本文介绍了Chrome浏览器内置的AI技术,包括内置AI的概念、架构、与云端AI的关系,以及配套的API功能、使用方法和经验分享。作者还讨论了如何使用和发挥好这些API的作用,包括加入开发者内测群、检查设备是否符合要求、解锁API、使用Origin Trials等。
包括支持更多语言、开放多模态能力、成为语言标准和浏览器必备功能等。
前言
介绍了 Chrome 浏览器内置的 AI 技术,包括内置 AI 的概念、架构、与云端 AI 的关系,以及配套的 API 功能、使用方法和经验分享,呼吁开发者参与构建 Web AI 生态系统。今日前端早读课文章由 @Jax 授权分享。
正文从这开始~~

大家好,我是 Jax。非常开心再一次和大家在 Dev Fest 见面。
我今天分享的是关于 Chrome 浏览器内置 AI 的内容,希望通过我的分享,可以让大家感受到在 AI 大潮流之下,Web 技术是如何进化的。

我是一个前端开发,我对这个身份非常自豪。套用 AI 领域一句名言来说,我的信条就是「Web is all you need」。但这两年 AI 火起来后,大家都觉得我们前端切图仔会最先被取代。我一直是不信的,直到我发现今年开发者节已经没有 Web 主题了。完了,路走窄了,行业要没了。
但冷静下来我觉得这不失为一件好事,正因为 AI 让 Web 开发的门槛越来越低,所以才会有越来越多的人能感受到 Web 开发的乐趣,用的人多了,Web 技术栈就会越来越普及、越来越重要。所以今后可能不再会有专职得前端程序员,但前端开发却会成为更多人的必备技能。
而且 Web 技术也从来没有停止进化的脚步,它面对不断变化的需求场景,总是能不断进化出新的能力。那今天我们要聊的内置 AI,就恰好能体现出 Web 的这种生命力。

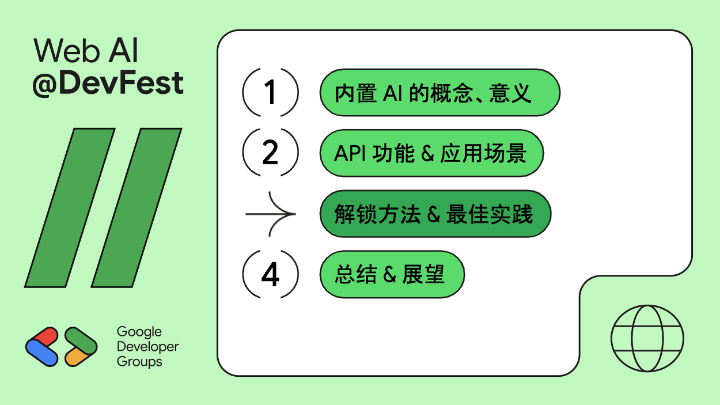
我的内容分为四个部分,首先我们对齐一下概念,讲讲内置 AI 是什么,然后通过 demo 来展示一下它有什么用,如果成功地引起了大家的兴趣,那么第三部分我们来说说怎么使用它,最后是总结和展望。

我们先来搞明白一个问题:当我们聊到 Chrome 内置 AI,我们到底在聊什么?
Chrome 浏览器近期更新了好多 AI 功能,比如我们现在可以用 Google Lens 智能镜头来截图搜索;可以在地址栏输入 @gemini 直接和 Google 的大模型对话;以及和开发者更相关的,在开发者工具里随处可见的 AI 交互功能。但严格来说,这些 AI 功能还是调用了云端 AI 服务来处理任务,并不算真的把 AI 能力内置到了浏览器中。
真正地地道道的内置,是 Google 把 Gemini Nano 集成到 Chrome 中。Gemini 是 Google 的多模态模型家族,而 Nano 是家族中专为端侧部署而生的轻量模型,Nano 有 1.8B 和 3.25B 两个版本,体积非常小巧。
