
一、马蜂窝“造假门”事件所暴露的行业潜规则
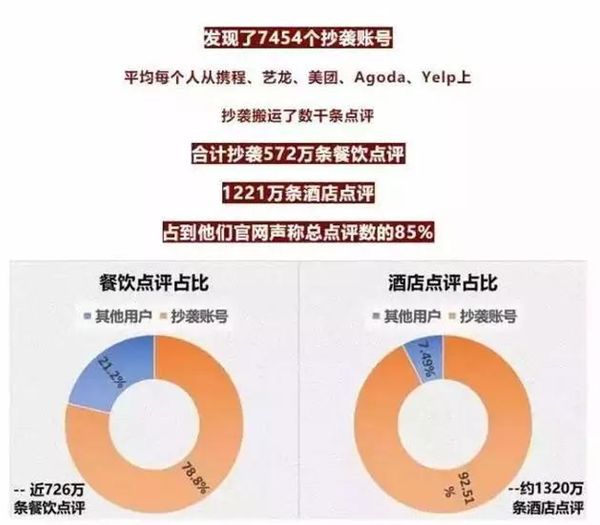
上周,估值据传已高达25亿美元、新一轮融资接近尾声的明星独角兽公司马蜂窝陷入了数据造假丑闻。一个由3名年轻海龟组成不足1年、名不见经传的乎睿数据把马蜂窝涉嫌数据造假的行为逐条拎出来在社交媒体上传播。根据乎睿数据团队提供的信息,马蜂窝2100万条真实点评中,有1800万条是通过机器人抄袭自点评、携程等竞争对手;其在马蜂窝上发现了7454个抄袭账号,平均每个账号从携程、艺龙、美团、Agoda、Yelp上抄袭搬运了数千条点评,占到马蜂窝官网声称总点评数的85%。而马蜂窝则发表声明称乎睿数据“歪曲事实”,属于“有组织攻击行为”,已起诉该公司并获得立案。同时,乎睿数据回应,目前已掌握大量证据,期待法院作出的公正裁决,因为“这个案子最终将决定未来中国二十年的互联网走向”。
本次事件的双方你来我往数个回合,一个认为自己铁证如山,一个咬定“明显抹黑”,唯独真正的“受害者”——被“抄袭”了数据的携程、去哪儿等企业集体陷入沉默。因为当前数据造假、爬虫刷屏是司空见惯的行为,已成为互联网行业的客观现状,携程、去哪儿自身的用户点评数据来源都难以解释清楚。目前,案件最终结果尚未定论,但司法界人士认为,马蜂窝诉乎睿数据的案子具有典型意义。该案件一方面反应了当下企业对于大数据基础性资源的激烈争夺,另一方面也暴露出我国在数据权责安全相关的法制法规建设上亟待加强。
二、“潜规则”背后的技术:网络爬虫与反爬虫
1、网络爬虫技术
爬虫最早源于搜索引擎,它是一种按照一定的规则,自动从互联网上抓取信息的程序,又被称为爬虫,网络机器人等。按爬虫功能可以分为网络爬虫和接口爬虫,按授权情况可以分为合法爬虫和恶意爬虫。如今数据资源越来越珍贵,利用爬虫技术爬取有价值的数据,成为很多公司弥补自身先天数据短板、提高自身估值的不二选择。
针对此次马蜂窝事件,很多开发者承认,从其他网站或APP上抓取点评数据非常简单,在技术上没有任何难度,随便一个爬虫工程师就可以做到。有的开发者说,“不涉及到数据库,直接爬页面就行了”、“可以批量处理,通常是机器+人工编辑”。
很多人好奇报道中称马蜂窝2100万条“真实点评”中,有1800万条都是通过机器人从竞品网站抄袭过来的,究竟是如何做到的。邦盛科技机器防御专家在接受媒体采访时说,目前平台均是通过网络机器人技术从其他网站爬取信息,并抄袭到自己的平台。当前大部分的网络机器人是通过直接发起http请求的方式获取网页资源,无js引擎,会进行一定的伪装,并使用动态IP来躲避反爬虫措施。随着网站防护能力的不断提升,网络爬虫会逐渐向浏览器内核型进化,从而具备执行js的能力,并进一步的拟人化,增加被识别的难度。
目前,爬虫技术已经遍布网络,并且越是涉及个人切身利益的地方,越是布满了爬虫。
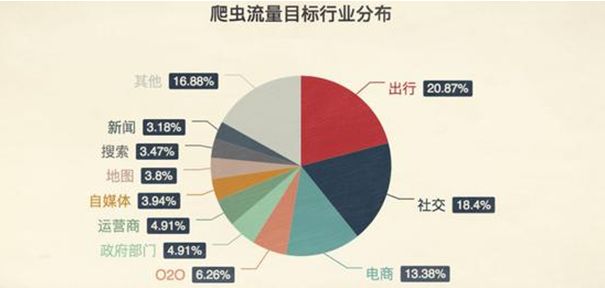
根据之前国外网络安全公司的研究报告,50%左右的网络流量来自网络机器人,遍布各类网站,包括出行、社交、OTA、电商、招聘、银行、政府等。
例如出行类中的12306票务信息被各类抢票软件疯狂地爬取,高峰时刻每天的访问量达到千亿次。在社交类中,通过网络爬虫技术可以指挥一帮网络机器人关注某人的微博、公众号等,进行点赞、关注或者留言,制造大量的僵尸粉。在电商类中,比如在“比价平台”“聚合电商”和“返利平台”等平台上,当用户搜索一个商品时,这类聚合平台会自动把各个电商的商品都放在你面前供你选择,同样利用的是爬虫技术。
