关键词
:工业APP,知识型APP,知识沉淀,专家规则
工业是一个重机理、知识经验密集的领域,工业APP是工业知识的重要载体形式之一(小而美、轻流程、重知识),这样可以借助工业互联网模式和平台技术实现大规模复用。
但不幸的是,工业APP依赖的核心知识的沉淀并不容易,很多知识经验不能明式表达,明式表达的逻辑也远非完备,完备的逻辑常常也不够精准,当前的精准知识若不演化,也不能保证后续的有效性。
这样,工业知识沉淀速度/成本/质量就成了知识型工业APP发展的瓶颈, 复用更是难上加难。大数据技术的发展为知识沉淀的加速提供了一种可能。但纯数据驱动的统计学习路线并不完美匹配如“变量间高耦合、数据测量/记录不完备、样本类别不均衡”等典型的工业数据特征。
工业知识沉淀还应采用专家知识+数据技术融合的方式。针对这种融合方式,本文以设备运维域为例,阐述工业知识沉淀的挑战和解决方法,提出了经验知识沉淀的7步法(简称AI-FIT-PM),并进一步讨论了支持知识沉淀/复用的基础工业互联网平台架构。文末,结合实践经验,对知识型APP发展给出一些参考建议。
如需更多了解工业互联网的观察和思考,点击👉👉
工业互联网风向观察|专辑
(1分钟
独家
视频首发
工业互联网研习社视频号
)
点击文末图片可关注
视频号
作者|田春华,
北京工业大数据创
新中心,首席数据科学家
来源|工业技术软件化产业联盟

工业APP有很多分类维度,王建民教授
[1]
从产品生命周期的角度论述了工业软件的需求和创新,包括了设计(CAX,PLM等)、制造(MES、ERP等)、使用维修(MRO等)、循环再利用等阶段,并据此工业互联网创新形态可分为设计工业互联网、生产工业互联网、使用工业互联网。基于类似的思路,赵敏
[2]
对工业软件从功能角度做了更加细致的分类。
本文中讨论的
知识型APP是相对于效率型APP
而言的,效率型APP通过多维数据整合、信息及时推送,来提高业务流程效率、办公效率,而知识型APP侧重决策建议的提供,来提高业务决策效率(如设备异常检测、操作参数调整建议等)。效率型APP的开发侧重于软件功能云化、用户体验设计、采集与提升。而知识型APP的重点在于决策知识的融入和及时推送。
何为工业知识?对此,业内专家有了广泛而深刻的阐述。马国钧教授
[4]
在讨论数据、信息、知识、智能、智慧的关系时,有物化知识、显性知识、隐性知识、增量知识等提法。国际经合组织将知识分为Know-what、Know-why、Know-how、Know-who的四种类型。
朱焕亮与徐保文
[5]
认为工业知识包括方法、过程和装置三个要素。
不同要素的软件化产生不同类型的工业软件。方法层面的工业知识软件化后,产生了基于物理原理与专业学科发展的各类专业工具;过程层面的工业知识软件化后,产生了以流程管理为核心的各类业务系统;装置层面的工业知识软件化后,产生了各类嵌入式软件。