这样的好处是什么呢?咱们来打个比方,大模型就好比厨师。咱们在公司上班,午饭一般是点外卖,我们在外卖软件上下个单,商家接单出餐,骑手接单送餐,然后我们才能吃到嘴里。但如果公司自己有食堂,那就方便多了,到了饭点儿我们直接去食堂就能吃上饭。那么浏览器里内置大模型,就相当于公司自带食堂,内置模型可以直接为浏览器的 AI 功能提供支持。
而更利好咱们开发者的是,Chrome 不光自己用 Nano,还提供了配套的 JavaScript API,让开发者也能调用 Nano 的能力。这就更棒了,相当于如果公司食堂没有你想吃的,你可以自己准备食材,让食堂的厨师帮你做,简直不要太爽。
所以我们今天要聊的话题,就是内置模型,以及配套的 API。Chrome 称之为 Built-in AI。
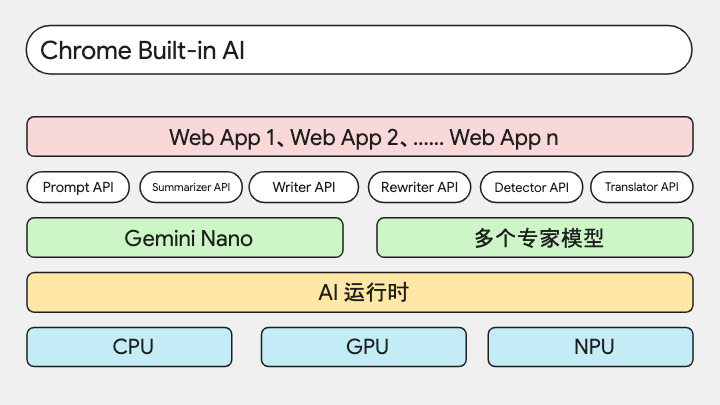
我们先来从下到上看一下 Built-in AI 的架构。
首先最下层是硬件,有 CPU、GPU 以及专用于深度学习的 NPU,各个 PU 来提供算力支持;
硬件的上层是 Chrome 内部的 AI 运行时环境,可以运行 Gemini Nano 和其他专家模型,是的,内置 AI 不只内置了一个模型;
在模型能力的基础上,封装出了许多个 JavaScript API,用于处理不同类型的任务;
基于 API,我们可以构建自己的 Web AI 应用。
像 Chrome 这样把模型集成进浏览器,非常具有开创性意义,它代表着我们在模型部署策略上有了新的探索和进步。
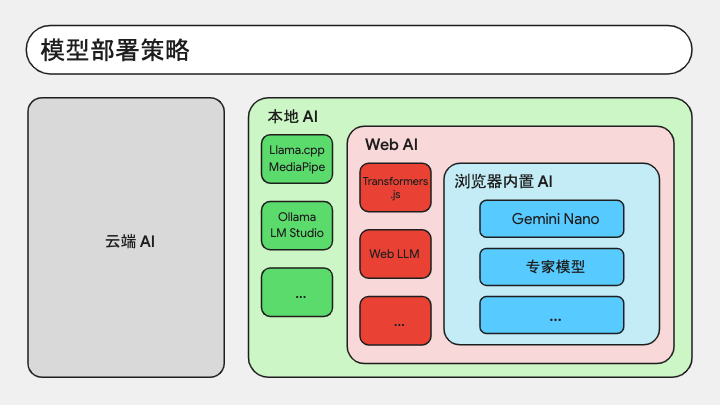
我们现在常用的 GPT、Midjourney 等等,都是厂商把自家模型部署在云端服务上,我们与 AI 的交互,都是从客户端发起 HTTP 请求打到云端,云端处理后返回结果。也就是刚刚说的点外卖模式。
如果我们把模型理解为程序里的一个子模块,那么理论上来说,凡是程序可以运行的地方,都可以存在模型。那么模型既然能跑在云端,理论上也能跑在用户端,于是就有了端侧部署的概念。
现在已经有很多工具可以让模型跑在本地设备上,比如 Llama.cpp、MediaPipe 这些部署框架,也有 Ollama、LM Studio 之类的模型托管工具。
Web AI 则是端侧智能的子集,指的是跑在泛浏览器环境中的智能模型,包括不限于网页、浏览器扩展、Electron 应用等等。比如我们可以在网页中用 Transformer.js、WebLLM 这样的开源库来加载模型,让模型直接成为 Web 应用的一部分。
而浏览器内置 AI 则又是 Web AI 的子集。
于是,从设备本地到 Web 端,再到浏览器端,层层递进,AI 模型正在一步一步地融合到 Web 生态的基础设施中。

听到这里大家可能会有疑问:端侧 AI 能做的事儿,云端 AI 都能实现,而且能能实现得更好,那我为啥还要用端侧 AI 呢?
