编者按:能否理解自然语言一直以来都是衡量人工智能技术水平的重要标准之一。而近几年,自然语言处理技术的发展十分迅速,就在今年1月,
微软亚洲研究院机器阅读系统R-NET模型在SQuAD文本理解挑战赛中的EM值上率先超越了人类水平
。
那么除了SQuAD,还有什么测试集能测试机器的阅读理解能力呢?本文中,来自卡内基·梅隆大学的在读博士赖国堃和谢其哲(
前微软亚洲研究院机器学习组实习生
)向我们介绍了他们创建的初高中英语考试阅读理解数据集RACE和完形填空数据集CLOTH。当机器遭遇更难的数据集时会表现如何呢?一起来看看吧!

相信经历过中高考的同学都知道英语阅读题的难度。要想选出正确答案,不仅需要找到相关的上下文,还需要逻辑推理并运用社会、数学、文化等方面的常识进行分析。
那么,
现在的
机器学习技术能正确回答用来测试人类的题目吗
?
为了探索这个问题,我们团队收集
并
提出了两个分别来自初高中英语考试中的阅读理解和完形填空题
的数据集,并对这
两个数据集以及目前机器能达到的水平进行
了
分析
。

初高
中
英语考试阅读理解数据集RACE
【题型组成】
英语考试中的
阅读理解考察的是学生对于英语总体的阅读能力
。
阅读文章后,阅读者会根据对文章的理解,在候选答案中选择正确答案。阅读理解的问题类型很难人为分类
,
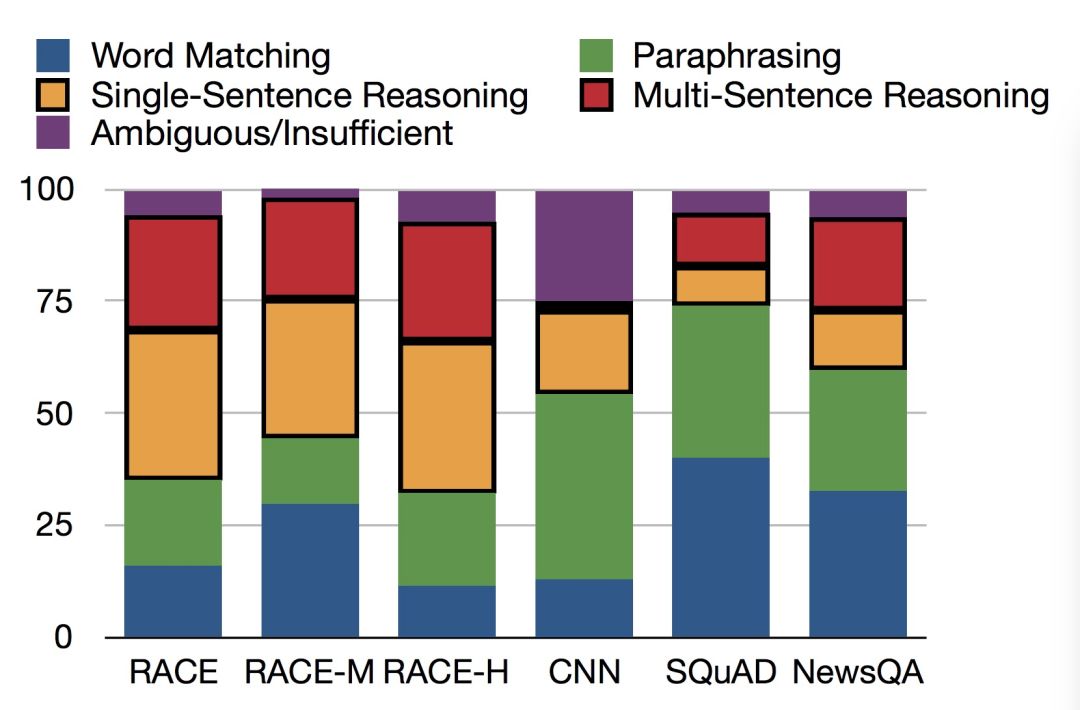
我们根据问题的难易程度分为匹配题以及推理题
两大类
。 匹配题指的是需要阅读者在文章中找到问题对应位置,然后找到问题答案。推理题则需要阅读者总结、分析文章中的线索,进而再选出正确答案。我们在亚马逊众包平台上让Turker(点击工人)对部分数据进行了标注,发现大约35%的题目是匹配题,65%是推理题
,
这个比例远远超过所有大规模机器学习训练集。下图中给出了不同数据集题目类型的比较
。
下面我们给出一个初中阅读理解题作为例子
,也带大家回忆一下自己青葱的少年时光。