杨春晖和谢克强
[6]
认为工业知识包括标准规范、行业流程、知识技能、管理思想等知识。本文的讨论侧重在制造和使用维修这2个产品生命周期
(按照王建民教授
[1]
的提法)
,所以不妨狭义将知识的来源锁定在三类:领域专家、文档资料、数据(如DCS监控数据、MES操作数据等)。这种提法与技术领域的做法(专家系统、自然语言处理、机器学习等)也有一定的对应。
技术方法
知识的自动化和发掘一直是人工智能、统计学习等学术领域关注的技术方向。60年代提出的专家系统是重要的尝试之一。将专家知识进行形式化表达(如产生式规则、语义网络、框架、状态空间等),通过推理机制(正向或反向)进行问题求解,并通过合适的解释和人机交互界面将结果呈现出来。人们曾对此给予了很高的期望,但在实际应用中,大家不断意识到“
专家知识可以明式表达
”这一前提假设过强。
为此,后面逐渐兴起的机器学习(也称统计学习或数据挖掘,包括近年来的深度学习)这一技术路线,尝试从数据(专家操作/决策后的结果和相关因素)中挖掘知识和规律,而不是让专家明确表达,这在数据基础好的互联网、物联网等一些领域取了很多成功的应用。在工业等强机理领域,
单纯的机器学习也遇到了变量间耦合强、样本量不足、要素不全、类别不均衡等挑战,仍然要结合机理模型与专家知识。
虽然专家系统在前提假设和理论体系上还有些待突破提升之处。但规则引擎(Rule Engine)仍取得了较为广泛的行业应用,特别在一些逻辑清晰(例如产品定价逻辑本身就是人制定的)且经常变化的领域(例如,零售、酒店、保险等)。行业内也提出了一系列方法论来保证业务规则工程的顺利进行。例如,ABRD(Agile Business Rule Development)
[12]
将规则开发分为Discovery(发现)、Analysis(分析)、Design(设计)、Authoring(审批)、Validation(验证)、Deployment(部署)6个阶段。
在工业中,以规则引擎为核心的知识库也有不少应用
[9]
。其中,一个典型案例就是原西屋电气,1985年成立了Diagnostic Operation Center,先后开发部署ChemAID、GenAID、TurbineAID等智能过程诊断系统(PDS),应用到1200台透平设备,规则数量达到1.6万条。
应用上的挑战
Bell
[7]
和Coats
[8]
对专家系统(或业务规则)在行业中应用的失败原因做了深入剖析。在专家
知识获取阶段
,经常
面临着专家没空(或则说专家有很多更有价值的事情)、专家经验很难明式表达、专家不愿分享、甚至不存在专家经验等挑战;
在
专家经验测试阶段
,也常常面临
测试成本太高、不存在标的结果(Ground Truth)等挑战
