量 dt_reg 是 sklearn 分类器目标,X_test 是一个 Pandas DataFrame 或 numpy 数组,包含了我们希望从中得到预测和贡献的特征。其贡献变量 dt_reg_contrib 是一个二维 numpy 数组 (n_obs, n_features),其中 n_obs 是观察的数量,n_features 是特征的数量。
我们可以绘制一个给定鲍鱼的这些贡献的图表,看看哪些特征对预测得到的值的影响最大。我们可以从下面这幅图表看到这个特定的鲍鱼的重量和长度值对预测得到的环数所产生的负影响。
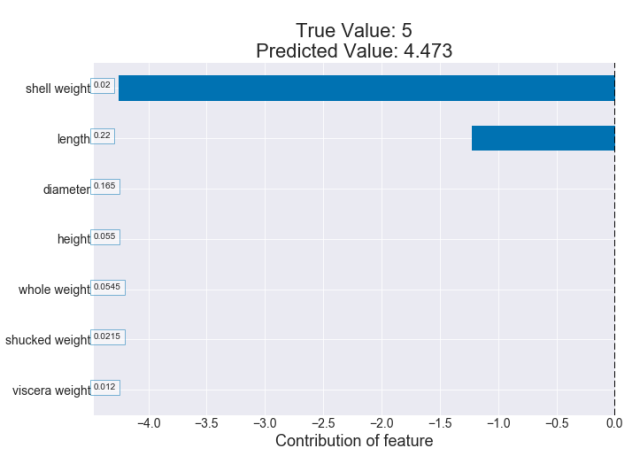
图 3:一个贡献图表示例(决策树)
我们可以使用小提琴图表(Violin plot)将这个特定鲍鱼的贡献与所有鲍鱼的情况进行比较。这样可以在这张图表上叠加一个核密度估计。在下图中,我们可以看到,与其它鲍鱼相比,这个特定鲍鱼的壳重异乎寻常地低。实际上,很多鲍鱼的壳重值的贡献都是正数。
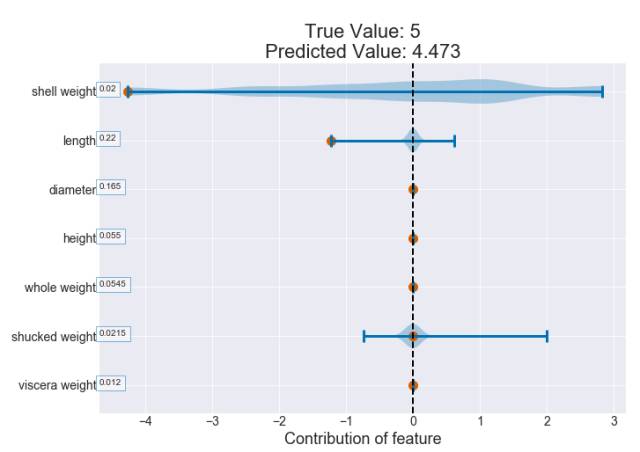
图 4:使用 violin 图对一个观察样本绘制的贡献图(决策树),文末将附上 violin 图的基本概念与用法。
上面的图虽然有些信息,但仍然无法让我们完全理解一个特定变量对鲍鱼所拥有的环数的影响。于是,我们可以根据一个给定特征的值绘制其贡献。如果我们绘制壳重的值与其贡献的比较,我们可以知道壳重的增长会导致贡献的增长。
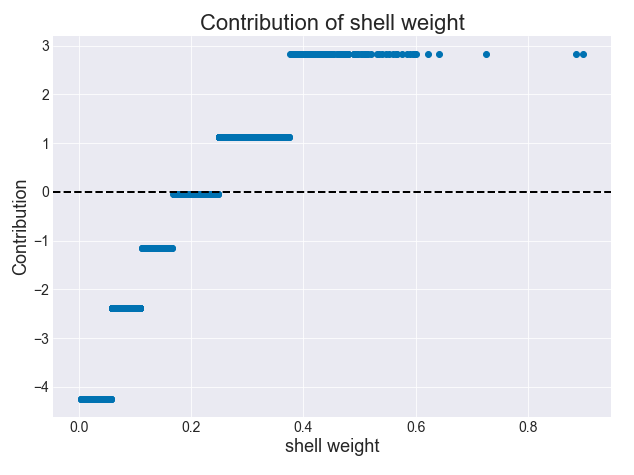
