对蒙昧未开的幼儿、未经世事的少年来说,好奇无疑是把双刃剑,既驱动他们探险求知,也可能让他们遭遇危险。然而,一旦常识已有根基,阅历足以自保,好奇心就成了人生最稀缺、最宝贵的资源。对成年人而言,英语的“好奇心害了猫”(curiosity kills the cat)只是句俏皮话,造成伤害的,十有八九是貌似好奇的贪、嗔、痴,甚至愚昧,不是“老顽童”的纯真好奇。天资相同(用统计行话说:控制住天资!),好奇心的有无、多寡、强弱、短长,是切实可靠的指标,标示精神力量的大小,正是这力量,驱动人的智力成就在正态分布线上滑动。
听人讲到“数据库”,在电脑屏幕看到数据库,在计量实验室看到电话簿一般厚的“编码本”(codebook),平平的好奇心,也会刺激出一系列疑问。当然,有疑问是一回事,能否克服虚荣,出口发问,另当别论;忍不住发问,能否得到可以听懂的回答,更须另当别论。我比较虚荣,当然也许只是内向,很少问人,但常常问自己。下列问题,都曾令我大惑不解:什么是数据?“数”和“据”放在一起是什么意思?data不是材料、素材吗,怎么变成数据了?data是复数,为什么不用单数datum?单数的datum(数据点)是什么?罗素的逻辑经验主义有个关键术语,sense data(感觉材料),能不能译成“感觉数据”?什么是数据库?数据库的“库”是超市仓库的“库”、图书馆书库的“库”,还是堆放矿石的露天仓库的“库”,或者干脆是“矿”而非“库”?电脑屏幕上的数据库,纵横交错的格子里密密麻麻都是数字,怎样才能看懂它(how to make sense of it)?
SPSS及其雇员数据
方法论讲起来很热闹,听起来很好玩,但是如果不实际应用,就只是看热闹,学不会。很多研究方法,就像数学,一听就懂,一做题就错。学游泳,不管教练多么高明,只听讲,不下水,永远学不会;学做菜,不管师傅多么开明,只听讲,不下厨,永远学不会。学统计分析,像学游泳,也像学做菜。关于统计分析的视频课不少,但只相当于电视上的厨艺节目;书店里系统的统计教材很多,但也只像琳琅满目的菜谱。本书的最高范本,是陆文夫先生的《美食家》,用文字调动馋虫,让馋虫驱动好美食的人下厨。要学做菜,得亲自下厨,真刀实料,做好了,自己先品尝。这一章介绍的,一是SPSS统计软件,是装备齐全的厨艺工作坊,锅灶俱备,炊具齐全,菜谱(recipe)完备;二是SPSS自带的一个数据,相当于食材。
SPSS是缩写,全称是Statistical Package for the Social Sciences,为社会科学量身定做的的统计软件包。在流行的统计软件里,它最早采用Windows介面,易学好用。当然,因为容易学,常被以专家自居的人认为是业余水平的工具。对此,我不介意,业余水平,也是很高的水平,票友的水平,未必比专业差。我讲课,一直用SPSS。除了图省事,也有理论根据:无论学什么,除非是超天才,像莫扎特那样出手不凡,否则总是先业余,后专业。一开始就以“专业人士”自居,摆出“专家”姿态,是自套枷锁,自讨苦吃。有的学生把SPSS叫做“斯巴思”。这个名字好,德语词Spaß(施巴斯),意思就是好玩、乐趣、开心,跟英语的fun等同。当然,开会或者写论文,不妨声称自己是使用Stata,甚至R。统计软件,越难学的越灵活,越好学的越死板。专家用户喜欢Stata,因为它内码开放,用户可以自己写程序,还可以卖程序。有的老师喜欢用很专业的软件教初等统计分析,我有保留。我看过一个中央电视台的书法节目,有个书法家用《九成宫醴泉铭》讲欧体楷书,开篇就讲一个“青”字写得不规范,很怪诞,显然是玩深沉。
SPSS的中文教程很多,都能用,都不简明,让人头大。SPSS的英文用户手册更吓人,十来个软件包,每个软件包一本手册,每本编写得像百科全书,面面俱到,包罗万象,像原始森林,漫无目标地探索,很容易迷路。这一章提供一张SPSS主要功能的极简图。自学统计分析,务必以实用为导向,需要什么,就学什么;不妨遵循林副主席的教导:“急用先学,立竿见影”,其他一概忽略不计。学研究方法,实用主义是不二法门。微软的WORD,超过90%的功能,是我们平常不用的。用文艺点儿的话说,对待任何方法,都得认真兑现宝玉对林妹妹的承诺:“任凭弱水三千,我只取一瓢饮。”