。这些挑战在工业场景也一样存在,不过随着数据基础的积累,专家规则在测试阶段的可行性变得更高。
另外,
一旦规则逻辑复杂(数量、耦合性),无论是规则的整理还是维护都变得异常困难
。笔者曾参与过一个配载优化的规则引擎项目,为应对快速增长的货运业务,某国际领先航空公司拟将优秀配载员的经验总结归纳,实现自动配载。2名公司最优秀的配载员花了近1年时间,将他们经验总结为200多页规则流图,这在航空业是非常了不起的工作。但即使行业优秀专家精心总结出的规则,仍不可避免存在着大量不完备、模糊甚至冲突的逻辑,基于行业知识理解、咨询工作和分析技术,虽然最终很好的解决了规则的精化和自动化的问题,但这么复杂的业务规则,对于后期修改升级维护是很大的挑战,远非专家Peer Review机制可以解决的。为此,当时还专门研发了一些基于历史数据和仿真数据进行规则合法性、逻辑完备性的自动化检验工具,从技术手段上保证规则维护的可行性。
针对西屋电气的PDS系统,Thompson等人
[10]
回顾了其30年的艰辛历程:因为认知不周和底层技术更新,PDS系统先后经过了3次大的改版(甚至重新开发);诊断规则的前提是数据可靠,而
传感器的可靠性通常低于工业设备,这造成了规则库中60%的规则用来做传感器故障
;针对
1.6万条规则的维护,西屋电气只好采用专业分工的方式
(而非按设备类型分工),每个组只负责一个专业领域的规则维护。
相对于设备制造商,业主对设备机理的了解程度很难特别深入,知识的获取变得更加挑战。
一线操作人员有不少经验,但通常很难形式化表达或获取,即使表达,也很难完备
。正如郭朝晖老师
[11]
说的“把人脑中的知识放在计算机里其实也不那么简单,因为这些知识是碎片化的、不容易管理”。例如,在一次分析课题中,专家的经验是“如果泄漏量存在持续的上升,则存在密封磨损风险”,但在追问到“持续多久”时,专家只能建议“尝试持续1天看看”,但实际数据分析中发现,只有把“时长”放在1个月的颗粒度上,才能得到稳定的研判,否则会有很多误判。本案例仅仅涉及单个变量,而部分研判通常涉及到多因素、多系统耦合,这样,精准的专家经验就更加困难。

综上所述,在应用专家经验规则时,常常会遇到如表1所示的7大困难。这些困难也对知识型APP开发提出了挑战。
表
1
专家规则应用时的
7
大挑战
|
描述
|
技术需求
|
|
专家经验的模糊性
|
大概方向
|
快速迭代开发环境
|
|
逻辑条件的复杂性
|
条件算子(趋势、模态)
时间窗口
工况研判
|
算子库(时序模式)
冲突发现与排解
|
|
数据需求的差异性
|
数据时长、类型
不同设备
/
规则
|
统一的上下文业务模型(
Context B
usiness Object,简称
CBO
)
CBO
的灵活性(可扩充、实例化
/
视图)
规则
—
设备的关联
|
|