这里希望大家了解的是:内置 AI 的出现,并不是为了取代云端 AI。它是为了满足那些云端无法满足的需求场景的,这二者的侧重点不同,所以其实是不存在冲突和竞争的。
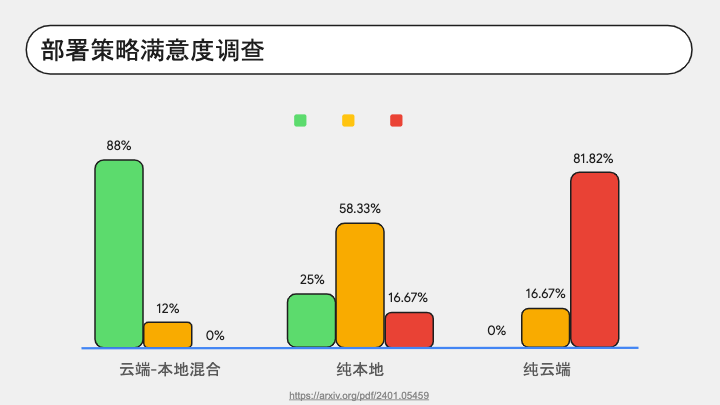
有研究组织调查了 25 位 LLM Agent 的领域专家对不同部署策略的看法。
从柱状图我们看到,有 88% 的人认为双端混合部署是非常棒的选择,有 25% 的人认为纯本地部署也很好,而有 81.82% 的人对现有的纯云端部署不满意。他们介意的点在于云端部署高延迟、高成本,有隐私问题。
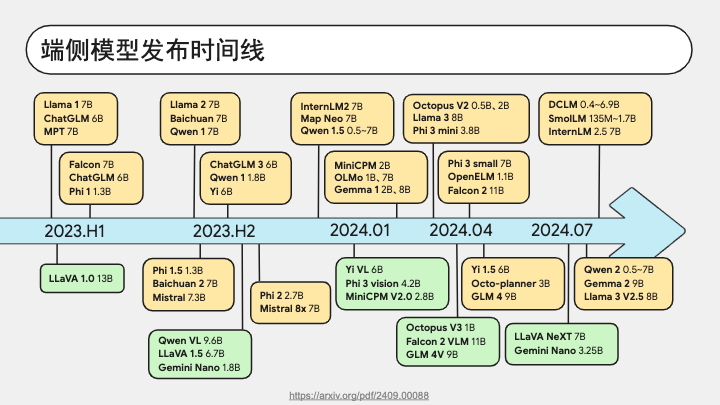
那么各个模型厂商也是捕捉到了这样的痛点,所以早早就开始在端侧模型上发力。我们从这张图看到,从 2023 年初以来,各家厂商不断在发布参量在 10B 以下的模型,用来适应端侧部署的场景。其中黄色底色的是纯文本的大语言模型;而绿色的则是多模态模型。我们能看到两个趋势,一个是端侧模型的发布越来越密集,从最初的平均每个月一到两个,到后来平均每个月就有四到五个新模型发布出来;另一个趋势是大家越来越重视多模态能力。
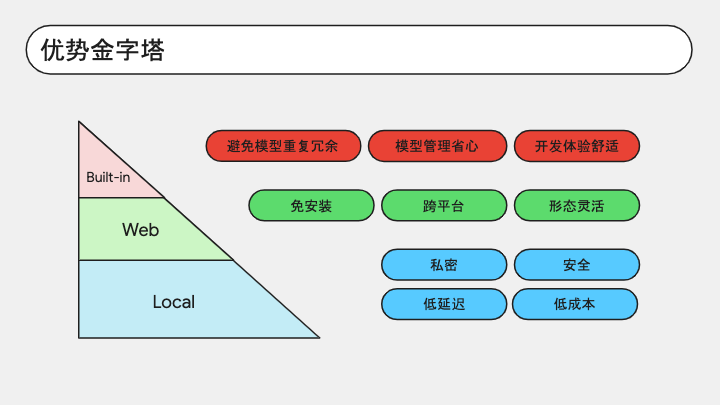
随着端侧模型数量增多,多模态能力增强,我们在开发端侧智能应用时的选择也就越来越多,优势也会越来越大。那如果我们要基于浏览器内置 AI 来开发一个应用,这个应用会天然具有多重优势。
首先它属于本地部署模型,不需要用 http 请求来调用云端接口,所以可以做到低延迟,非常适合对实时性要求高的场景;它能减少网络攻击的可能性,也极大地保证了用户的数据隐私,能同时帮用户和开发者降低成本,包括访问门槛、网络带宽成本、API 调用成本等等,甚至可以离线使用,不用怕弱网、断网。
其次它基于 Web 技术栈,所以无需免安装、用完即走;而且能跨平台,形态灵活,我们很容易就能把应用包装成网页、浏览器扩展、PWA、Electron 等各种形式。
最后,模型内置在浏览器中,开发者不需要操心模型的加载和管理,非常省心。而且当用户打开多个 Web 应用,也不会出现每个应用都各自重复加载一遍模型的情况。有了 JavaScript API,我们只需要写很少很简洁的代码,开发体验很舒适。
OK,我们讨论完内置 AI 是什么,它有什么价值,那接下来,我们来看看配套的 API,它有哪些功能、能用来做什么。
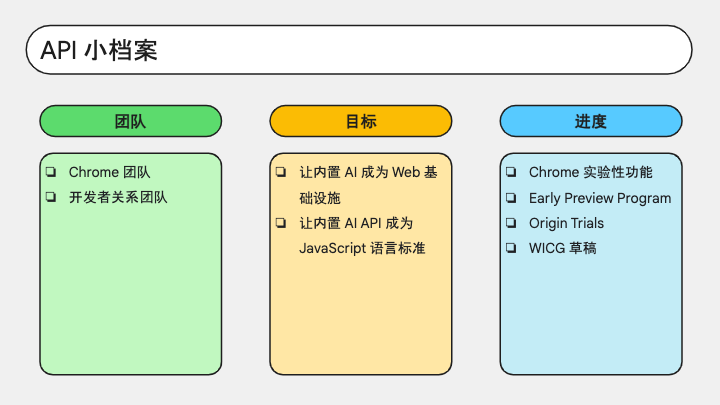
我们先来了解一下 API 的基本信息。
这套 API 由 Chrome 内专门的团队来负责实施,同时有开发者关系团队面向开发者来进行宣讲、答疑、收集反馈。同时,这套 API 也在 WICG 仓库建立了草稿文档。
