文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘中的一种方法。文本挖掘中最重要最基本的应用是实现文本的分类和聚类,前者是有监督的挖掘算法,后者是无监督的挖掘算法。
1)读取数据库或本地外部文本文件
2)文本分词
2.1)自定义字典
2.2)自定义停止词
2.3)分词
2.4)文字云检索哪些词切的不准确、哪些词没有意义,需要循环2.1、2.2和 2.3步骤
3)构建文档-词条矩阵并转换为数据框
4)对数据框建立统计、挖掘模型
5)结果反馈
本次文本挖掘将使用R语言实现,除此还需加载几个R包,它们是tm包、tmcn包、Rwordseg包和wordcloud包。
本文所用数据集来自于sougou实验室数据,具体可至如下链接下载:
http://download.labs.sogou.com/dl/sogoulabdown/SogouC.mini.20061102.tar.gz
本文对该数据集做了整合,将各个主题下的新闻汇总到一张csv表格中,数据格式如下图所示:
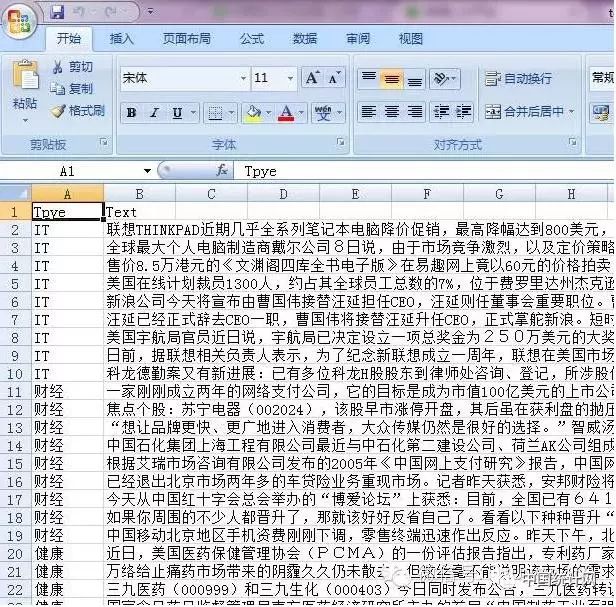
具体数据可至文章后面的链接。
#加载所需R包
library(tm)
library(Rwordseg)
library(wordcloud)
library(tmcn)
#读取数据
mydata str(mydata)
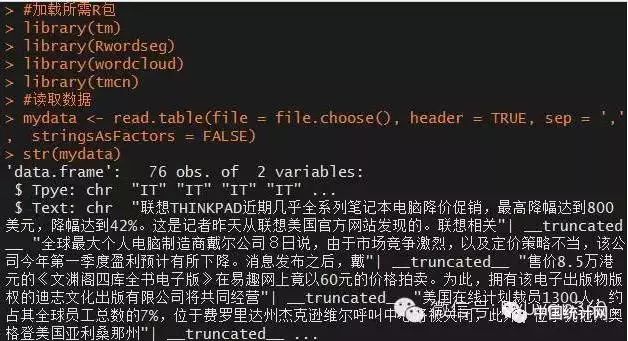
接下来需要对新闻内容进行分词,在分词之前需要导入一些自定义字典,目的是提高切词的准确性。由于文本中涉及到军事、医疗、财经、体育等方面的内容,故需要将搜狗字典插入到本次分析的字典集中。
#添加自定义字典
installDict(dictpath = 'G:\\dict\\财经金融词汇大全【官方推荐】.scel',
dictname = 'Caijing', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\军事词汇大全【官方推荐】.scel',
dictname = 'Junshi', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\篮球【官方推荐】.scel',
dictname = 'Lanqiu', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\旅游词汇大全【官方推荐】.scel',
dictname = 'Lvyou', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\汽车词汇大全【官方推荐】.scel',
dictname = 'Qiche1', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\汽车频道专用词库.scel',
dictname = 'Qiche2', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\医学词汇大全【官方推荐】.scel',
dictname = 'Yixue', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\足球【官方推荐】.scel',
dictname = 'Zuqiu', dicttype = 'scel')