数据质量的强依赖性
|
数据质量缺失情形下的规则执行
|
完备的处理逻辑(明确)
|
|
计算量大
|
数据量大(高频数据)
|
云
+
端
批量计算
|
|
业务规则的可信度
|
部分症状下的规则
|
自学习能力(迭代更新能力)
|
|
产权的保护
|
规则是宝贵的经验(总结出来难,
“
学
”
起来容易)
|
加密、权限机制
|
数据带来的新机遇
随着数据意识和相关技术的发展,1)很多专家经验有了文档记录:很多专家经验以文档资料、维修工单等形式被隐性记录下来,这些
文档是专家知识的一个重要来源
;2)对
工业过程
有了相对完善的数据刻画:工业过程和干预手段也部分被DCS等系统记录,这些信息可以
用来验证和提升专家经验,消除专家经验的模糊性
;3)大数据和工业互联网让大规模的横向/纵向对比变得可能:
工业中存在大量共性基础单元(例如,轴承、齿轮箱等),过去仅仅只能基于有限的局部数据进行挖掘或验证,很难得到普适性的规则,现在互联互通让知识沉淀可以在更大规模上进行检验。
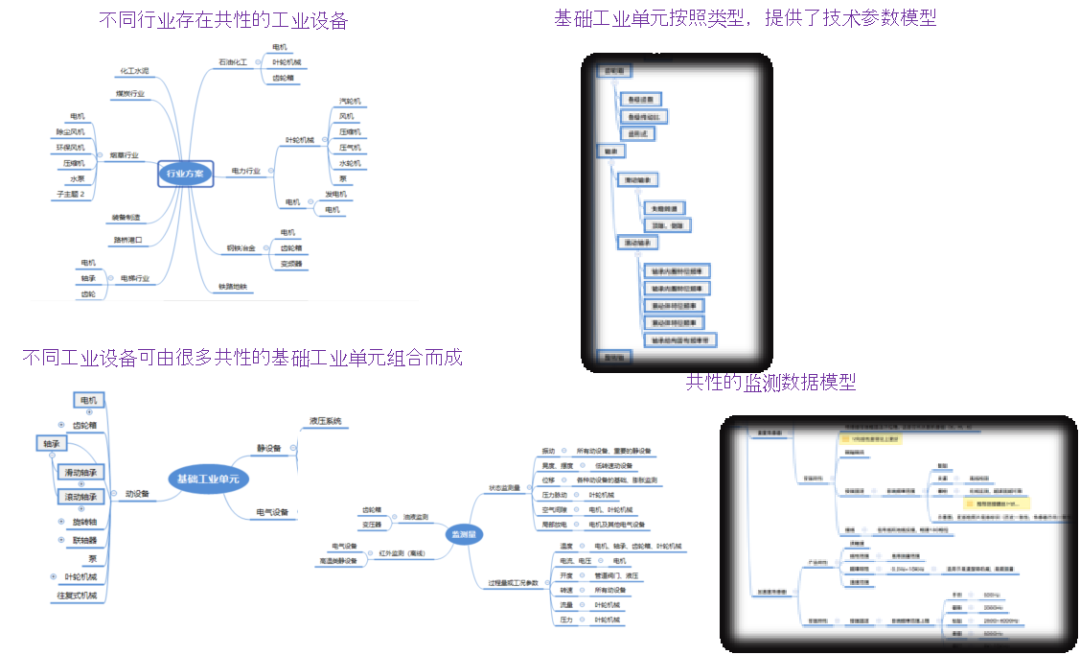
这些变化为工业知识沉淀提供了新的机会。通过自然语言分析和行业知识图谱挖掘,可以把
文档中隐含的知识部分显性化
,通过与工业过程数据的融合分析,可以进一步量化。大量
历史数据可以用来验证、提炼专家知识,实现快速迭代开发
。对于
已沉淀的专家知识,通过定期评估和统计学习,可以实现知识的更新与演进
。这样,通过数据+专家经验,加速知识型APP的成熟过程。
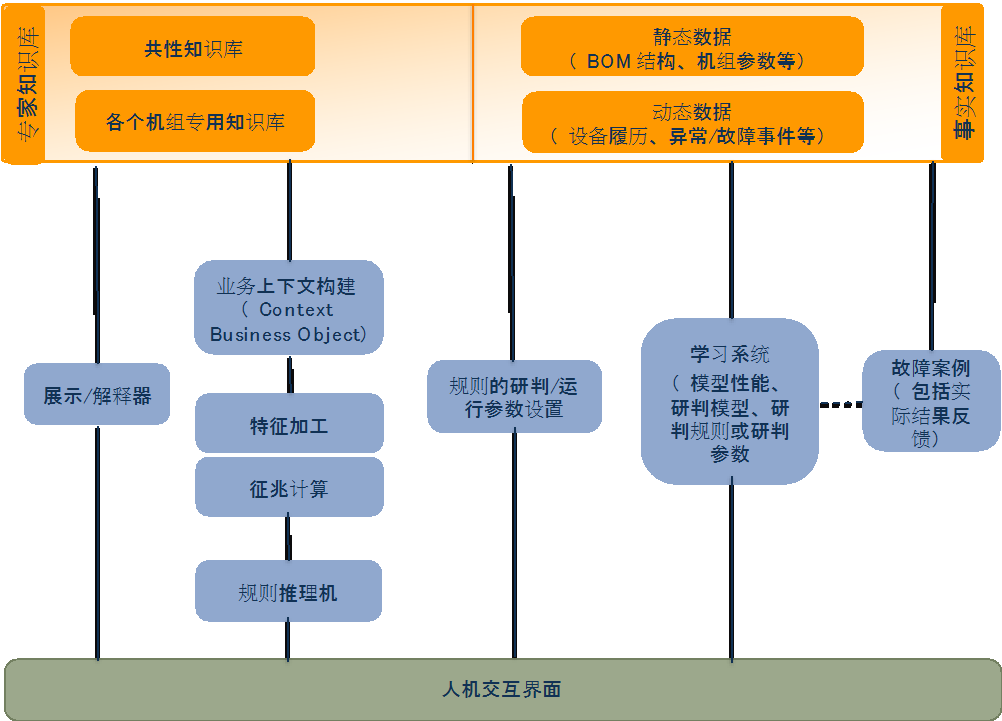
设备运维域的知识沉淀
本节以设备运维域为例,具象阐述前面几节的内容。
针对典型设备的故障诊断和运维,企业和社区通常存在着大量运维工单、经验总结报告、社区讨论等。基于工业知识图谱分析和行业专家的梳理,形成针对特定领域的案例库,并形成半结构化的维度标签,方便检索和语义推理,支撑类似案例推荐、新失效模式识别等业务场景。
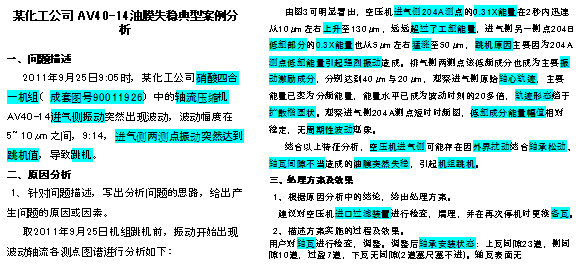
基于异常、故障等案例库(事实知识库),把事件发生前后的工况、状态数据、征兆信息、故障的处置记录、故障修复后的状态识别出来,有可能整理出当前案例下专家的研判逻辑。多个案例的交叉对比,有可能形成专家规则的初步版本,这样大大降低对领域专家的依赖。
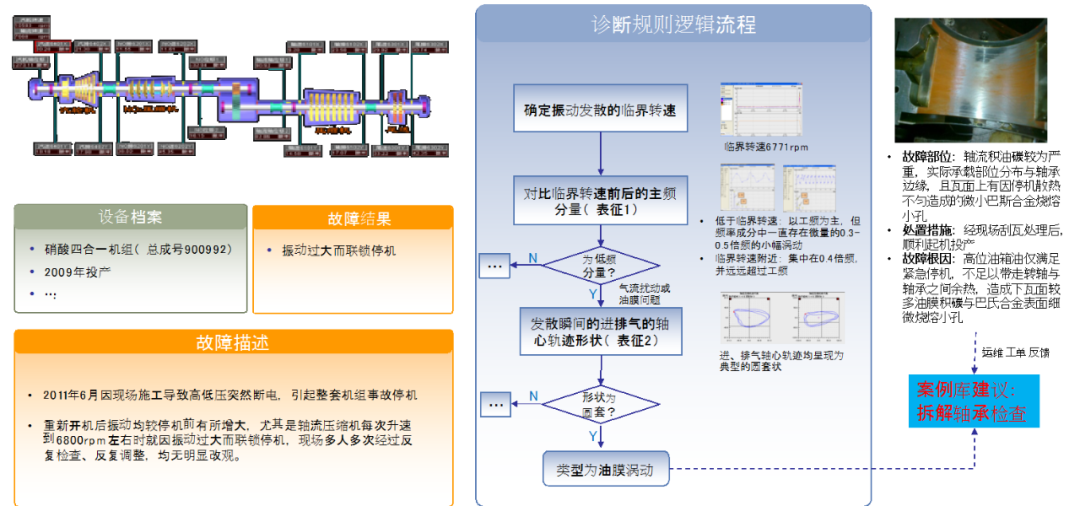
另外,在一些领域,专家经验可以相对容易给出来。例如,下表是透平风机的3个故障研判规则的示例。一种失效模式通常基于多项征兆进行综合研判,一个征兆也常常被多条规则引用。大数据可以用来检验专家规则(找反例),辅助专家细化规则。通过专家规则的“粗筛”,让统计学习算法在“局部”精化,也可以提高研判的精度。
