作为一个高维度的分布式机器学习框架,Angel 的第一次对外亮相是在去年的五月,并在去年 12 月份 KDDChina 大会上,宣布将全面进行开源。为了迎接对外开源,团队成员对 Angel 进行了多次重构和升级。在此期间,Angel 的架构反复改进,性能持续提升。开源前夕,它的性能已经超越了 XGBoost 和 Spark。
经过腾讯漫长的准备和打磨,新一代的 Angel 终于开源了。新一代的 Angel 由腾讯和北京大学联合开发,兼顾业界的高可用性和学术界的创新性,面向
分布式架构师,算法工程师和数据科学家
,希望能激发机器学习领域更多的创新应用和良好生态。Github 传送门:https://github.com/tencent/angel。
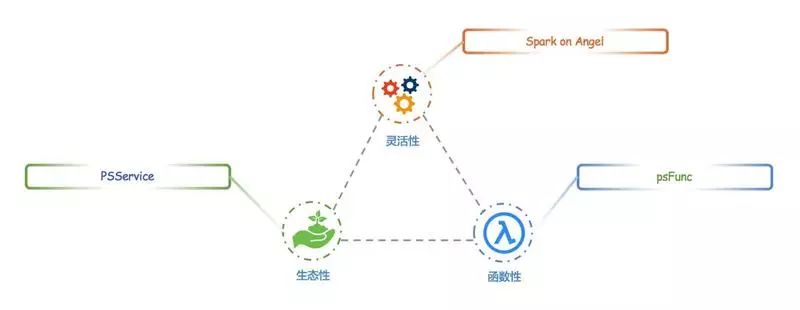
新一代的 Angel,改进主要集中在三方面:
-
生态性
: 引入 PSAgent,支持 PS-Service,便于接入其它机器学习框架
-
函数性
: 融合函数式编程特性,自定义 psFunc,利于开发复杂算法
-
灵活性
: 支持 Spark-on-Angel,Spark 无需修改内核,运行于 PS 模式之上
本文将从
架构
和
性能
两方面,对新一代 Angel,做一个初步的介绍,让大家了解它的改进。关于更加具体和深入的介绍,还请移步 GitHub。
在新一代的 Angel 开发中,我们对系统进行了一次重要的升级,引入了 PSAgent,对 PSServer 的服务端进行隔离,从而提供了 PS-Service 的功能。升级后,系统的架构设计如下:

引入 PSAgent 后,PSClient 不再直接和 PSServer 打交道了,而是通过 PSAgent 来沟通。作为新加的中间层 PSAnget,有如下几个特性:
-
对外屏蔽了 PSServer 中的
模型分片,路由以及模型重组
等复杂细节,提供了封装好的
模型操作
接口
-
内置了
Hogwild!
机制,包含
模型缓存和模型预取
等性能优化
-
提供了
模型缓存(Cache)
的
更新
和
合并
的功能,大大降低网络通信开销
PSAgent 的引入,解耦了 PSServer 和 Worker,使得 Angel 具备了 PSService 的能力。Angel 的 PSServer,不再只服务于 Angel 的 Client,其它机器学习框架,只要实现 AngelPSClient 接口了,都能可以接入 Angel。
PSService 的抽象,为 Angel 接入 Spark 和深度学习框架,从架构的层面上提供了便利
标准 Parameter Server 功能之一,就是要提供 Model 的
拉取(pull/get)和推送(push/update)
。 很多早期 PS,拿 HBase,Redis 等分布式存储系统,简单改改,进行模型的更新和获取,就搭建了一个简单的 PS 系统。
但实际应用中,算法对 PSServer 上的参数获取和更新,却远远不只这么简单,尤其是当复杂的算法需要实施一些特定的优化的时候,简单的 PS 系统,就完全不能应对这些需求了。
举个例子,有时候某些算法,要得到矩阵模型中某一行的最大值,如果 PS 系统,只有基本的 Pull 接口,那么 PSClient,就只能先将该行的所有列,都从参数服务器上拉取回来,然后在 Worker 上计算得到最大值,这样会产生很多的网络通信开销,对性能会有影响。而如果我们有一个自定义函数,每个 PSServer 在远程先计算出 n 个局部最大值,再交换确认全局最大值,这时只要返回 1 个数值就可以了,这样的方式,计算开销接近,但通信开销将大大降低。
为了解决类似的问题,Angel 引入和实现 psFunc 的概念,对远程模型的获取和更新的流程进行了封装和抽象。它也是一种用户自定义函数(UDF),但都和 PS 操作密切相关的,因此被成为
psFunc
,简称
psf
,整体架构如下:

随着 psFunc 的引入,模型的计算,也会发生在 PSServer 端。PSServer 也将有一定的模型计算职责,而不是单纯的模型存储功能。合理的设计 psFunc,将大大的加速算法的运行。
作为目前非常流行的分布式内存计算框架,
Spark
的核心概念是 RDD,而 RDD 的关键特性之一,是其不可变性,它可以规避分布式环境下复杂的各种奇奇怪怪的并行问题,快速开发各种分布式数据处理算法。然而在机器学习的时代,这个设计反而制约了 Spark 的发展。因为机器学习的核心是迭代和参数更新,而 RDD 的不可变性,不适合参数反复多次更新的需求,因此诸多 Spark 机器学习算法的实现,非常的曲折和不直观。
现在,基于 Angel 提供的
PSService
和
psFunc
,Spark 可以充分利用 Angel 的 PS,用最小的修改代价,具备高速训练大模型的能力,写出更加优雅的机器学习算法代码。
Spark on Angel 实现的基本架构设计如下:

可以看出,该实现非常灵活,它对 Spark 没有任何侵入式的修改,是一种插件式设计,因此完全兼容社区 Spark,对原生 Spark 的程序不会有任何影响。它的基本执行流程如下
-
启动 SparkSession
-
初始化 PSContext,启动 Angel 的 PSServer
-
创建 PSModelPool, 申请到 PSVector
-
核心实现:
在 RDD 的运算中,直接调用 PSVector,进行模型更新。这将使得真正运行的 Task,调用 AngelPSClient,对远程 PSServer 进行操作。
-
终止 PSContext
-
停止 SparkSession
关于 Spark on Angel 的具体开发,可参考:《Spark on Angel 编程手册》 (https://github.com/Tencent/angel/blob/branch-1.0.0/docs/programmers_guide/spark_on_angel_programing_guide.md)。在线上,基于真实的数据,我们对 Spark on Angel 和 Spark 的做了性能对比测试,结果如下:
|
LR 算法
|
Spark
|
Spark on Angel
|
加速比例
|
|
SGD LR (step_size=0.05,maxIter=100)
|
2.9 hour
|
2.1 hour
|
27.6%
|
|
L-BFGS LR (m=10, maxIter=50)
|
2 hour
|
1.3 hour
|
35.0%
|
|
OWL-QN LR (m=10, maxIter=50)
|
3.3 hour
|
1.9 hour
|
42.4%
|
显而易见,Spark on Angel 能轻松获得 30% 或更多的加速比,越复杂的算法和模型,性能提高的比例越大。虽然 PSServer 会耗费了额外的资源,但是比起
算法编写的便捷
和
性能的提升
,这是划算的。对于 Spark 的老用户,这是低成本切入 Angel 的一个途径,也是算法工程师基于 Spark 实现高难度算法的优雅姿势。
Spark on Angel 是 Angel 生态圈的第一个成员,后续会有更多基于 PS-Service 的框架接入,包括深度学习
新版本的 Angel,添加了诸多新功能,最终的目的,就是让算法工程师能更加从容地进行算法优化,融入更多的算法的 Trick,让算法的性能,得到了一个飞跃的提升。
为了更加直观的看到性能差异,每个对比都在腾讯的机器学习平台 TeslaML 上,提供了工作流的链接,鹅厂工程师都可以观察到运行结果。
众所周知,XGBoost 的强项之一,就是 GBDT 算法,性能飞快,使用简单,在众多算法比赛中,是选手们的最爱。尽管如此,Angel 的 GBDT 算法,却还是超越了它,这是一个非常不错的性能背书。

|
框架
|
Worker
|
PS
|
建立 20 棵树时间
|
|
Angel
|
50 个 (内存:10G / Worker)
|
10 个 (内存:10G / PS)
|
58 min
|
|
XGBoost
|
50 个 (内存:10G / Worker)
|
N/A
|
2h 25 min
|
众所周知,LDA 是一个非常消耗资源的主题模型算法,新一代的 Angel,在 LDA 上的性能,不但超越了 Spark,也已经超越了之前开源过的 Petuum。(由于 Petuum 已经不开源多时,所以比对数据,这里就不再贴出了)

|
框架
|
Worker
|
PS
|
时间
|
|
Angel
|
20 个 (内存:8G/Worker)
|
20 个 (内存:4G/PS)
|
15min
|
|
Spark
|
20 个 (内存:20G/Worker)
|
N/A
|
>300min
|