SPSS是完整的统计软件,录入数据、转变数据、分析数据、制作图表,各种功能应有尽有,包打天下。SPSS的菜单跟微软的WORD(Microsoft Word)非常接近,最左边的选项是“文件”(file),“文件”下第一个选项是“新建”(new),又有四个子选项:第一个是“数据”(data),第二个是“句法”(syntax),即指令,第三个是“输出”(output),就是分析结果,第四个是“脚本”(script)。毫不奇怪,这里有个术语障碍。搞专业的人喜欢给非专业的俗人(layman)立障碍、设绊子,好像生怕别人掌握自己的专业知识。syntax在英文里指句法,这里指“命令”或“指示”。(Stata把指令命名为do file,操作文件,比较好懂)。至于script指什么,我现在也不清楚,从来没用过。结论:专家求严谨,创造“黑话”,我们只求会用,要把术语转换成日常语言,把“黑话”变成“白话”。
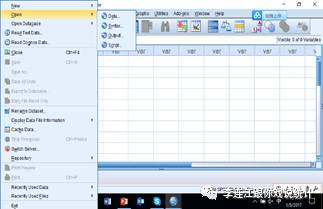
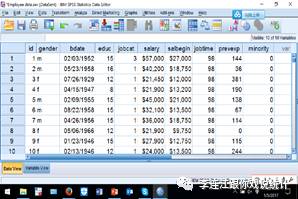
第一,新建数据文件,就是录入数据(data entry),说得堂皇些,就是构建新数据库。选择“data”。先输入变项信息,例如,受访人编号:ID。变项信息包括“名称”、“类型”、“标签”、“值”、“缺失”、“测量”等信息。温馨提示:构建新数据库(以及每次转变数据),要耐心细致地把这些后台信息准确完整地输入,不能马虎,否则真正做数据分析时很容易出问题,浪费很多时间。这些信息里面最重要的是变项名称,要简明易记。不要拖延,一拖就忘,忘了再回忆,事倍功半。做计量分析,千头万绪,千万不要过分相信自己的记忆力。
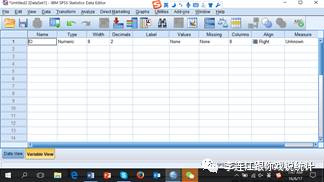
把全部变项信息输入完以后,开始根据问卷调查结果和编码,逐一输入收集的信息。例如,第1号受访人:1。“1.00”看起来有点怪。SPSS默认精确到小数点后两位,可以在变项视图修改。
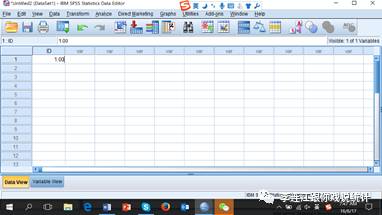
数据录入很容易出错,所以需要清洗数据(data cleaning)。检查数据是否干净,最简便的办法就是看看频次表,看有没有异常值。发现异常,就得查找原始问卷核对。大型调查,往往找很多人分别录入数据,最后要“合并文件”(merge files),需要格外小心。我有次帮朋友分析数据,觉得结果很怪诞,怀疑是数据合并时出了错,复核了一下,果然有错。
第二,已经建好的数据文件,有两个视图。SPSS有个自带的雇员数据,很简单,很好玩。雇员数据(Employee Data)在这里。
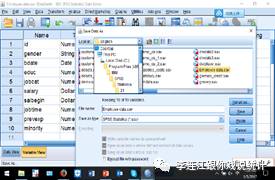
数据库分前台与后台。data view,数据视图,相当于前台,SPSS程序读的是这些数字,计算机只懂得数字。从左往右看,每一行记录一个案例(case),也就是一个个体,或客体,或主体,或对象,SPSS称之为观测或观察(observation)。从上往下看,每一列记录一个variable,变项。这个数据是雇员数据,从左往右的一行,是一个雇员(非雇主),记录了九个属性,性别、年龄、教育程度、工作岗位,等等。这九个属性,构成一个观察,一个个案。
变项视图,variable view,相当于后台信息,告诉我们数据库的数字到底是什么意思,是研究者的备忘录。