此外,马蜂窝所在的OTA领域同样也是爬虫重灾区。某大型互联网公司运营总监表示,尽管不知道马蜂窝被指控的刷评行为是否属实,但业内出现刷评行为的根本原因是出于竞争压力,是几家在线旅游网站出于对UGC(用户生成内容)市场的争夺,以及维护平台活跃度的需要。
一位从事搜索引擎开发的创业者表示,从其他平台抓数据的目的,就是为了制造流量很大的假象,但爬虫抓数据的行为很容易识别,就看资本方尽调的时候是否严格。
2、反爬虫技术
爬虫与反爬虫领域,一直是互联网最激烈的对抗战场之一。
目前,企业经典的对抗方式大概有几种:
图片验证码、滑块验证、封禁 IP、给访问者增加一些加解密运算,耗费爬虫的程序资源等等。除了这些小模块,企业还可以通过 WAF(Web 应用防火墙)来防护,WAF的功能就是通过设置一些规则,拦截掉那些不符合规则的请求。
不过,随着爬虫技术的演进,常规的反爬虫手段已经无法有效阻止爬虫的访问。
据安全专家介绍,近年来通过多维度、多层次的检测,并辅以后端大数据分析来识别网络机器人逐渐兴起并成为主流。
利用设备指纹技术从设备维度定位网络机器人,人机识别技术从操作行为判别机器人点击和自动化点击,而后端大数据实时分析技术可根据长周期数据进行复杂规则决策。综合以上手段,可有效侦测爬虫行为,保护网站的信息资产不被爬取和泄露。
此外,人工智能技术的加入让这场对抗爬虫的常规战逐渐升级为“智能战”,而且战线向云端转移。
此前,腾讯云鼎实验室通过深度学习技术对海量真实恶意爬虫流量进行分析,认为将 AI 技术引入反爬虫领域能起到极好的补充效果,将是未来此类对抗领域的趋势所在。目前,腾讯云网站管家(WAF)联合云鼎实验室基于海量真实爬虫流量建立更为通用的爬虫识别模型,已卓有成效。除了腾讯云,还有很多其他的云安全厂商,也开始主推反爬虫的技术。
三、如何解决行业数据造假的普遍现状?
事实上,任何新技术在引导行业变革时,由于自由发展,最开始都会出现一片乱象。唯有相关法律法规的健全,才会对所有从业者行为有所规范,才会对行业的健康发展保驾护航。
目前,国家并没有一项明确法律条文规定爬虫刷屏是否违法。不过,由于搜索引擎的存在,所以爬取已经允许公开的数据应该是合法的。搜索引擎领域一直遵守的是Robots协议。搜索引擎的原理是通过一种爬虫spider程序,自动搜集互联网上的网页并获取相关信息。而鉴于网络安全与隐私的考虑,每个网站都会设置自己的Robots协议,来明示搜索引擎,哪些内容是愿意和允许被搜索引擎收录的,哪些则不允许。搜索引擎则会按照Robots协议给予的权限进行抓取。Robots协议代表了一种契约精神,互联网企业只有遵守这一规则,才能保证网站及用户的隐私数据不被侵犯。
针对此次马蜂窝事件,法律专家认为,如果平台方未经允许把其他平台的客户评论扒来进行商业化运营,这显然是违法行为。
一方面
,内容的作者是用户,发表在平台上就构成了平台的一部分。大量使用其他平台未获授权的内容,而且还有竞争关系,就构成了对其他平台的侵害,这违反了《反不正当竞争法》的第二条:经营者在生产经营活动中,应当遵循自愿、平等、公平、诚信的原则,遵守法律和商业道德。
另一方面
,发布大量虚假信息,误导消费者,又违反了《消费者权益保护法》中关于消费者知情权的规定。该权益在一般情况下可由消费者协会或者是工商管理部门来代替消费者行使,可以依据相关规定对企业进行查处。
另外,我们还能通过类似的事件来发现司法判决的要旨。2016年一审宣判的“大众点评诉百度案”中,大众点评以百度公司大量抄袭、复制自己点评信息的不正当竞争行为,向上海浦东新区法院提起诉讼。








