机器之心原创
作者:Shawn
参与:Ellen Han、黄小天、王灏
不久之前,Wenzhe Shi 等人在 arXiv 上发表了一篇名为《通过高效的子像素卷积神经网络实现实时的单一图像和视频超分辨率(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network)》的论文,机器之心海外分析师团队从多个方面对其做了解读。
论文地址:https://arxiv.org/pdf/1609.05158.pdf
论文实现:https://github.com/torch/nn/blob/master/PixelShuffle.lua

前言
单一图像/视频超分辨率的目标是从单一低分辨率图像还原出高分辨图像。论文作者提出了一种可以高效计算的卷积层(称之为子像素卷积层(sub-pixel convolution layer))以便将最终的低分辨率特征映射提升(upscale)为高分辨率输出。通过这种方式,而不是使用双线性或双三次采样器(bilinear or bicubic sampler)等人工提升滤波器,子像素卷积层通过训练可学习更复杂的提升操作,计算的总体时间也被降低。相比于原始输入图像/帧,你需要做的只是定义一个重建损失(reconstruction loss),并进行端到端的训练。

如上所示,有一个单一图像超分辨率的实例。左图基于双三次提升滤波器(bicubic upscaling filter),右图基于提出的模型。很明显,相较于左图,右图更清晰,且背景噪音更少。
之前,单一图像超分辨率基于高分辨率空间,这有一些主要缺点:一方面,处理卷积操作时,如果你首先提升低分辨率图像的分辨率,计算时间将增加;另一方面,从低分辨率空间到高分辨率空间的转化基于传统插值(interpolation)方法,这也许不会带来解决病态重建问题的额外信息。
提出的模型
考虑到这些不足,作者假定我们可在低分辨率空间进行超分辨操作;基于这一假定,他为一个有 L 层的网络构建了子像素卷积层,该网络可正常学习 n_{L-1} 个特征映射,但最后,网络通过「像素洗牌」(pixel shuffle)实现高分辨率输出,接着完成一个更复杂的从低分辨率到高分辨率的映射,这是一个简单而直接的想法。
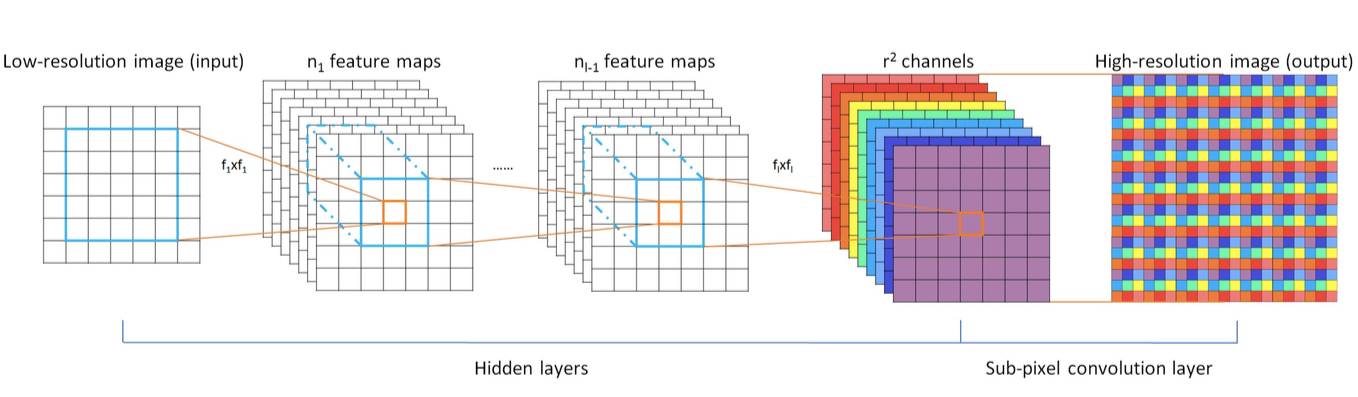
上图是从低分辨率图像映射到高分辨率图像的整个模型。如上所示,他们应用第 l 层子像素卷积将 I_{LR} 特征映射提高到 I_{SR}。
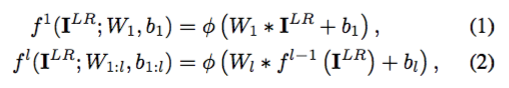
上面的公式是该网络的数学描述,其中 W_l, b_l, l ∈ (1, L - 1) 分别是可学习的权重和偏差(bias)。W_l 是大小为 n_{l-1} x n_l x k_l x k_l 的二维卷积张量,其中 n_{l-1} 是层 l-1 中特征映射的数量,n_l 是层 l 中滤波器的数量,k_l 是滤波器大小,b_l 是偏差向量。非线性函数 φ 被应用在元素方面(element wise)。
在最后一层进行提升操作。一个提升低分辨率图像的方式是使用大小为 k_s 的滤波器和权重间隔 1/r ,在低分辨率空间卷积 1/r 步幅,当落在像素之间的滤波器的权重没有被简单计算时,这一卷积操作可激活滤波器的不同部分。为了建模这一操作,作者给出了一个数学公式:
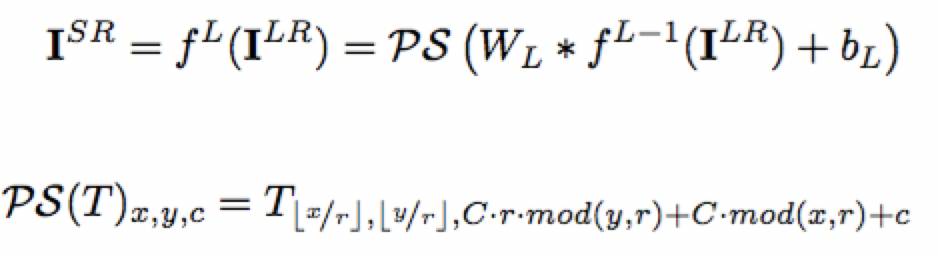
其中 PS 指周期性像素洗牌,这可将输入张量 C * r^2 x H x W 重排为锐化张量 C x rH x rW。这个操作的效果已显示在上图中。