第三,转变数据(data transformation),相当于做菜时切菜。重新编码,取对数,算平方,都是切菜。把数据库比作数据矿,开采出的原矿石如果块儿太大,冶炼前得先打碎。把数据分析比作做菜,做菜还讲刀工,把菜切好。切法很多,每个切法都有菜单。最常用的是“重新编码”(recoding)。例如,设计问卷时,为了避免“引导”应答人,问:“你对这个事情是很满意、满意、不满意、还是很不满意”。为了减少数据录入出错的概率,把四个答案依次编号,1,2,3,4。但是,分析数据时,我们关心的是满意度,按照我们习惯的思维方式,关心满意度,那么最大数字就标记最满意。这时,可以重新编码,把原来的编码颠倒过来,把1,2,3,4,分别改为4,3,2,1。信息没有变,处理的时候不容易把自己绕进去。两个温馨提示。第一,保留原来的数据,尽量不要使用“recode into same variables”,因为这个功能会覆盖原始数据。原始数据务必单独保存,所以,覆盖了也不是世界末日,不过,还是尽量避免麻烦,使用recode into different variables。第二,及时更新变项标签等后台信息。计算新变项(compute variable)也常用,例如,数据中有年龄这个变项,为了检验年龄与某个因变量是否曲线相关,要用年龄的平方,这时候用“计算”来生成一个新的变项。举个具体例子,人从小到老,从零岁到一百岁,需要的关照量跟年龄是U形曲线相关:很小时,需要很多照顾;在一个转折点前,年龄越大,需要的照顾越少;但是,过了某个转折点,年龄越大,需要的照顾越多。构建简单相加量表(simple summation index)时,也需要用“计算新变项”这个功能。
第四,graphs,制图。第一个选项是“图构建程序”(chart builder)。还有一个是“遗产对话”(legacy dialogs),就是较早版本的制图菜单。新版本的菜单功能强大,自然就比较啰嗦。SPSS比较体谅年龄大、不愿意学新东西的用户,比如本人,把这些画图命令保留下来了。当然,称其为legacy,也许不无调侃之意。
最后,analyze,分析。分析菜单像菜谱(recipe)。比如,做红烧肉,有若干步骤。常用的菜谱是“描述统计”(descriptive statistics),常用的功能是“频率”(frequencies)、“描述”(descriptives)和“交叉列表”(crosstabs)。“回归”(regression)是家常菜。把regression这个词译成“回归”是没有道理的,第四章有专门讨论。此外,我会简单介绍因子分析(dimension reduction)、量表构建(scale)以及这里看不到的结构方程模型(structural equation modeling)。
学术中国的知深网站有关于SPSS操作的视频,可以参考。教SPSS的教材很多,培训班很多,视频课也很多,大同小异,觉得哪个好玩,就用哪个。统计分析技术枯燥无味,学的时候追求点趣味,十分必要。
雇员数据详解
1、样本量与变项量
重复一句,数据库,从左往右是一行,row,记录一个个体,第一行记录是第一号人,第二行记录是第二号人。雇员数据共474行,记录了474个员工的一串情况。样本量474,N=474。雇员数据中包括了474个员工的信息。当然,雇员数据是样本,言外之意,这个企业肯定不是只有这474人,我们可以设想这是个很大的企业,员工上万、十万。这474人只是个概率样本。
原始雇员数据一共10列,每列是一个变项,是雇员的一个侧面。下图是我加工过的数据图。原始的10个变项排在前面。
数据视图。
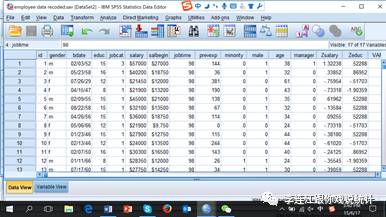
变项视图。
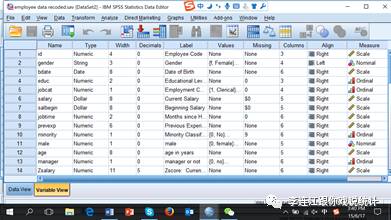
第1列,变项名,ID,变项标签,employee code,雇员编码。这个编码是抽样时随机指定的,没有实质意义,但必不可少,一是录入问卷发生错误可以根据这个编码纠错,二是可以用来构建多层数据。
第2列,变项名,gender,变项标签,gender,性别。男性标记为M,女性标记为F。
第3列,变项名,bdate,变项标签,date of birth,生日,采用美国的特有记录法:月/日/年。IBM系统以前要求文件名不超过8个字节,所以变项名称必须简略。现在的SPSS已经没有这个限制,但我们还是习惯于尽量缩短变项的名称。
