

图源:unsplash
原文来源
:arXiv
作者:
Chao-Yuan Wu、Nayan Singhal、Philipp Krähenbühl
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
我们的数字通信、媒介消费和内容创作越来越多地围绕着视频展开。我们通过这些视频分享、观察和存档我们生活的许多方面,而所有这些都是由强大的视频压缩驱动的。传统的视频压缩是通过费力的手工设计和手工优化进行的。本文提出了一种端到端深度学习编解码器的可选方案。我们的编解码器建立在一个简单的想法上:视频压缩是重复的图像插值。因此,它得益于在深度图像插值和生成方面的最新研究进展。我们的深度视频编解码器性能优于当今流行的编解码器,比如H.261、MPEG-4 Part 2,并且与H.264的性能相媲美。

图1:在电影《钢铁之泪》中,我们的端到端深度视频压缩算法与MPEG-4 Part 2和H.264的比较。所有方法使用0.080 BPP。我们的模型比MPEG-4 Part 2提供更好的视觉质量,可与H.264相媲美。与传统方法不同,我们的方法没有块伪影。与原始未压缩的对照标准相比,MS-SSIM对视频剪辑的图像质量进行测量
视频占据着互联网数据的最大份额,现在它占据了所有互联网流量的3/4。我们捕捉瞬间,分享记忆,并通过动态图片互相娱乐,所有这些都是由强大的数码相机和视频压缩驱动的。强大的压缩可以显著减少互联网流量,节省存储空间,并增加吞吐量。它驱动了诸如云游戏、实时高质量视频流、3D和360度视频等应用。视频压缩甚至有助于更好地理解和解析使用了深度神经网络的视频。虽然有这些显而易见的好处,但是视频压缩算法仍然主要是手工设计的。当今最具竞争力的视频编解码器依赖于块运动估计(block motion estimation)、残差颜色模式(residual color pattern)和它们使用了离散余弦变换(discrete cosine transform)和熵编码(entropy coding)的编码之间的复杂相互作用。虽然每个部分都经过精心设计,以尽可能地压缩视频,但整个系统并未进行联合优化,而且基本上没有受到端到端深度学习的影响。
本文介绍了,据我们所知的第一个进行了端到端训练的深度视频编解码器。我们的编解码器的主要洞察在于对视频压缩的不同看法:我们将视频压缩作为重复的图像插值,并利用深度图像生成和插值方面的最新研究进展。我们首先使用标准的深度图像压缩,对一系列锚帧(关键帧)进行编码。然后,我们的编解码器通过在相邻锚帧之间进行内插以重新构造所有剩余的帧。然而,这种图像插值并不是唯一的。我们还为插值网络提供了一个小型的可压缩代码以消除不同插值的歧义,并尽可能忠实地对原始的视频帧进行编码。我们主要的技术挑战是可压缩图像插值网络的设计。