WICG 全名是 Web 孵化器社区,是 W3C 下的一个社区组织,有许多知名的 API 都是从 WICG 走出来的。
所以这套 API 将来会进入 W3C 提案流程,成为 JavaScript 标准的一部分。它不只是为了让 Chrome 更强大,它希望内置 AI 能够成为 Web 技术的基础设施,让每一种浏览器都能提供 AI 能力支持。
到目前为止,这套 API 还在建设中,它已经作为实验性功能装载到 Chrome 中,最新的正式版都是可以用的。这些 API 会经历两个阶段。
EPP 指的是 Early Preview Program,可以理解为开发者内测群。
OT 指的是 Origin Trials,是 Chrome 灰度测试的一种机制。比如 Chrome 某个功能还没有全量开放,但我们想给用户用,就可以把自己的 Web 应用注册到 OT 中,这样,当用户打开我们的 Web 应用,就静默开启了实验性功能。
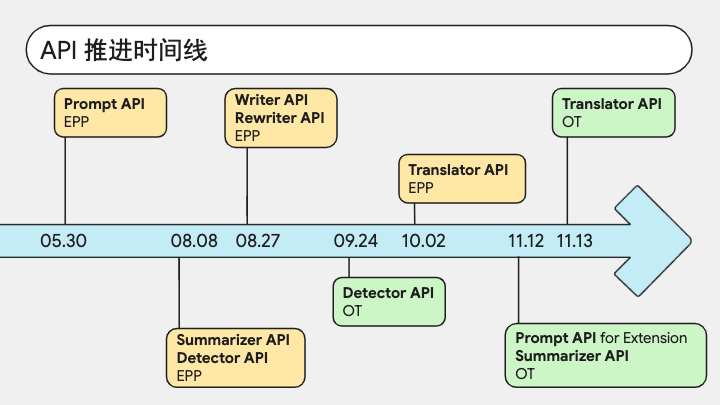
这是这套 API 的推进时间线。黄色代表 EPP,绿色代表 OT。我们看到大部分 API 都已经推进到了 OT 阶段。OT 阶段一般会持续五个版本,然后如果顺利的话应该就会全量了。
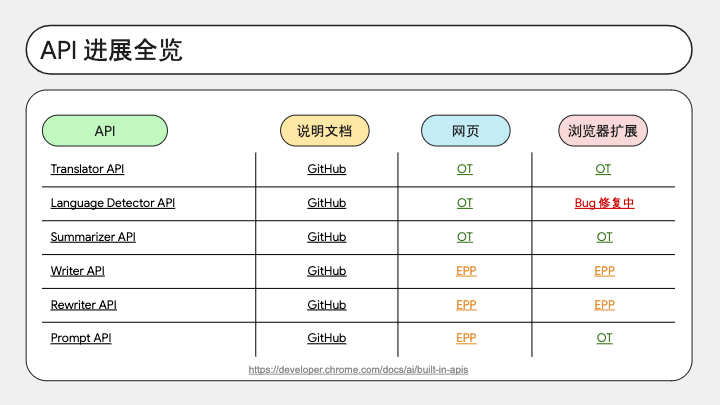
这张表格统计了各个 API 的进展,我们可以看到对应的说明文档、在网页和浏览器扩展中的实施进度。
所以 API 还处于早期阶段,但官方团队正在积极地向开发者收集需求和反馈,不断地调试、迭代,各项功能正在迅速达到稳定状态。
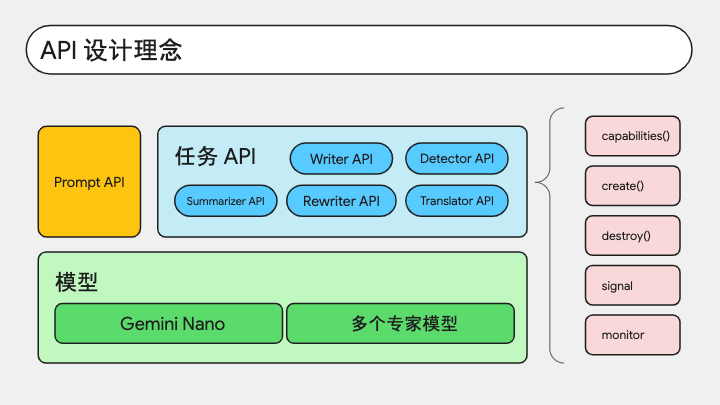
API 的设计也是围绕内置模型来展开。
虽然 Gemini Nano 是多模态模型,可以处理音频、图片,但是目前考虑到端侧设备的硬件性能有限,所以当下 API 主要还是处理文字。那么与大模型交互,当然离不开提示词,所以也就有了 Prompt API ,开放给开发者,更多是希望用灵活的方式去探索更多应用场景,进而基于场景抽象出特定的任务。Summarizer、Writer、Rewriter 就是这样的高级抽象 API。
除了 Nano,还有一些翻译模型,用于提供语种检测和翻译任务,对应的就是 Detector 和 Translator API。
这些 API 在结构定义上保持了基本一致的风格,比如它们都具有 capabilities 方法来验证可用性,都有 create 方法来实例化,都可以通过 destroy 销毁,以及都支持 signal 信号中断以及 monitor 监控模型加载进度等等。
那么接下来,我们就通过一系列 Demo 逐一来了解它们的功能和应用场景。
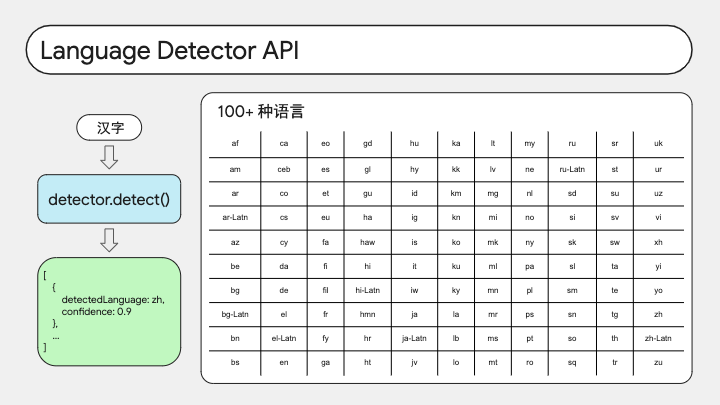
我们先来看看语言检测 API。