#查看已安装的词典
listDict()
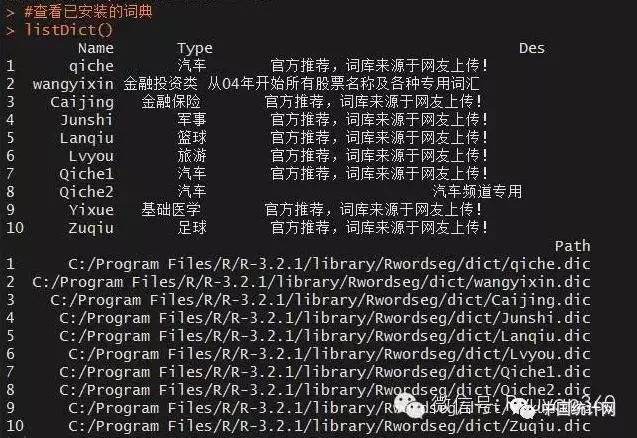
如果需要卸载某些已导入字典的话,可以使用uninstallDict()函数。
分词前将中文中的英文字母统统去掉。
#剔除文本中含有的英文字母
mydata$Text #分词
segword #查看第一条新闻分词结果
segword[[1]]
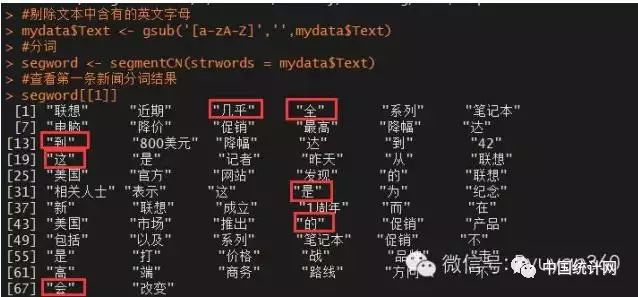
图中圈出来的词对后续的分析并没有什么实际意义,故需要将其剔除,即删除停止词。
#创建停止词
mystopwords head(mystopwords)
class(mystopwords)
#需要将数据框格式的数据转化为向量格式
mystopwords head(mystopwords)
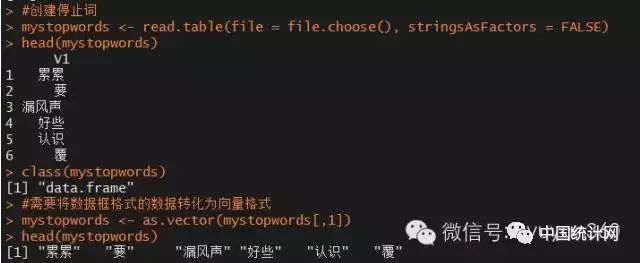
停止词创建好后,该如何删除76条新闻中实际意义的词呢?下面通过自定义删除停止词的函数加以实现。
#自定义删除停止词的函数
removewords target_words = target_words[target_words%in%stop_words==FALSE]
return(target_words)
}
segword2 #查看已删除后的分词结果
segword2[[1]]
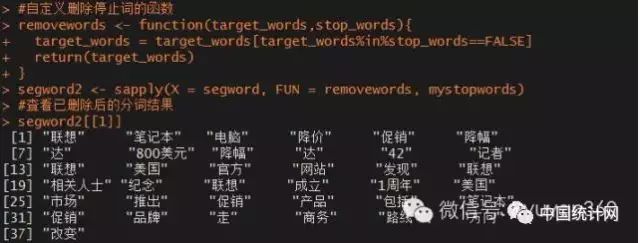
相比与之前的分词结果,这里瘦身了很多,剔除了诸如“是”、“的”、“到”、“这”等无意义的次。
判别分词结果的好坏,最快捷的方法是绘制文字云,可以清晰的查看哪些词不该出现或哪些词分割的不准确。
#绘制文字图
word_freq opar par(bg = 'black')
#绘制出现频率最高的前50个词
wordcloud(words = word_freq$Word, freq = word_freq$Freq, max.words = 50, random.color = TRUE, colors = rainbow(n = 7))
par(opar)

很明显这里仍然存在一些无意义的词(如说、日、个、去等)和分割不准确的词语(如黄金周切割为黄金,医药切割为药等),这里限于篇幅的原因,就不进行再次添加自定义词汇和停止词。
#将已分完词的列表导入为语料库,并进一步加工处理语料库
text_corpus text_corpus

此时语料库中存放了76条新闻的分词结果。
#去除语料库中的数字
text_corpus #去除语料库中的多余空格
text_corpus #创建文档-词条矩阵
dtm dtm
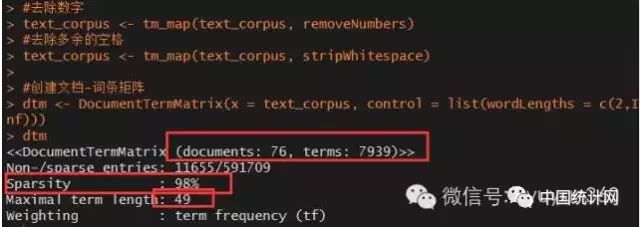
从图中可知,文档-词条矩阵包含了76行和7939列,行代表76条新闻,列代表7939个词;该矩阵实际上为稀疏矩阵,其中矩阵中非0元素有11655个,而0元素有591709,稀疏率达到98%;最后,这7939个词中,最频繁的一个词出现在了49条新闻中。
由于稀疏矩阵的稀疏率过高,这里将剔除一些出现频次极地的词语。
#去除稀疏矩阵中的词条
dtm dtm
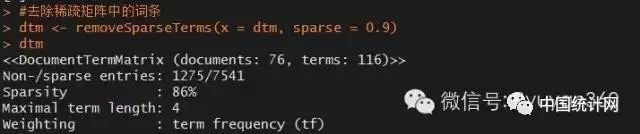
这样一来,矩阵中列大幅减少,当前矩阵只包含了116列,即116个词语。
为了便于进一步的统计建模,需要将矩阵转换为数据框格式。