图 5:贡献与壳重(决策树)
另一方面,去壳后的重量与贡献的关系是非线性非单调的。更低的去壳后的重量没有任何贡献,更高的去壳后的重量有负贡献,而在两者之间,贡献是正的。
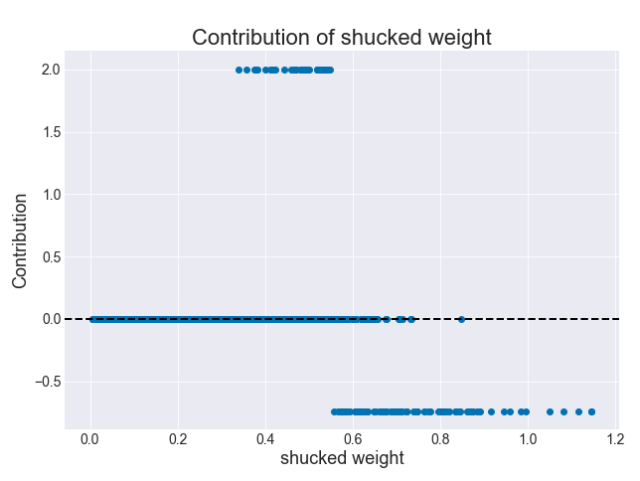
图 6:贡献与去壳后的重量(决策树)
扩展成随机森林
通过将许多决策树组成森林并为一个变量取所有树的平均贡献,这个确定特征的贡献的过程可以自然地扩展成随机森林。
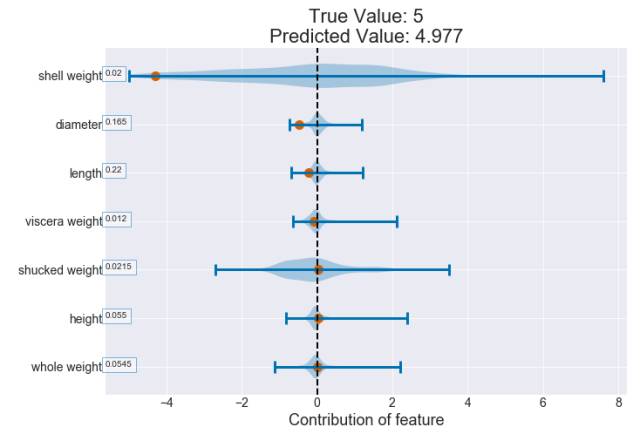
图 7:使用 violin 图对一个观察绘制的贡献图(随机森林)
因为随机森林固有的随机性,一个给定壳重值的贡献会有所不同。但是如下图平滑的黑色趋势线所示,这种增长的趋势仍然存在。就像在决策树上一样,我们可以看到壳重增大时,贡献会更高。
打破传统
最强性价比
理论+实战
打造期货股票交易系统
为投资者打造全新学习交流体验
2017年11月6日
报名电话/微信:18516600808

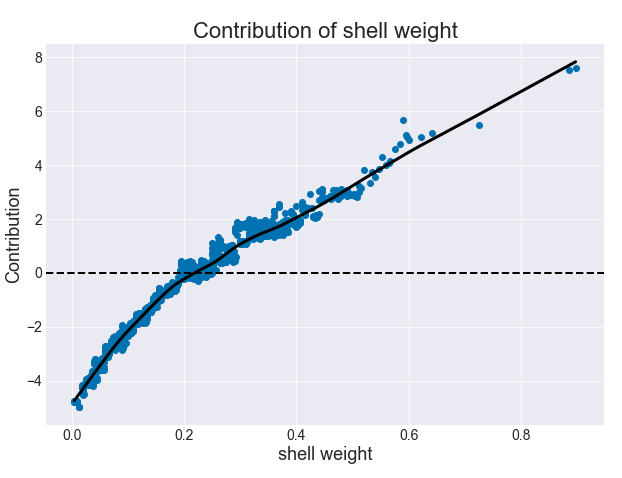
图 8:贡献与壳重(随机森林)
同样,我们也可能会看到复杂的不单调的趋势。直径的贡献似乎在大约 0.45 处有一处下降,而在大约 0.3 和 0.6 处各有一处峰值。除此之外,直径和环数之间的关系基本上是增长的。
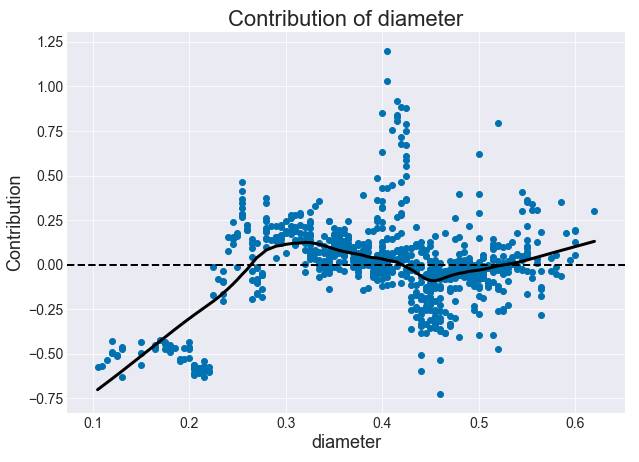
图 9:贡献与直径(随机森林)
分类
