
本文根据邹兴标老师在〖2020 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。

(点击文末“阅读原文”可获取完整PPT)
邹兴标,
爱奇艺数据分析平台高级经理,10年数据领域工作,专注数据建设及数据应用方向。目前在爱奇艺负责用户分析平台及内容分析平台的开发工作。在数据仓库及OLAP分析方面有丰富的从业经验。
在流量饱和的时代背景下,业务的增长依赖于通过大数据快速精准分析进行业务试验与升级,从而找到真正的Magic Number。业务各个节点的发展对数据具有强依赖性,随着业务的发展,这些数据对于时效性以及分析复杂度的要求越来越高。如何利用平台化的方式,将精细化的业务、分析需求统一解决,如何实现多维度,多行为的交互式分析是成为了技术团队的条件。
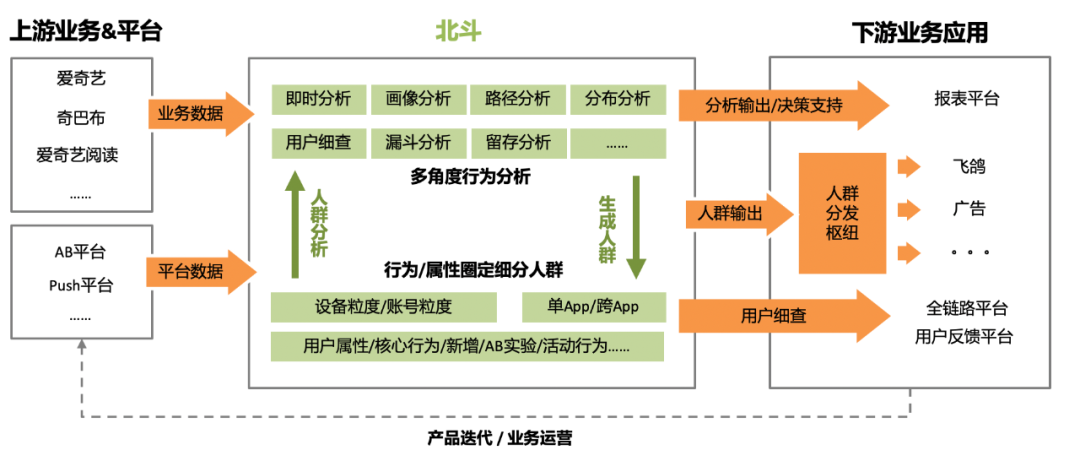
精细化运营平台-北斗是爱奇艺技术团队自研的交互式用户分析平台。支持用户核心行为,叠加用户画像标签的方式以定位目标人群,从而进行有针对性地业务维度分析。
爱奇艺在2015年上线了基于hive的自助查询平台。但是随着业务的快速发展和数据量的急剧增长。基于hive的查询平台从分析深度及分析时效性已经无法满足业务的需求。于是急需一个交互式(秒级结果返回)的用户分析平台来满足业务需求。
在用户分析平台上线前,业务通过自主查询工具进行数据分析时面临着以下困难:
-
查询耗时长:基于hive的多表关联及大表的单表查询往往需要半小时及以上的时间才能出结果,无法快速验证想法;
-
分析门槛高:用户基于数据理解进行数据查询,没有现成的路径,留存等分析模板使用,从而使得数据分析需要专业分析师才能进行,无法赋能与运营等业务人员数据分析能力;