第4列,变项名,educ,变项标签,educational level (years),教育程度(以年为测量单位)。测量单位是年,所以,教育程度变化一个单位,就是增加一年或减少一年。定比层级测量。
第5列,变项名,jobcat,变项标签,job category,工作类型或工作岗位。这个变项有三个取值,“1”标示普通职员(clerical),“2”标示保管或保安(custodial),“3”标示经理(manager)。这里的1、2、3表面看起来是数字,我们也可以认为3大于2,2大于1,但不能认为3跟2之间的距离和2跟1之间的距离相等。保管或保安的平均工资比普通职员高一些。我们可以设想这个公司是超市,普通员工可能就是管收钱的,保管或保安的责任大一些。
第6列,变项名,salary,变项标签,current salary,现时年薪。测量层级是定比,测量单位是美元/年,即,年薪变化一个单位,就是每年增加一美元或减少一美元。
第7列,变项名,salbegin,变项标签,beginning salary,起始年薪。
第8列,变项名,jobtime,变项标签,months since hire,在本公司的工作月数。
第9列,变项名,prevexp,变项标签,previous experience (months),来这家公司工作以前的工作时间(以月为测量单位)。
第10列,变项名,minority,变项标签,minority classification,是否少数族裔。1=是;0=否。
把行与列一起读,就读出了数据库的一条条信息。例如,第一行的信息如下:第一号雇员,男,生于1952年2月3日,上过15学,经理,年薪57000美元,在公司工作了98个月,到这家公司以前有144个月的工作经历,非少数族裔(白人)。这条长信息,由九个单一数据(datum)或信息点(data point)组成。每条单一信息的句法相同:主语(第一号雇员),系词(是),宾语(行与列交叉格的信息)。例如,第一条:第一号雇员是男性;第二条:第一号雇员的生日是1952年2月3日。每一行构成一个观察(observation),即个案或案例(case)。
我对原始雇员数据做了点加工,转变了三个变项,依次解释如下。
第11列,变项名,male,变项标签,male(男性)。这个变项是对原始变项gender的重新编码,把变项名gender改为male(男性),男性=1,女性=0。温馨提示:为性别变项命名,可以把自己重点关注的性别标记为1,作为参照的性别标记为0,这样容易记住变项的内容。比如,如果关心的是性别由“女”变为“男”对于年薪的影响,就是以女性的状况为参照,以男性的状况为观察点,就应该把变项定义为“男性”,看到“1”,就知道是“男性”。如果自变项“男性”与因变项“年薪”的回归系数是正数,例如1000,就知道意思就是“当性别从女性变为男性时年薪会增加1000美元”。当然,这里的“变”是因人而异的变,不过我们感兴趣的是可能世界中一个个体“日新月异”的变。所以,这个回归系数应该读为:相对于女性雇员而言,男性雇员的年薪高1000美元。
第12列,变项名,age,变项标签,age(年龄)。原数据的生日,无法直接分析。我假定调查是1990年1月1日做的,计算出年龄。提供转换公式的网页很多,例如:https://kb.iu.edu/d/acya。
第13列,变项名,manager,变项标签,manager(经理)。我把jobcat这个变项改造了manager,经理=1,非经理=0,做法是把原始数据里的1和2重新编码为0,3重新编码为1,使用“recode into different variables”。
2、实质相干的变项
雇员数据收集了雇员九方面的信息。为什么是这九个?为什么没有收集其他信息?一定是根据定性研究。比如,定性研究发现:人生在世,无论男女,无论肤色,必须有生活资源,为了获得资源,必须工作,为了找工作,必须接受教育。对这个现象进行分析,我们就确定了人类社会生活的一些基本属性,比如,性别,教育,分工(工作类别),年薪,种族。需要提醒一句,这些属性的鉴别与界定,貌似常识,但追根溯源,都依靠定性研究。