我们已经看到回归树的特征分布源自环的平均值以及其在后续分割中的变化方式。我们可以通过检查每个子集中某个特定类别的观察的比例,从而将其扩展成二项分类或多项分类。一个特征的贡献就是该特征所导致的总的比例变化。
通过案例解释更容易理解。假设现在我们的目标是预测性别,即鲍鱼是雌性、雄性还是幼体。
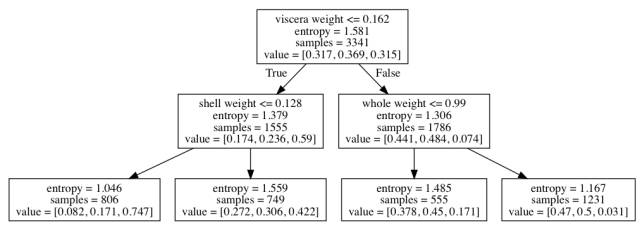
图 10:多项分类的决策树路径
每个节点都有 3 个值——该子集中雌性、雄性和幼体各自的比例。一个脏器重量为 0.1 且壳重 0.1 的鲍鱼属于最左边的叶节点(概率为 0.082、0.171 和 0.747)。适用于回归树的贡献逻辑在这里也同样适用。
如果这个特定鲍鱼是幼体,那么脏器重量的贡献为:
(0.59 - 0.315) = 0.275
壳重的贡献为:
(0.747 - 0.59) = 0.157
我们可以为每个类别绘制一张贡献图。下面我们给出了针对幼体类别的贡献图。
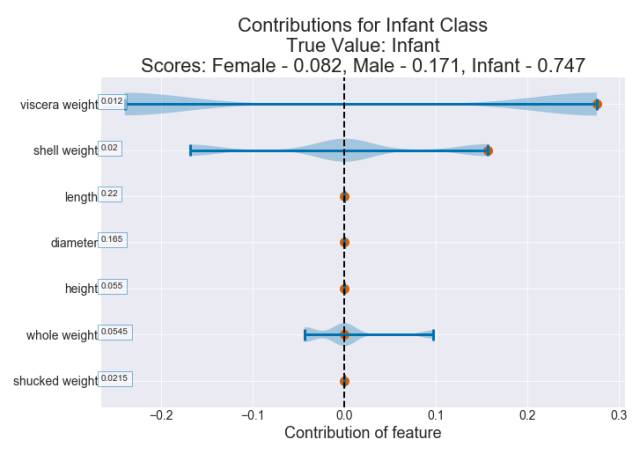
图 11:使用 violin 图对一个幼体观察绘制的贡献图(多类决策树)
和之前一样,我们也可以为每一类绘制贡献与特征的图表。壳重对鲍鱼是雌性的贡献会随壳重的增长而增长,而对鲍鱼是幼体的贡献则会随壳重的增长而降低。对于雄性来说,壳重的贡献首先会增长,在壳重超过了 0.5 之后贡献又会下降。
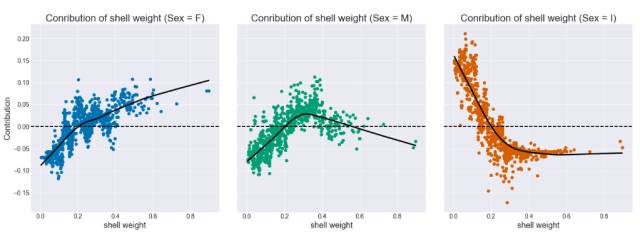
图 12:每个类别的贡献与壳重(随机森林)