-
数据使用未形成闭环:在查询平台获取查询满意的数据结果后,无法将数据结论直接应用到线上形成数据分析的闭环。
针对以上,我们搭建了用户分析平台-北斗,实现了交互级别的用户行为分析,让数据可快速的 分析→决策→行动,实现数据分析的闭环。不但为业务提供表的查询服务,进一步提供了用户行为分析的解决方案。
如下图:用户分析平台接入爱奇艺各大业务数据及基础平台数据,以用户分群为核心,支持画像,路径,留存等各类分析行为。且可将分析人群可输出至线上系统,实现数据分析的闭环。
项目对于查询引擎的选择有以下三个原则:
-
大数据基础架构对查询引擎的支持粒度;
-
项目成员对于查询引擎的熟悉程度;
-
查询引擎在项目场景上的性能优劣。
公司大数据基础架构团队已经支持Kylin、Impala、Kudu、Druid,Spark等不同的数据查询引擎。我们选择了Impala、Spark、Kylin进行了性能测试。

测试结果如下:
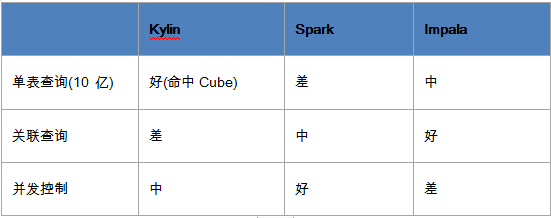
用户分析平台最主要的特性是实现多行为的组合分析,例如:圈选在最近30天播放过青春有你2大于120分钟,且是一线城市的女性用户。需要将播放行为关联用户属性表。因此此次测试最重要的指标是大表之间的关联。经过多个场景的测试后,最终选择了impala作为用户分析平台的查询引擎。
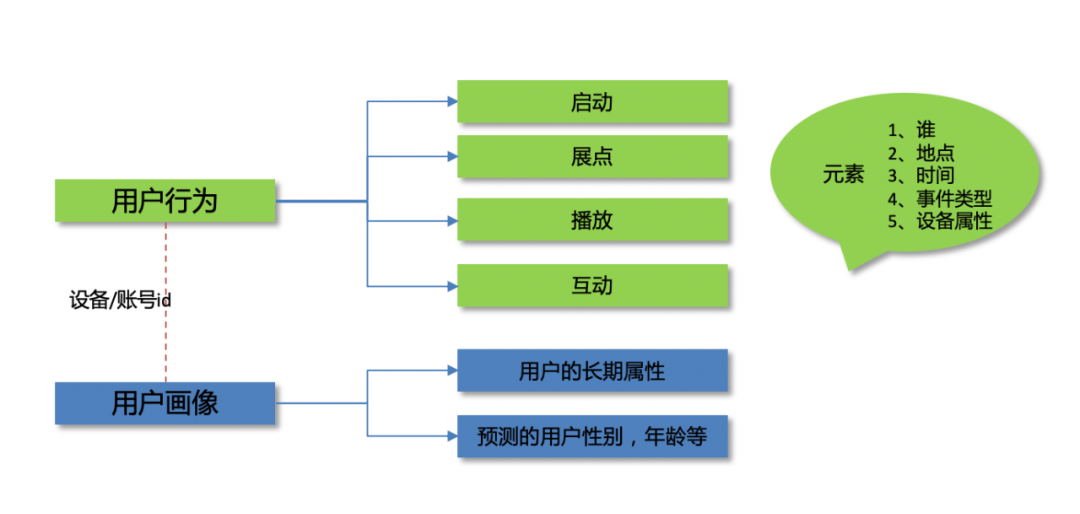
如下图,项目参考了神策的数据建模思路,结合爱奇艺的业务场景,将数据划分为两大模块,用户行为数据及用户画像数据:
-
用户行为和用户画像之间通过设备id或者账号id实现关联分析;
-
行为包含如下元素:
发生的主体:设备id或者账号id;
发生的地点:包含ip地址或者gps信息;
发生的时间:发生事件时的客户端时间;
事件的类型:如上图有启动,展示点击,播放,各类互动等事件;
发生时设备的属性:品牌信息等设备属性;
-
用户画像:涵盖了算法团队对于用户性别,年龄等预测信息。
基于如上的数据模型,可实现各类用户行为叠加用户画像的分析,满足个性化的业务场景需求。
但是爱奇艺日均有上亿的独立设备数,超过500TB的数据增量。如何基于impala实现秒级的查询返回仍然是一个巨大的挑战。
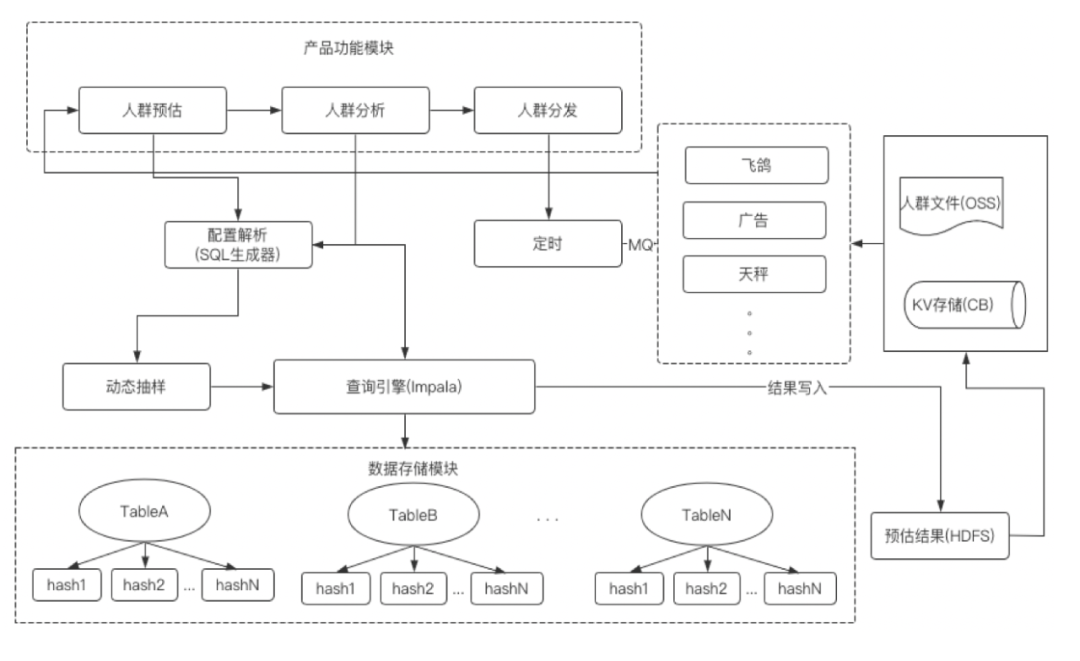
通过对目标使用用户的调研,在绝大多数的分析场景下可以接受一定的误差(千分之五以内),于是系统的核心模块采用了抽样分析。如下图:
-
用户行为数据及画像数据使用了MurmurHash算法将数据均匀的打散到100个分区中;
-
使用parquet格式进行数据存储,减少scan hdfs的时间;
-
后端服务使用动态采样进行分析查询,即初次查询单分区数据,若发现目标样本过少,提升抽样比,在追求效率的同时保证误差在千分之五以内。
如下图:需要圈选出20200101至20200331观看中国新说唱2019时长超过1200秒的女性,且在20200401未启动的用户:
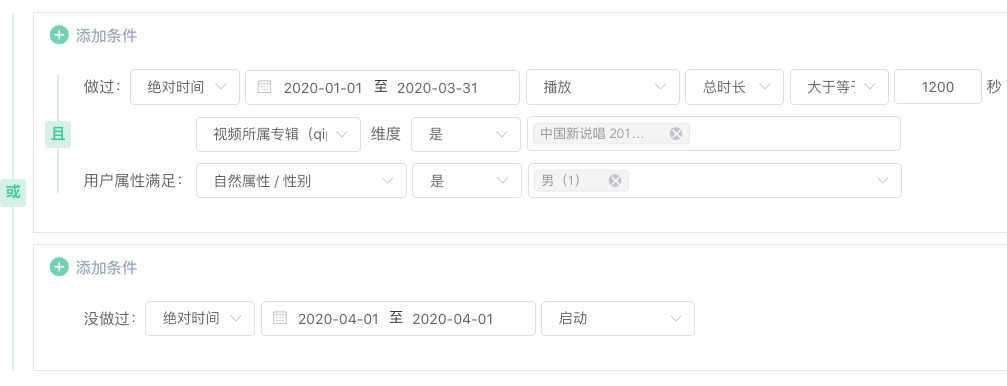
示例需要从900亿数据中圈选出条件人群,如果使用全量查询需要耗时70S,使用下图抽样引擎后,查询效率提升至7S,误差在千分之一。
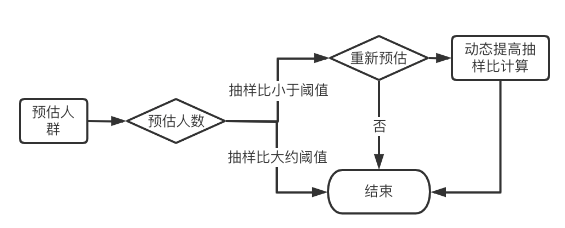
通过抽样查询,满足了用户对于分析的时效性的需求。