怎么样,是不是感觉自己一秒回到初中英语课堂?这几道问题中,
第一题与第四题看起来是简单的匹配题,但其实是需要机器学习模型完全理解文中的代词指代关系,才能选出正确的答案。第二题也是一个典型的推理题,如果直接到文中女孩返还信件的部分,会得到‘女孩没钱付邮票’的答案。但是如果继续读下去,就会发现真实的原因是女孩已经知道信件的内容了。
推理能力是解答阅读理解问题所需要的重要能力,因此RACE数据集可以很好的衡量机器的阅读理解能力
。
【数据集大小】
我们一共收集了28,130篇文章,包含了98,432个问题。 其中 25%来自初中级别英语考试,75%来自高中级别英语考试。
【实验结果】
我们测试了多个深度阅读理解模型在RACE的表现,
最好的模型在测试集中仅取得了42.9%的正确率
。而众包平台上
Turkers在采样的测试数据点上取得了73.3%的正确率
,由于题目存在一定难度,并且我们没法完全控制Turker的认真程度,所以不能取得100%的正确率。可以看出
现阶段的机器学习模型无论是与标准答案还是与测试者的成绩相比都存在着相当大的差距
。
初高中
英语考试完形填空数据集CLOTH
【题型组成】
完形填空考察的是学生对于英语的理解和运用
,常见的题型包括语法题,词汇题和推理题。下面的图中包含了一个完形填空的例子,这个例子中总共有17个空,每个空提供了四个选项,学生需要从四个选项中选出一个最正确的。

我们可以看到在这个例子中,很多选项
在
语法上都是完全说
得
通的,因此我们需要先对上下文进行语义分析,再来选出正确答案。比如第三道题之所以选‘first’,是因为文章提到Nancy进入办公室后发现没有其他人。
【数据集大小及组成】
类似的,我们的完形填空数据集总共有99,433个问题,因此我们能使用深度学习模型解决这个数据集的问题。其中包括26.5%的语法题,50.3%的单句推理/词汇题,4.4%的上下文匹配题,和18.0%的多句推理/词汇题。
【实验结果】
我们测试了多个模型在CLOTH数据集上的效果,包括语言模型、Stanford Attentive Reader、以及我们提出的新模型,其中
最好的模型能达到58.3%的正确率
,而众包平台上
Turker能取得85.9%的正确率
,因此在此数据集上,要达到人类的水平依然需要进行大量研究。
同时,我们发现如果在一个极大的外部语料(1 Billion Word)上训练一个语言模型,再拿到CLOTH上进行测试,正确率可以提高至
70.7%
。通过比较分析得知语言模型能很好的理解单句话,但在多句推理方面跟人类还是相差甚远。
然而,该语言模型正确率的提高幅度
仍然令人惊讶——一是因为
1 Billion Word
为新闻语料,而
CLOTH
的文章大部分是小故事;二是因为语言模型和完形填空关注的词很不一样,任务很不相同。所以,这一结果可以表明
语言模型在大型语料上学到的语言规律能够扩展到其它领域和其它任务
。从最近的一篇论文
deep contextualized word vectors中
,我们也可以得到类似的结论,他们使用
1 Billion Word上的语言模型的隐层作为embedding,在6个NLP任务上均取得了出色的结果
。
结语
通过对这两个数据集的研究,我们认识到要达到人类的语言理解水平,机器仍然有很长的一段路要走。我们希望通过提出这两个数据集,帮助有志之士研究更难的机器阅读理解题。
链接:
-
RACE数据集:
http://www.cs.cmu.edu/~glai1/data/race/
-
RACE论文:
https://arxiv.org/pdf/1704.04683.pdf
-
CLOTH数据集:
http://www.cs.cmu.edu/~glai1/data/cloth/
-
CLOTH论文:
https://arxiv.org/pdf/1711.03225.pdf









