☞ 新丝路金融诚邀有识之士加入,岗位详情,请戳☞
招聘信息

科大讯飞一飞冲天,令当前市场中的大多数人摸不着头脑。
尤其身后还有一众头顶AI光环的小弟跟风猛涨,让人惊呼A股已经提前进入人工智能时代。
没有无欲无故的爱,只有后知后觉的恨。
我们无从知道现在上车是否还来得及,但能够知道的是,这一高速专列名为“寒武纪”。
就在上周五(8月18日),国内人工智能芯片初创企业北京中科寒武纪科技有限公司,宣布完成1亿美元A轮融资。
据媒体报道,这一被称为全球AI芯片界首个独角兽的初创公司,其战略投资方包括阿里巴巴、联想、科大讯飞等。 尤其科大讯飞,系其原始股东。
自滴滴之后,中国科技产业界已经在独角兽断档期盘亘数年有余,寒武纪的横空出世,似乎有望再度点燃希望之火。
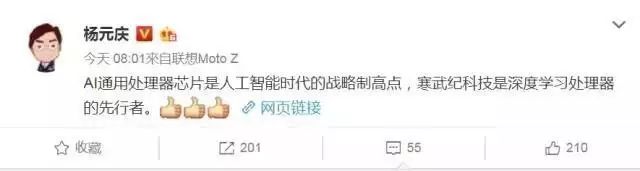
从寒武纪的公司全称不难看出,这是一家中科院系的企业;根据其工商信息显示,北京中科算源资产管理有限公司确系其主要的原始股东之一。
而查询其过往新闻亦可见,昨日(8月21日)涨停的中科曙光,早在2016年4月,曾与寒武纪达成过战略合作关系。
如是说来,近期从科大讯飞一枝独秀,到后续中科信息接连涨停,再到昨日中科曙光坚实封板,背后的逻辑中,贯穿着一条名为“寒武纪”的主线。
AI战略之于中国的意义不遑多说,尤其中科院系统背书,这一概念在近期走出独立行情,足见市场中从不缺少聪明的资金。
“寒武纪”究竟意味着什么?不妨让我们分享一份来自安信证券的研报梗概。
寒武纪:人工智能中国芯
人工智能将推动新一轮计算革命,而芯片行业作为产业最上游,是人工智能时代的开路先锋,也是人工智能产业发展初期率先启动、弹性最大的行业。
信息时代产生了英特尔这样的千亿市值芯片巨头,拥有更大应用市场的人工智能时代必将孕育出更多的“英特尔”。
最近一年多的时间内,先后发生了这样几件大事:
1、英伟达股价再度上涨超过4倍,继续领涨美国科技股;
2、2016年7月20日,软银宣布将以243亿英镑(约合320亿美元)收购英国芯片设计公司ARM;
3、2016年9月,英特尔收购视觉芯片公司movidius;
4、2017年3月,英特尔宣布以153亿美元收购Mobileye;
5、2017年8月,国内人工智能芯片明星公司寒武纪宣布A轮融资高达1亿美元,成为全球AI芯片领域首个独角兽。
芯片是下游IT产业的前瞻指标,近一年AI芯片的繁荣实际上正在向我们预示着人工智能产业未来空前广阔的市场。
但由于AI芯片是一个非常前沿专业的领域,不少人仍然对这一领域有疑惑和误解,再加上近一年行业发生的巨大变化,我们试图在一年后再对这一领域的关键问题进行分析阐述。
一、为什么一定需要人工智能芯片?
投资者关注的核心,就是一定要明白现在大家讲的人工智能,跟我们以往的传统计算机软件有什么差别,判断标准是它们解决的问题:
传统计算机软件解决的是确定问题,即可以通过固定的流程或者规律来描述(比如从1加到100),通过编程交由计算机执行,那么我们设计计算机基础芯片CPU的核心目的是帮助我们一条一条有序的执行我们编译好的指令。
所以IBM把传统的计算机时代又称为编程时代,新的计算机时代称为认知时代。
现在真正意义上的人工智能解决的是欠定问题,即这些问题难以用固定的流程或者规律描述,它的准确答案取决于我们对于这些问题的反应。
典型的例子就是一个3-4岁的小朋友就可以很轻松从世间万物中认出狗或者猫,但传统计算机方法通过总结所有猫的固定特点来编程识别非常困难。