这个 API 非常简单直观,我们给它输入一段文本,它会检测出属于什么语种。比如我们给它一段中文,它会返回一个对象数组,按照可能性降序排序,那么第一个对象里的 confidence 是 0.9,detectedLanguage 是 zh,意思是有 90% 的概率是中文。
Detector API 目前支持检测一百多种语言。右侧表格中列出的就是支持的 BCP 语言标签。
我们来看一个 Demo,当我们输入英文或中文词语后,内置 API 能够很快速地检测出来。

接着是翻译 API,用来把一种语言翻译成另一种语言,目前支持英文和其他三十多种语言互译,但是也有办法让非英语语言之间直接翻译,后面我们会说到这个办法。
Translator 接收两个参数,一个是原文本的语种标签,另一个是目标语言标签。
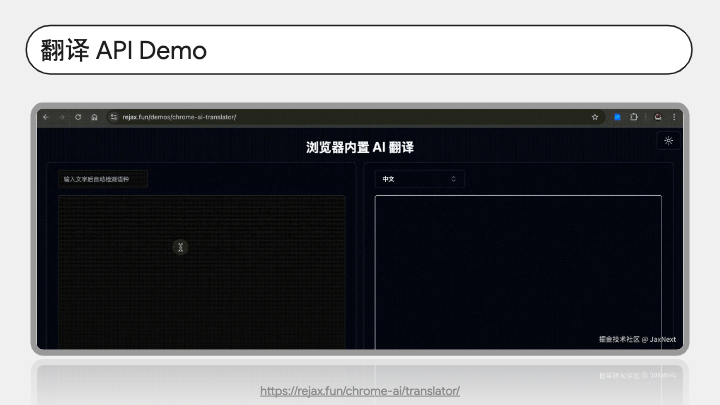
我们来看一个 Demo,这是一个用翻译 API 写的翻译工具。我们在左侧输入任意文本,会自动识别出是什么语种,用的就是刚刚讲的 detector。输入后翻译结果会显示在右侧。而且可以切换目标语言。翻译速度也是非常流畅。
Detector 和 Translator 经常配合使用,因为 Translator 需要明确源语种是什么,所以往往要先用 detector 判断。
这两个处理语言的 API,和其他 API 最大的差异就是不支持流式输出,必须要把全部输入处理完。这也很好理解,检测和翻译的结果往往是确定的,如果流式处理,可能会因为前期断章取义而导致生成结果反复改动。

接着我们来看看 Prompt API,也是我觉得可玩性最高的 API,它让我们能用自然语言和模型交互,比如做一个 Chatbot 和它聊天。它支持配置 topK 和 temperature,topK 用来设置生成下一个 token 是 的选择范围,而 temperature 则用来设置生成内容是偏严谨还是偏发散。
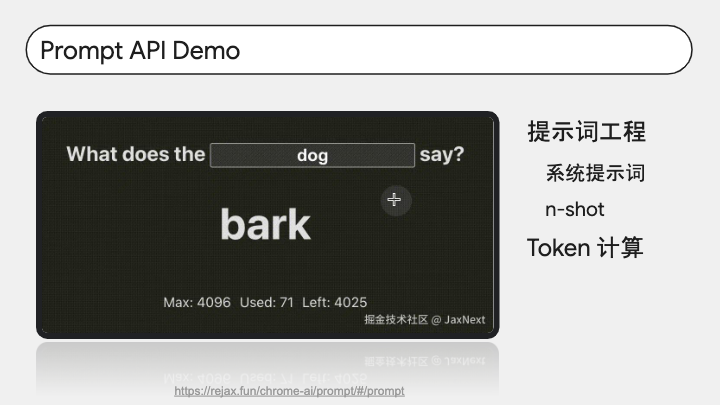
Prompt API 还支持设置系统提示词,你可以给它设定角色,让它以特定的方式处理和生成内容。比如我写的这个小玩具,也许大家听过那句歌词「what does the fox say」,于是我就设置了系统提示词,并给了模型几个例子,让它根据输入的动物名称返回该动物的叫声。还是挺有趣的。
另外 Prompt API 还支持 token 计算。以前上下文窗口有 4096 个 token 的限制,现在已经扩充到 6144 个了,单条提示词以前的 token 限制是 1024 个,现在已经没有限制了。
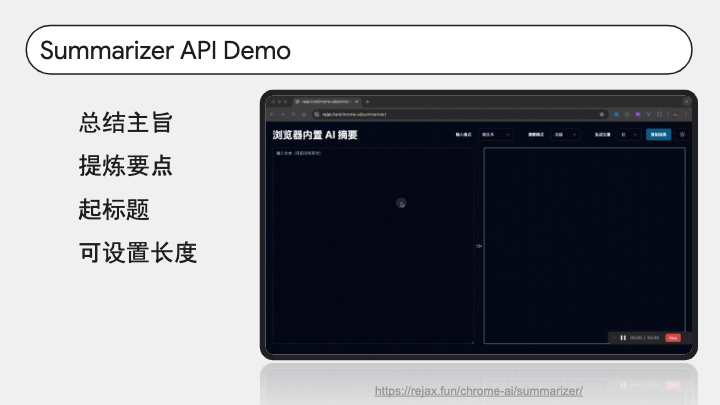
我们再来看看总结 API。它用于把一段长文本总结成短文本,我们可以通过参数来控制生成类型,可以总结主旨,可以为这段文本写一段导语,还能给一篇文章起标题,还能设置生成篇幅。无论是平时需要阅读大段文字,还是需要产出文字,它都是很好的帮手。