表
2
透平风机的故障研判规则示例

即使数据基础的发展为知识沉淀提供提供了一定的机遇。工业知识沉淀仍然摆脱了不了知识获取、形式化、验证等阶段(类似ABRD)。但工业是一个强机理的领域,其涉及的组织角色和内容更加复杂。
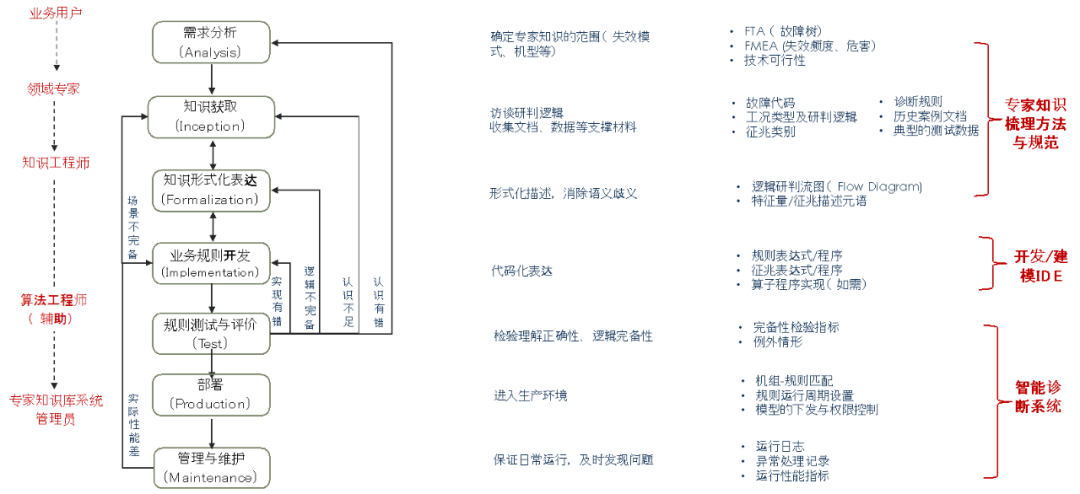
基于过去项目实践,提出了下图所示的5类角色、7个阶段的快速迭代开发模式,如下图所示。根据7个阶段的首字母(Analysis, Inception, Formalization, Implementation, Test, Production, Maintenance),将其简称为AI-FIT-PM方法。相对ABRD业务规则的6阶段模型,我们增加了一个管理与维护阶段,将经验规则部署后的快速迭代明确化。在前面几个阶段,主要考虑在工业规则“bottom up”归纳形式下工作内容的细化;在需求分析阶段,引入工业参考框架保证问题分解的全面性;在知识获取和形式化表达阶段,归纳业务元语。
其中第2阶段(知识获取)非常重要。根据系统结构与工作原理梳理出定性的领域知识。这一步骤很多时候由领域专家提前完成,也可以由知识工程师的业务访谈、文献调研完成,如下图所示。
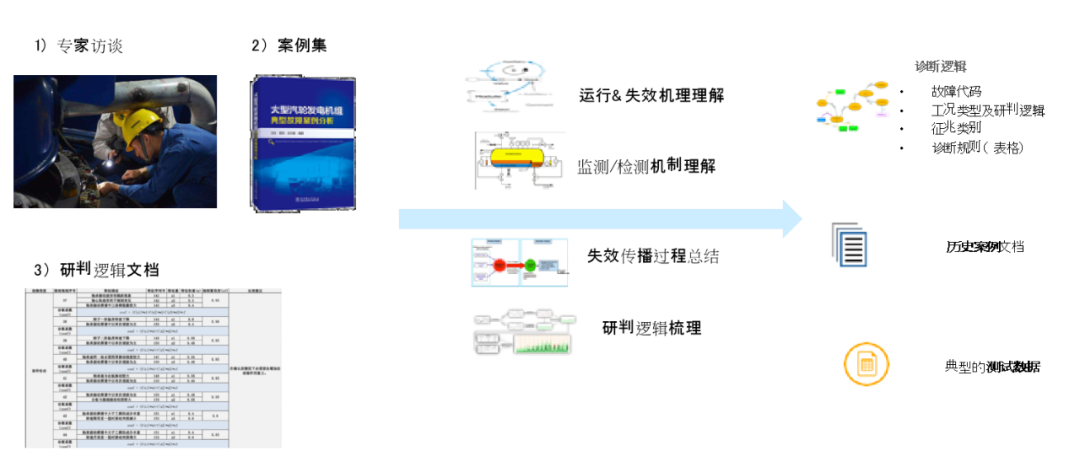
知识获取的重要基础就是理解运行机理、理解监测机制、总结失效过程、梳理研判逻辑等。
(1)系统的运行机制或失效过程
:在本阶段,知识工程师应该对运行机制或失效过程有形式化的理解,并对关键过程量间的关系构建起定性的系统动力学(System Dynamics)模型,如下图所示。注意:为避免陷入细节,这里不需要常微分方程、偏微分方程等数学公式表达的动力学方程,而是需要一个经过抽象的(忽略次要因素)能够清晰反映变量间影响关系的模型(Conceptual Model)。
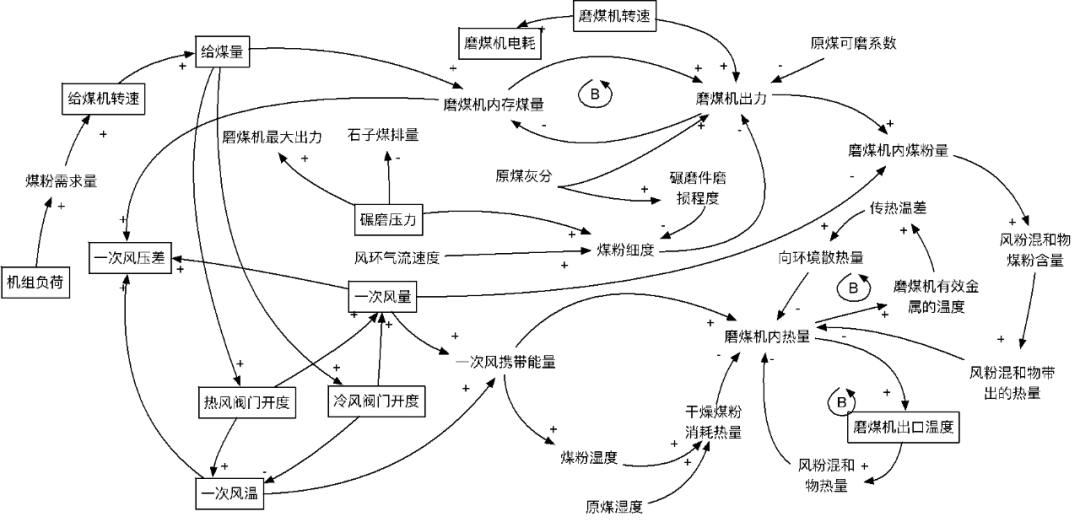
基于系统动力学图,标记出哪些因素是可观测的(上图中标记方框的),同时理解不同要素观测结果的可信度和精度。另外,也要从设备的上下游连接关系去理解可能的外部干扰,例如,通常多台磨煤机公用一个管道,一台磨煤机的一次风量受所有磨煤机冷/热封门开度的共同影响(也受管道结构的影响),单台磨煤机不同时期,冷/热风门开度与一次风量和风温的关系存在不确定性。只有这样,才能
对专家经验的适用范畴和侧重点有个整体把握,而不是一味迷信“专家经验”。
(2)监测/检测机制:
知识工程师要了解监测点位、测量原理等信息。
很多数据异常是由传感器引起的
。例如,电流测量可以认为非常可靠,只需要关注少量的噪声和数据缺失。但一次风量和风温测量可能存在偏差,一次风量采用热扩散技术或压差测量技术进行测量,测量精度与测量装置安装位置、风道结构(例如风道直管太短可能造成风道温度场、风速流场的动态变化)有很大关系