图2:我们的模型由压缩关键帧的图像压缩模型和插入残差帧的条件插值模型组成
我们介绍了一系列用于图像插值的越来越强大并可压缩的编码器-解码器架构。我们首先使用一个vanilla U-net插值架构来重构除关键帧之外的帧。这种架构很好地利用了时间上的重复静态模式,但是它难以正确地消除移动模式轨迹的歧义。然后,我们直接将一个离线运动估计从块运动估计或光流中结合到网络中。该新架构内插了使用预先计算的运动估计的空间U-net特征,并在深度图像压缩上将压缩率提高了一个数量级。这个模型捕获了大多数但并不是全部我们重构框架所需的信息。另外,我们还训练了一个编码器,它可以提取不存在于任何源图像中的内容,并将其简洁地表示出来。最后,我们减少了所有剩余的空间冗余,并使用一个带有自适应算术编码的3D PixelCNN对它们进行压缩。
为了进一步降低视频码率(bitrate),我们的视频编解码器(codec)以分层方式应用图像插值。层次结构中每个连续层次都在更接近的参考帧之间进行插值,因此更加具有可压缩性。层次结构中的每个级别都使用所有以前的解压缩图像。
我们将我们的视频压缩算法与最先进的视频压缩(HEVC,H.264,MPEG-4 Part 2,H.261)以及各种图像插值基线进行比较。我们在两个未压缩视频标准数据集上对所有算法进行了评估:视频追踪库(VTL)和超视频组(UVG)。我们另外收集了Kinetics数据集的一个子集用于训练和测试。Kinetics子集包含高分辨率的视频,我们将其进行下采样以去除YouTube上先前编解码器引入的压缩伪影。最终数据集包含280万帧,根据MS-SSIM和PSNR测量所测量的结果显示,我们的深度视频编解码器在压缩率和视觉质量方面均优于所有深度学习基线,MPEG-4第2部分和H.261。我们能够与最先进的H.264编解码器相媲美。图1显示了一个可视化的比较。所有数据都是公开可用的。
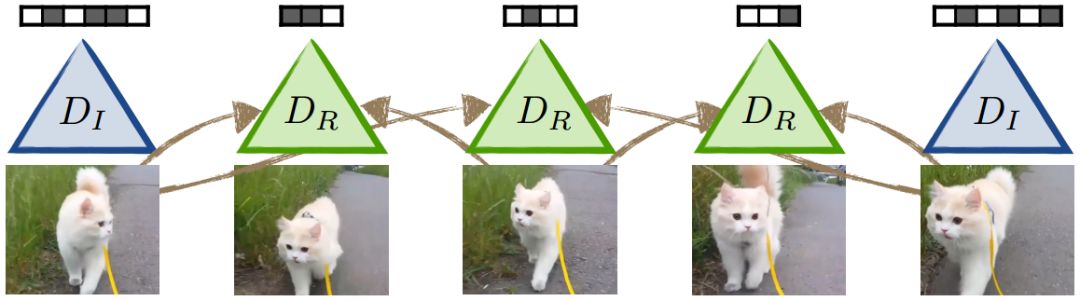
图3:我们以分层方式应用插值。层次结构中的每个级别都使用先前所解压缩的图像
视频压缩算法必须指定一个用于压缩视频的编码器,以及一个用于重建原始视频的解码器。编码器和解码器一起构成编解码器((codec))。编解码器有一个主要目标:用尽可能少的比特数对一系列图像进行编码。大多数压缩算法在压缩率和重构误差之间找到了一个微妙的折衷。最简单的编解码器(如运动JPEG或GIF)独立对每个帧进行编码,并且严重依赖于图像压缩。
图像压缩,对于图像来说,深度网络可以产生最先进的压缩比,且具有令人印象深刻的重构质量。他们中的大多数都是通过一个小的二进制瓶颈层对一个自编码器进行训练,以直接使失真最小化。一种流行的变体使用循环神经网络逐步编码图像。这使得单一模型具有可变压缩率。我们将这个想法扩展到可变速率视频压缩中。
深度图像压缩算法使用完全卷积网络来处理任意图像大小。然而,完全卷积网络的瓶颈仍然包含空间冗余激活。熵编码(Entropy coding)进一步压缩了这个冗余信息。我们遵循Mentzer等人的方法并在对Pixel-CNN的概率估计中使用自适应算术编码。
学习二进制表示本质上是不可微的,这使基于梯度的学习变得复杂。Toderici等人使用随机二值化(stochastic binarization)并反向传播期望的导数。Agustsson等人使用软分配以近似量化。Balle等人通过添加均匀噪声来取代量化。所有这些方法的运行都是相似的,并使得梯度能够通过离散化过程。在本文中,我们使用随机二值化。
结合这些技术,深度图像压缩算法在相同的图像质量水平下,能够提供比手工设计的算法(如JPEG或WebP)更好的压缩率。深度图像压缩算法极大地利用了图像的空间结构。但是,他们错过了视频中的一个关键信号:时间。视频暂时性地高度冗余。没有深度图像压缩能够与最先进的(浅层)视频压缩技术相媲美,这种压缩技术利用了这种冗余技术。
视频压缩
人工编写的视频压缩算法(例如:H.263、H263和HEVC(H.265))往往基于两种简单的思想:它们将每一帧都分解为多个像素块(亦称宏块,macroblocks),并将帧分为图像(I)帧和参考(P或B)帧两种。I帧使用图像压缩直接压缩视频帧。视频编解码器节省的大部分空间都源于引用帧。P帧会借用先前帧的颜色值。它们为每个宏块存储一个运动估计和一个高度可压缩的差分图像。另外,只要没有循环引用,B帧就允许双向引用。H.264和HEVC都以分层方式对视频进行编码。I帧构成了层次结构的顶部。在每个连续的级别中,P帧或B帧都参考较高级别的解码帧。传统视频压缩技术的主要缺点是,需要大量的工程投入,并且在联合优化方面存在难度。在该项研究工作中,我们使用深度神经网络构建一个分层视频编解码器。我们在不借助任何人工设计的启发法或过滤器的情况下,对其进行端到端的训练。我们的主要观点是参考(P或B)帧作为图像插值的一种特殊情况。
基于学习的视频压缩还有很大一部分等待人们的探索,究其原因在于时间冗余建模方面存在困难。Tsai等人提出了一种用于在特定域视频中编码H.264误差的深度后处理过滤器。但是,目前我们还不清楚过滤器是否以及如何在开放域中进行泛化。据我们所知,本文提出了首个用于视频压缩的通用深度网络。
图像的内插值与外推值
图像内插值试图在两个参考帧之间产生一个看不见的帧。大多数图像内插值网络建立在编码器-解码器网络构架上,可以随时间移动像素。Jia等人与Niklaus等人估算了一个空间变化的卷积核,Liu等人制作了流场(flow field)。这三种方法,沿时间正向、反向将两种预测相结合,形成最终的输出。
图像外推值更具“雄心”,它可以预测几帧后的未来视频或静止图像。图像的内插值和外推值都可以很好地作用于小时间步长,例如,用于创建慢动作视频或预测未来的几分之一秒。然而,如今的方法将帮助它们适用于更大的时间步长,在该方法中,内插值和外推值不再是唯一的,并且需要额外的辅助信息。在该项研究工作中,我们扩展了图像内插值,并纳入了少量可压缩边信息,以重建原始视频。
据我们了解,本文介绍了首个端到端训练的深度视频编码器。它依赖于重复的深度图像内插值。为了消除内插值的歧义,我们对一些表示信息的可压缩比特进行编码,而这些信息并不是从相邻的关键帧中计算出来的。这会产生可靠的重构,而非纯粹的幻觉。该网络无需事先掌握工程知识,就可以直接被训练并用于优化重构工作。
我们的深度编码器非常简单,其性能优于MPEG-4 Part 2或H.261等主流编码器,与最先进的H.264编码器性能相当。我们目前没有将运行时间或实时压缩等工程方面的问题考虑在内。我们认为它们是未来的重要研究方向。
简言之,由深度图像内插值驱动的视频压缩,无需复杂的启发法或过度工程设计,就可以实现最先进的性能。
原文链接:
https://arxiv.org/pdf/1804.06919.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「raicworld」关注公众号