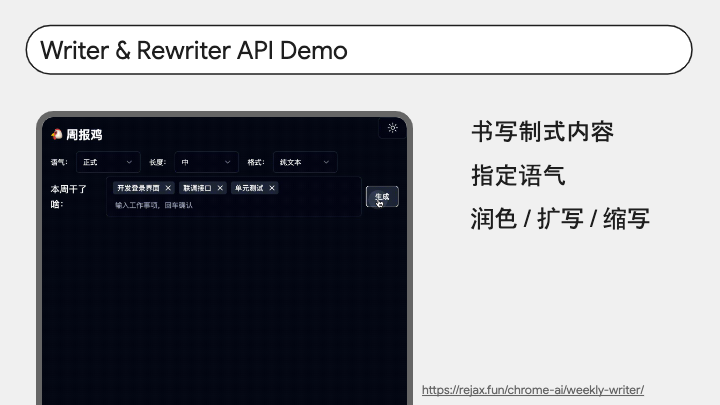
最后是 Writer 和 Rewriter API,二者非常类似,都是按照我们提供的上下文和要求生成一段文本,比如写一封请假的邮件,把邮件的语气改得正式一些等等。
左侧 Demo 是我做的一个周报生成器,我们只要把这一周做了哪几件事告诉它,它就能写成一篇结构化的周报。
OK,刚刚把内置 AI 目前的 API 都介绍给大家了,有了这些 API,我们自己开发 Web 应用,无论是网页还是浏览器扩展,都可以直接用简洁的 JavaScript 代码获取到 AI 能力。。如果大家觉得「哟?有点儿意思」,那接下来我们就来说说这套 API,我们怎么用它,以及怎么用好它。
由于这套 API 目前还处于实验阶段,所以在 Chrome 中默认是关闭的,我们需要一点点操作,来解锁 API。那这部分,我就来介绍这套实验性质的 API 的解锁方法。

首先,很重要但不紧急的一件事,我建议大家加一下 Early Preview Program,这是一个 Google Group,相当于一个开发者内测群,官方团队和其他已经在用 API 的开发者都在这个小组里。官方团队会把最新进展同步到小组里,而且你有任何问题都可以丢到小组里,团队成员会非常认真地给你解答。所以加入 EPP 会让你更清楚正在发生什么。加入 EPP 的方式是填写一个问卷。
我们认真填写然后提交,之后会有两到三天的审核期,然后,你就会收到邀请加入的邮件了。
但就算还没收到邀请邮件,其实也不耽误咱们玩内置 API,我们可以申请和解锁同时进行。
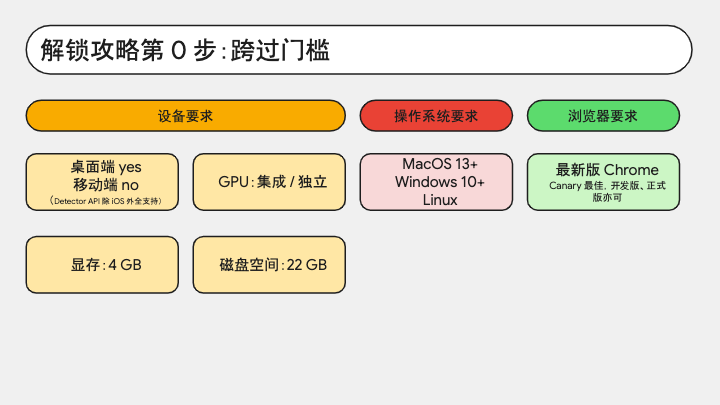
其次需要大家了解的就是,API 对你使用的设备有一定要求。
这其中 Detector API 比较随和,除了 iOS 之外,任何桌面端和移动端设备都能运行。不支持 iOS 是因为内核不兼容。
而对于其他 API,虽然用的是小参量模型,但推理还是需要一定的算力保障的。所以目前支持桌面端,移动端设备像平板、手机暂时还不行;GPU 方面没有限制,集成显卡独立显卡都可以;内存的最低要求是 4GB;另外需要 22GB 磁盘空间,但实际上模型没这么大,detector 模型的大小大概几百 KB;翻译模型的话每种语言的语言包不会超过一百兆;Gemini Nano 3.25B 大概也就 2GB 左右,所以这个磁盘要求其实是为了留有余量的。
操作系统方面,支持 13 及以上的 MacOS、10 及以上的 Windows,Linux 没有明确版本限制。
浏览器方面,建议大家直接安装最新版,目前正式版、开发版和 Canary 版都能解锁,但还是推荐 Canary,因为新功能和 Bug 修复都会先发到 Canary 上,而且更新频率很高。