[13]
。
(3)研判逻辑:
在动力学根因的基础上,参考行业标准,确定研判逻辑的完备性。
“专家经验”的逻辑完备性检验有机理推演、逻辑自洽性检验、反例辨析等多种方法。
这里不做详细展开,仅以磨煤机的“机理推演”示意,1)磨煤机物理本体(如设备健康状态、内部工况)是长期缓慢变化的,且不可完全观测,如果“专家规则”是基于长期平均信息,如何考虑这些缓慢变化?2)磨煤机的动态工况过程是本身动态和上游管道(和其他磨煤机)动态的耦合作用的结果,如果“专家规则”没有排除暂态过程,如何分辨暂态的来源?3)对于测不准的问题,专家经验是如何处理的?除了“机理推演”,基于大量历史数据,可以找出当前“专家经验”解释不了的反例,这些反例可以帮助领域专家不断细化自己的经验。毕竟,
专家经验的质量决定了最终的应用效果。
工业知识沉淀与知识应用通常是割裂的。知识的沉淀需要大数据支撑,知识应用偏实时,需要轻量级。传感器部署量、采集频度带来的数据量增长速度远远超过网络带宽的增长速度,大量的数据很难及时传送到中心端,另外,关键设备和实施活动的数据安全合规性(如电力的数据安全分区)也不鼓励将大量的现场数据放入没有严格安全保护的互联网通道,再加上近年来边缘计算能力大大增强,“云+端”的协同计算模式成为一种可行的技术路线。
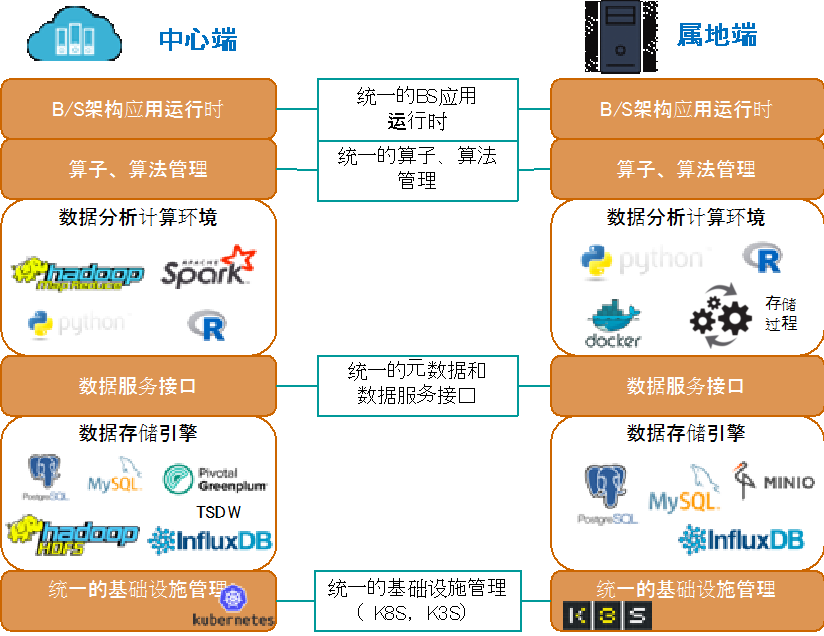
中心侧负责模型的训练和检验,属地侧负责模型的实时运行。为提高专家规则的开发效率,应该提供常见工业元语算子、拖拽式建模,并针对常见的共性工业设备与单元,定义数据标准和参考研判模型。
属地侧负责与中心侧定期进行模型的同步和更新,当然也包括离线数据(过滤或降频后)的定期上传。通过模型的按需流动,消除了大量实时数据流动的需求。属地侧需要考虑异构数据的适配问题,工业中存在不同数据协议,属地测需要提供本地数据与中心测数据标准的匹配。另外,“低运维”是属地侧系统设计的重要考虑因素。

最后需要特别指出的是,
在工业互联网平台建设的同时,一定要注意边缘侧(属地侧)产品的布局与推进
。Gartner
[14]
在2018年调研中指出APP的落地还需要依赖于边缘测。近几年,在Predix的黯然退场后,
国外自动化厂商巨头低调撤回到“外化”阶段,不断在边缘计算的深度防御
[15]
,贴近工厂应用现场。毕竟,
知识的大规模沉淀靠平台,而知识的大规模应用靠端侧
,只有把两个途径都打通,才能在国际市场上构建起长期的竞争力。
工业知识沉淀是推动知识型APP发展的关键技术。在大数据和工业互联网的支撑下,
通过合适的方法和技术支撑,工业知识沉淀过程是可以加速的
。在大数据支撑下,
