
【CDAS 2017 数据体验票】
C君带你进会场,5张499元门票任性送,优惠码“mJdUIew”,凭此优惠码即可“0元”购买本次峰会价值499元的数据体验票一张。
数量有限,先到先得。(会议详情点下图,报名点阅读原文)
(说明:本票为数据体验票,仅限499元数据专场。含大会全天论坛及企业创新体验展,不含午餐;提供大会精美礼品一份;大会前排坐席)

原作者
Mirek Stanek
编译 CDA 编译团队
本文为 CDA 数据分析师原创作品,转载需授权
本月 23 日- 27 日,在乌镇主办“中国乌镇·围棋峰会”中,备受瞩目的要数中国围棋现役第一人、天才少年柯洁与
Google
AlphaGo(阿尔法狗)人工智能机器人的巅峰对决。AlphaGo与柯洁对弈的三局比赛,分别于 5 月 23 、25、27 日进行。
在 23 日和 25 日的对决中,柯洁虽然发挥神勇,但还是两局均战败。AlphaGo 2-0 领先,已经赢得了三番棋的胜利。
对于人类来说,这看上去不太妙。
那么,AlphaGo 究竟是什么?关于 AlphaGo 我们需要了解些什么呢?
AlphaGo 是由 Google DeepMind 开发的围棋程序
,并在2015年欧洲围棋锦标赛中它以 5:0 赢得了樊麾,在历史上第一次打败顶尖职业围棋选手。
在 AlphaGo 出现在公众视野之前,有人预测根据如今的科技水平出现具有 AlphaGo 水平(击败人类职业棋手)的人工智能大约还需要 10 年的时间。
早在 20 年前,人工智能就在国际象棋上战胜了人类,而东方古老的围棋似乎成了人类最后的坚持。
但事实让人类失望了。
一切皆关于其复杂性。

围棋和象棋都是完全信息博弈游戏
,这意味着每个玩家都完全清楚之前发生的所有事件。而完全信息博弈,通常能被简化为寻找最优值的树搜索问题。它含有 b 的 d 次方个可能分支,在国际象棋中有 b≈35,d≈80,即10¹²³ 种;而在围棋中 b≈250,d≈150 即10³⁶⁰ 种。多核兆赫处理器一般可以每秒钟进行 10⁹ 次操作,这意味着计算所有可能的步数的时间不可估量——数学就是这么残酷。
AlphaGo 的最高目标是有效的减少搜索路径数量,具体是这在合理的时间内( AlphaGo 每一步计算时间为 5 秒),计算出可能的步数(直到游戏结束)。
为了对博弈状态进行预判,AlphaGo 使用蒙特卡罗树搜索(MCTS)——通过对搜索路径的随机抽样来扩展搜索树来分析最可能赢的选项。在博弈游戏中,MCTS 的应用是基于各种玩法,通过随机选择的方式来玩到最后。每一次的结果都被用来对博弈树的节点进行加权,这样更好的节点更有可能在之后的博弈中被选择。
通过额外的策略(例如预测职业棋手的动作)强化 MCTS ,使其达到更强的水平。
进一步的改进则基于良好的预先训练的深卷积网络。这些被广泛应用于图像分类、人脸识别或游戏中。
在 AlphaGo 中使用的神经网络的目标是:有效位置评估(价值网络)和行为抽样(策略网络)。
这也意味着 AlphaGo 的下棋方式除了学习别人的对局外,还可以自己跟自己下棋,通过对不同下法产生结果的分析来改善自己的下棋方式。这也就是说,学习时间长、学习案例好的 AlphaGo 赢的可能性更大一些。
在机器学习中为了训练策略网络,有以下步骤。
第一阶段:
监督学习(SL),即模仿学习。
通过在 KGS (网络围棋对战平台)上最强人类对手,百万级的对弈落子去训练大脑。这就是 AlphaGo 最像人的地方,目标是去学习那些顶尖高手的妙手。AlphaGo 落子选择器能正确符合 57% 的人类高手。(其他研究团队的最高正确率为44.4%)。
第二阶段:
强化学习(RL),即自主学习。
尽管SL策略网络在预测下一步时很有效,但 RL 有助于预测最佳的(获胜)步。在这一阶段,AlphaGo 跟自己对弈,自己训练自己。
强化学习与监督学习策略对决取胜率高达 80% ,与 Pachi 获胜率为 85% ,Pachi 是一个基于蒙特卡罗树搜索法的人工智能,在 KGS 业余段位排名第二。以往 SL 与 Pachi 对决胜率仅为 11% 。
最后阶段的训练集中在位置评估(估计当前步数获胜的概率)。基于 KGS 数据集的训练会导致过度拟合(价值网络倾向于记住游戏结果,而不是采取新的步数),因此避免这一现象,新的训练是进行自我博弈(有 3000 万个不同的位置,每个都从单独的游戏中取样)。
经过训练的价值函数比使用走棋策略的蒙特卡罗更精确,它的单次计算也与使用强化学习的蒙特卡罗的计算更相似(但计算量会少 15000 次)。
AlphaGo 在蒙特卡罗搜索树中使用了策略和价值网络的组合。游戏树在模拟中被搜索,由以下阶段组成:
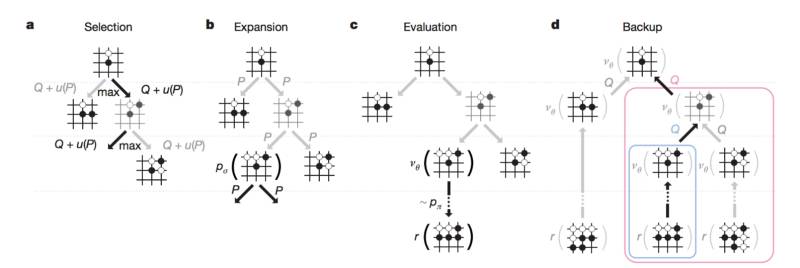
在获取棋局信息后,AlphaGo 会根据策略网络(policy network)探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。在分配的搜索时间结束时,模拟过程中被系统最频繁考察的位置将成为 AlphaGo 的最终选择。在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,AlphaGo 的搜索算法就能在其计算能力之上加入近似人类的直觉判断。