之前还要求系统语言和浏览器语言都得是英文,但我前几天特意切到中文环境试了试,也不影响,都能解锁了。

OK,如果我们检查自己的设备发现都符合上面的条件,那现在我们就可以正式进入解锁攻略了。
首先,Chrome 里的实验性功能一般由 flag 开关来控制,一般是每个每个功能点对应一个 flag。我们在 Chrome 地址栏输入 Chrome://flags 就会进入 Flag 页面,然后我们在页面最上方的搜索栏输入关键词,把我们需要解锁的功能找到,然后点击右边按钮启用就行了。这里有几个特殊之处,左侧截图里第一项,以及 Translator,都在右边选最长的那个选项即可;然后 Prompt API 默认是不能生成非英语内容的,但是可以通过 text-safety-classifier 这个 Flag 来绕开,同样也是选择最长的那个选项。
切换选项后,Chrome 会提示你重启浏览器,我们重启。

接着我们来到第二步。我们在上一步只是开启了开关,但是模型还没下载到本地,所以现在我们需要通过手动的方式来激活一下这个过程。
我们先打开 Chrome 开发者工具,然后切换到 Console 界面,输入 ai 然后回车执行,正常情况下我们会看到在 ai 这个命名空间下存放着刚才我们开启了 flag 的 API。
接着我们执行这两条语句,目的是激活模型下载。所以如果执行完有报错,只要不是说模型不可用,就都没事可以先忽略。

第三步,我们在 Chrome 地址栏输入 chrome://components/,在页面中搜索「model」找到「Optimization Guide On Device Model」这一项,你应该会看到「正在更新」的状态,如果不是,你就手动点击下面的按钮启动模型下载,这个过程一般要等一小会儿。下载完成后,Prompt、Summarizer、Write、Rewriter 这几个就可以用了。
而对于翻译 API,我们在 components 页面上搜索 TranslateKit,把搜到的配置项都点一遍。至于翻译 API 需要的语言包,你可以选择都提前下载好,也可以选择用到时再下载。
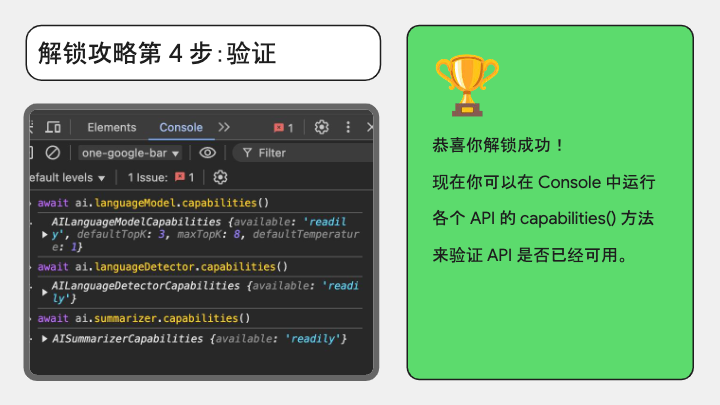
第四步,等到模型都下载完了,我们就来验证一下环境是否配好了。
【第3321期】在 Chrome中直接调用大型语言模型的API
还是在开发者工具的 Console 界面,我们执行各个 API 的 capabilities 方法,如果返回的是「available: ‘readily’」,就代表已经可以使用了,恭喜你喜提内置 AI!可以玩起来了。
刚刚介绍了解锁步骤,虽然不难,但还是有点繁琐的,那如果我想在我的产品中用这些 API,难道还得手把手带用户去设置一遍吗?