通过海量历史数据对已形式化的专家规则进行测试,去伪存真、披沙拣金,大数据让专家知识的大规模检验变得可能;基于自然语言处理和行业知识图谱技术,可以从历史的文档中自动发掘专家经验,让专家知识的获取不再完全依赖于人
。基于行业实践,我们提出了AI-FIT-PM的知识沉淀方法,并讨论了云+端的协同计算模式。期望通过数据+专家经验的融合,与业界共同探讨并逐步实现业务知识或业务规则的有效性、活性和规范性。
|
业务期望
|
技术要求
|
描述
|
技术要求
|
|
有效性
|
知识要素的建模(关联性)
|
征兆、原因、异常、故障、措施等要素的结构化关联
规则的置信度设置
|
知识库要素的数据结构
:保证专家知识库的基本要素的有效关联
|
|
活性
|
知识规则的
持续
开发(可扩展性)
|
知识规则与算子的灵活关联
诊断算法/规则的开发效率
|
变量
/
算子库的层次逻辑结构
:通过开发可扩展架构,提高专家规则形式化开发效率
|
|
规范性
|
知识库的
全生命周期
管理(可维护性)
|
规则的生命周期管理:包括规则与设备的关联、运行周期等
查询与统计:静态查询、执行统计
|
规则库管理
:支撑知识库管理员的日常工作,建立长效运行机制
|
关于工业APP的运营、生态构建、知识产权保护等方面,业界有了充分的讨论
[3][6]
。这对知识型APP发展更为重要,知识的质量和多寡直接决定了应用效果。一方面,知识的“
沉淀成本”与知识“抄袭成本”严重不对称
,若缺乏合适知识产权保护机制,知识型APP就无法得到成长;另外,基于工业互联网和大数据,应该
建立专家经验的“评价机制”,保证专家知识的质量,避免“鱼目混珠”,让真正好的工匠经验能够传承下来
。这里特别恳请政府和业界,一起努力构建知识经验沉淀孵化机制,通过不同的激励手段和保护措施,激发科研院所、领域专家和数据公司合作沉淀工业共性知识的积极性,推进整个工业互联网的深度和长远发展。
[1] 王建民. 关于工业软件创新发展的几点认识.
https://www.sohu.com/a/315402140_680938
[2] 赵敏. 如何定义和分类中国的工业软件. http://www.clii.com.cn/lhrh/hyxx/201908/t20190821_3936017.html
[3]
安筱鹏. 工业互联网平台演进带来的技术变革与挑战. https://www.sohu.com/a/225606755_463969
[4]
马国钧. 工业中的知识和智慧, https://www.sohu.com/a/162248694_658106
[5] 朱焕亮, 徐保文. 工业软件浅析. 航空制造技术, 2014, 000(018):22-27.
[6]
杨春晖, 谢克
强. 工业APP溯源:知识软件化返璞归真. 中国工业和信息化, 2018年10期.