而这一瓶颈恰被此轮以深度学习算法为代表的人工智能技术突破了。所谓深度学习,简单说就是用数学方法模拟人脑神经网络,用大量数据训练机器来模拟人脑学习过程,其本质是把传统算法问题转化为数据和计算问题。
所以对底层基础芯片的要求也发生了根本性改变:人工智能芯片的设计目的不是为了执行指令,而是为了大量数据训练和应用的计算。
图1:传统计算与神经网络的差别
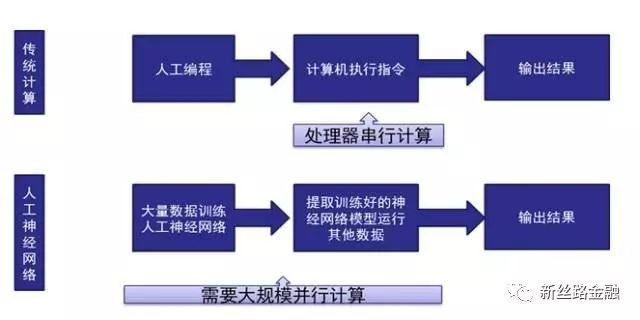
客观的讲,CPU拥有更好的通用性,几乎任何计算任务都可以分解为一条条指令让CPU完成。我们需要人工智能芯片并非CPU不能用,而是效率太差。
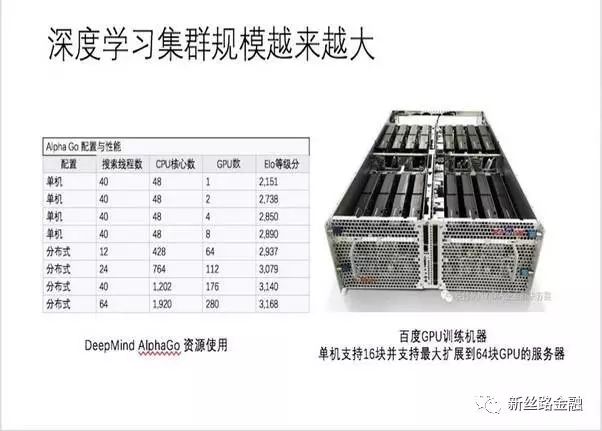
深度学习对计算资源需求几乎是空前的,这一点我们从初代AlphaGo所需要的计算资源就可以看到,所以迫切需要一款适合的芯片能够高效计算深度学习任务,而GPU因为其极佳的并行计算特性恰逢其实。
图2:初代AlphaGo需要1920个CPU核心和280块GPU
二、人工智能芯片市场一定会被英伟达垄断吗?
GPU的天然并行计算优势使得英伟达在人工智能时代如日中天,但我们可以非常肯定的预判:人工智能芯片市场不会被英伟达垄断。
理由是人工智能芯片跟我们传统意义上的芯片有很大的不相同,它其实包括两个计算过程:
1、训练(Train);
2、应用(Inference)。
实际上谷歌首先开始提出设计TPU芯片的目的时就指出了英伟达的GPU在训练阶段具有优势,但在执行阶段效率并不高。
图3:深度学习任务训练和预测环节对计算资源需求有很大差别
此外人工智能芯片和传统计算芯片一样,同时还包括两大类市场:
1、数据中心为代表的后端市场;
2、广义终端市场。
传统计算机时代在数据中心服务器市场几乎垄断的英特尔,在智能终端市场一样不敌ARM。
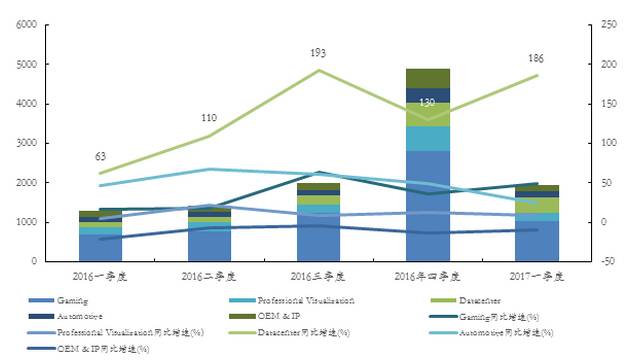
而如果我们关注英伟达近年来的财务报表,其真正意义上人工智能高增长的业务其实就只是数据中心业务。
图4:英伟达2016-2017年各季度不同细分市场营收(百万美元)及同比增速一览
以上特点实际构建了四种不同的芯片应用场景:
图5:人工智能芯片四种应用场景
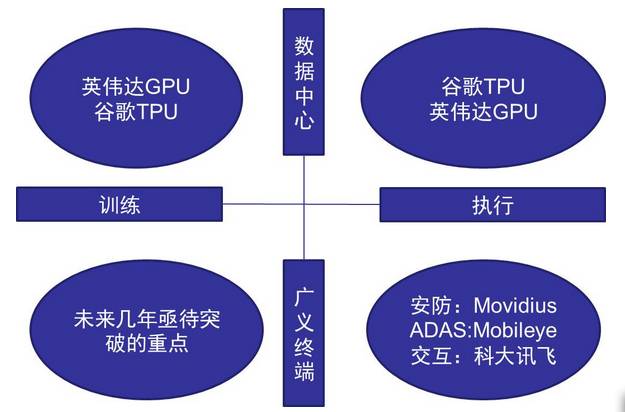
实际上英伟达同时满足四种应用需求并都具备垄断性优势的可能性不大,目前主要优势也只是在数据中心方面,但也面临谷歌TPU的强劲竞争,而这种竞争的核心将是生态的竞争:
1、谷歌的人工智能系统TensorFlow生态趋于成熟。
基本上任何线性代数矩阵计算任务都可以通过TensorFlow提供的工具来帮助用户组装,自动分配到各种计算设备(包括TPU设备)完成并行地执行运算。
而底层计算需求的规整使得采用ASIC(专用定制设计)将极大提升芯片计算效率,全新的Cloud TPU计算能力惊人,而且同时针对机器学习的训练和应用两方面设计。四个处理芯片每秒可完成180 tflops计算任务。
将 64 个 Cloud TPU 相互连接可组成谷歌称之为Pod的超级计算机,Pod将拥有11.5 petaflops的计算能力(1 petaflops为每秒进行1015次浮点运算)。