我们观察一个公司的雇员,注意到我们感兴趣的三个现象。第一,有人年薪高,有人年薪低;我们对此有兴趣,因为人人都愿意拿高年薪,换言之,年薪高低并非自主选择,也不是全凭运气(随机),有系统原因。第二,同是雇员,有人是经理,有人不是经理。第三,同是雇员,有人教育程度高,有人教育程度低。
从社会科学角度看,雇员数据中的这三个变项是实质相干的变项,可以作为定量研究的因变项。第一,年薪。钱很重要,“钱不是万能的,没有钱是万万不能的”。这就是实质相干。我们观察到年薪因人而异,有兴趣了解造成差异的原因,猜测是因为教育程度不同,进而猜测教育程度与年薪的关系是水涨船高,正相关。参见第四、第五章。
第二,是否经理。权是经理岗位,经理有权。经济管理学可以以是否经理为因变项。参见第六章。
第三,教育程度。教育学以教育程度为因变项。
3、理论上相关的变项
选定了实质相干的因变项,下一步是根据现有理论和研究兴趣选自变项。从社会科学角度看,以年薪为因变项,至少有四个理论上相关的变项可以作自变项。第一,性别。研究假设是,男性比女性年薪高。男女同工同酬,pay equity,在很多国家仍然只是个理想。对男女平权有兴趣,可以分析性别对年薪的影响。
第二,教育程度。研究假设是,教育程度越高,年薪越高。事实是否与理论相符,需要验证。有人可能觉得这个假设不是假设,学历高工资高是理所当然,其实不一定。九十年代,我国就出现过所谓“脑体倒挂”现象,形象的描述是“搞导弹的不如卖茶叶蛋的”,“博士最傻,教授最穷”。详见第三、第四章。
第三,是否经理。经理工资高,可以算是天经地义,所以,这个自变项,主要是被用作控制变项。详见第五章。
第四,族裔。研究假设是,族裔分类对收入有影响。在美国,白人是多数,亚裔、拉丁裔、非裔这些是少数族裔。少数族裔年薪,与白人年薪,是相同、较高、还是较低?这个问题值得研究。
4、请问这是什么东西的案例?
做定性分析的人,经常遇到一个挑战。开会报告论文,讲了一个案例,听众常问,你这个案例是什么东西的案例。如果没有准备,往往答不上来。原因是,我们有时太醉心于自己的故事,觉得故事的每个方面都重要,结果就分不清轻重。分不清轻重,就不知道我们讲这个故事到底想说明什么。比如,雇员数据中有474个雇员的信息。如果专门研究其中一个人,那就是做了一个个案研究。我们如果做个案调查,细致了解了他很多方面的情况,远远超过数据里的九个侧面,还有很多,例如,身高、体重、婚姻状况、子女状况、父母状况、成长经历、兴趣爱好。有人问,这个个案是个什么东西的个案?我们就可能卡壳。要顺畅回答这个司空见惯然、又有三分挑衅的问题,采用定量思维分析方式很有用。定量分析,至少需要一个因变项,一个自变项。只要有一个因变项,一个自变项,就有了一个研究假设,也就有了一个好答案。换言之,每个研究假设,都是对于这个问题的答案。比如,你关心年薪,年薪是因变项,你关心教育程度对年薪的影响,教育程度是自变项。你的案例就是司雇员教育程度与工资之间关系的案例。
上述讨论,是假定我们已经清楚一个分类,即“雇员”(employee)与“雇主”(employer)。这个分类,也是定性分析的结果,不能视为当然(taken for granted)。在这个语境下,我们遇到那个有点挑战性的问题,可以给出更多答案,例如,这个个案是个雇员的个案;是雇员年薪的个案;是雇员教育程度与其年薪的关系的个案;是雇员的教育程度在控制了族裔、工作岗位的影响后如何影响年薪的个案;是雇员是否任经理的个案;是雇员教育程度影响任经理的概率的个案;是雇员的教育程度在控制了性别、族裔、工作岗位的影响后如何影响任经理的概率的个案。回答得越细致,越具体,说明定性研究越深入,越有明确的目标。
回顾一下,我们会发现我们对雇员数据的看法已经发生了变化。一开始看雇员数据,看上去都是数字,越往后,我们在数字中看到的信息越多。康德说,认识世界,既需要感知,也需要概念。变项、测量,都是概念。概念组成思维方式。学统计分析,就是通过掌握概念形成统计的思维方式。