[7] Bell, Michael Z. "Why Expert Systems Fail." The Journal of the Operational Research Society 36, no. 7 (1985): 613-19.
[8] Coats, Pamela K. "Why Expert Systems Fail." Financial Management 17, no. 3 (1988): 77-86.
[9] J.R. McDonald, G.M. Burt, J.S. Zielinski and S.D.J. McArthur. Intelligent knowledge based systems in electrical power engineering[M]. Springer,1997.
[10] E.D. Thompson,E. Frolich,J.C. Bellows,B.E. Bassford,E.J. Skiko,M.S. Fox. Process Diagnosis System (PDS)—A 30 Year History, Proceedings of the 27th Conference on Innovative Applications of Artificial Intelligence[C]. Austin: AAAI Press, 2015: 3928-3933.
[11]
郭朝晖. 工业知识软件化:从自动化到智能化. https://baijiahao.baidu.com/s?id=1646094750978777948&wfr=spider&for=pc
[12] Jerome Boyer, Hafedh Mili. Agile Business Rule Development: Process, Architecture, and JRules Examples[M]. Springer, 2011.
[13] 苑召雄. 基于系统动力学的电站磨煤机建模与控制[D].华北电力大学,2017.
[14] Gartner. Cool Vendors in IoT Platforms (ID: G00355487). May 2018.
[15] 林雪萍. 面目全非自动化: 论自动化战略https://mp.weixin.qq.com/s/YTDs-TmxbWTubJRBPG9EWw
@工业互联网研习社 视频号长期深度聚焦#工业互联网#、#智能制造#、#工业数字化转型#等To B垂直领域,提供独家风向观察、知识点系列、To B系列、认知升级、行业要闻等,陪你一起,跨越知识鸿沟,构建工业互联网知识体系,读懂工业互联网发展大势,抓住数字化发展浪潮。
更多视频请关注视频号,已上传4
0+独家视频