图6:数据流图中这些数据“线”可以代表传输多维数据数组,即“张量”(tensor),张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。
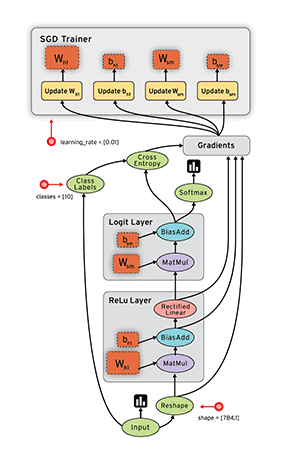
2、 Cloud TPU 将加入谷歌云计算平台,并整合进谷歌计算引擎(Google Compute Engine),即普通用户在云端就可以调用这些世界上最领先的计算芯片来训练自己的人工智能任务。
谷歌将为开发者们提供最好、最广泛的硬件选择,从CPU、到 GPU(包括 Nvidia 上周最新发布的 GPU 产品)、再到 TPU。
图7:cloud TPU由四块芯片组成

对于终端市场来说,对芯片的功耗、面积、价格都有极为苛刻的要求,目前终端人工智能芯片主要是执行神经网络算法的功能,安防和自动驾驶是最大的两个市场。
对于终端训练功能芯片目前尚不成熟,但可能是未来几年发展的重点,可以想象通过芯片不断进步使得谷歌大脑规模的神经网络嵌入在随身携带的手机里,将会带来怎样的产业变革。
虽然英伟达也针对终端市场推出了Jetson TX系列芯片,但价格、功耗等综合考量并不占据绝对优势。
而以Movidius为代表的新兴企业成则为了业界新秀。
这也不难解释英特尔为何先后收购了movidius和Mobileye两家公司,他们分别对应机器视觉和自动驾驶两个最大的终端市场。
终端领域人工智能芯片有两种类型:
第一,采用较为通用的处理器,如movidius、英伟达的Jetson系列芯片,通用性较好,能够运行各类神经网络算法,但价格相对较高,主要针对高端市场。
就像当年 iPhone 5s 加入了M7协处理器,针对计算机视觉领域在一些终端设备上提供一块专门的低功耗处理芯片,在处理深度学习的问题时更加高效,可以针对卷积神经网络的训练特征从芯片级别进行优化,从而促进基于深度学习的计算机算法在终端设备上的普及。
这类芯片的代表就是刚刚被intel收购的Movidius公司。
它们推出
Myriad 系列VPU(视觉处理器)平台
可以用于3D感知及扫描建模的芯片,可以支持室内导航、360度全景视频处理等机器视觉应用,其视觉处理性能超出其它处理器平台十倍,功耗则低一个数量级,而尺寸和价格都仅为五分之一。
Myriad 的第二代VPU采用全新的体系架构,提升性能达到二十倍,增强视觉处理能力使之成为新的VPU标杆。
图8:movidius架构,其中的关键在于加速深度学习算法的线性代数运算矩阵
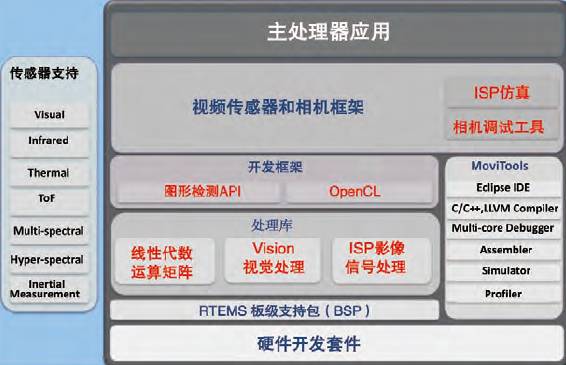
图9:movidius芯片的应用场景

数据来源:movidius
第二,将已经训练好的较为通用的智能识别类算法直接固化为IP,嵌入到SOC芯片中,优点是因为是专用芯片(ASIC),量产后功耗、价格等都极具优势,但功能拓展性有限。
例如在安防领域,
商汤科技
的SenseEmbed将深度学习人脸识别算法通过高性能计算极致优化,搭建底层算法最优解决方案。
利用商汤科技自主研发的PPL、FastCV高性能异构并行计算组件库,能将复杂的深度学习算法集成在一张小小的芯片中,进行毫秒级识别速度。
目前已支持
海思Hi3519/Hi3516A/Hi3516D、飞思卡尔IMX6、ARMCortexA7
等多款主流嵌入式芯片,将为硬件设备提供最优深度学习算法引擎。
三、人工智能芯片的形式是GPU、FPGA还是ASIC?