其实不用,我们之前提到还有 OT 这种内测模式,让用户访问我们的 Web 应用时静默开启实验性功能,不需要用户手动设置。那这部分我就来介绍一下 OT 怎么玩。
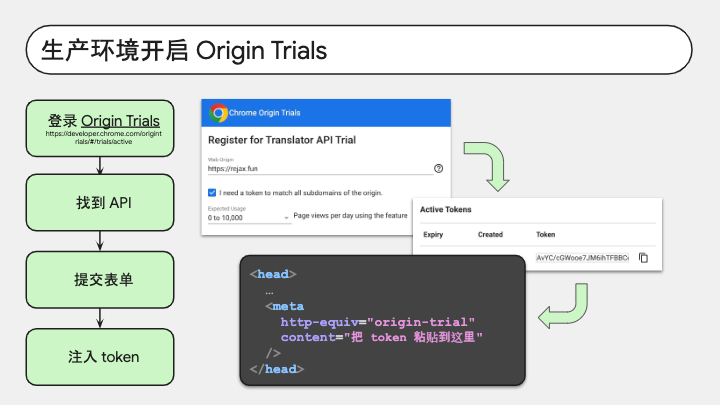
我们先登录 Origin Trials 官方平台,登录账号,然后在 API 列表里找到想要开启 OT 的 API,点击右侧的「Register」按钮进入表单页,也就是右侧第一张截图。我们把 Web 应用的域名填进去,该勾选的勾选上,提交表单就可以了。
表单提交后,会跳转到详情页,我们可以在「Active token」那一栏看到针对我们的域名生成的 token,也就是第二张截图那个界面。我们把 token 复制出来,用 meta 标签的形式插入到 HTML 代码里就行了。就像第三张截图里显示的那样。
这样,当我们把产品部署上线,用户在自己浏览器打开 URL,Chrome 校验到这个域名有 OT token,就会自动开启对应的 API 功能。还是比较方便的。

OK,以上介绍了我们怎么去迈进内置 API 的门槛,那么接下来,我将结合我几个月来高频使用的经验,来帮大家用好它。
首先就是这套 API 还处于实验阶段,不是所有浏览器、所有的用户设备都支持,所以我们要在使用具体方法之前,总是检测可用性,在不可用的情况下保证优雅降级。
第二个就是,虽然 API 已经针对特定任务进行了封装,但提示词技巧还是非常重要的,巧妙的提示词可以取得意想不到的效果。那正好 Prompt API 是一个练习提示词的好地方。
第三个就是,大模型是有上下文窗口限制的,它比如 Prompt API 目前的窗口是 6144 个 token,如果历史对话加起来超过 6144 了,那它就会把超出的部分忘掉。所以为了保证稳定的生成效果,我们需要留意 token 消耗情况,在每一轮交互前,我们计算一下会不会超出窗口限制,如果会,那就需要重新创建一个 session。所以这里的一个巧妙的做法是,我们在应用初始化的时候,创建一个 session 作为模板,不要用它去接收指令,而是用 clone 方法复制一个副本出来,去消耗副本的 token,副本消耗完了就再从原始模板复制一个出来,这样就能保持稳定运行。
这三点是能提升用户体验和生成质量的。那么接下来有两个开源库可以提升开发体验,第一个是官方团队的 TS 支持库,增加 ai 命名空间下的语法检查。那如果像刚才提到的检测可用性、注入 OT token,你不想总是写这些重复性体力劳动代码,那可以用这个工具箱,这是我在使用过程中总结提炼出来的一些方法,会让开发变得更舒适,欢迎大家使用,也欢迎大家和我一起共建。
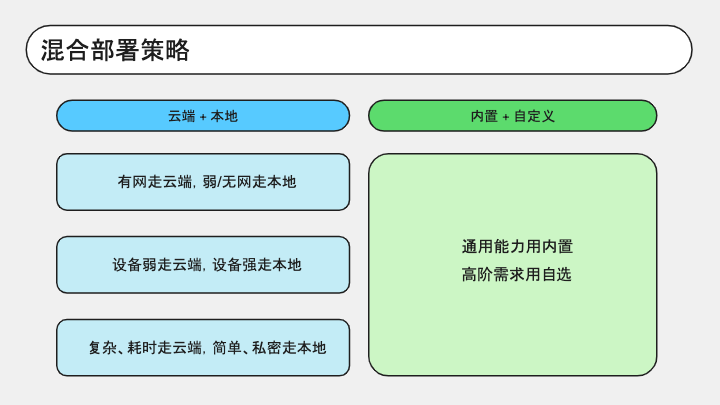
另外关于前面提到的混合部署策略,我分享一下我对于混合的理解。
【第3411期】AIGC在活动业务中的探索与应用
首先是本地和云端的混合,我们可以根据自己的业务情况去采取不同的切换策略。
另外在纯 Web AI 范畴里,我们也可以把内置 AI 和自选模型混合起来,内置 AI 作为通能能力,再用特色模型锦上添花,二者取长补短,就能产生一加一大于二的效果。
OK,那我们进入最后一小节
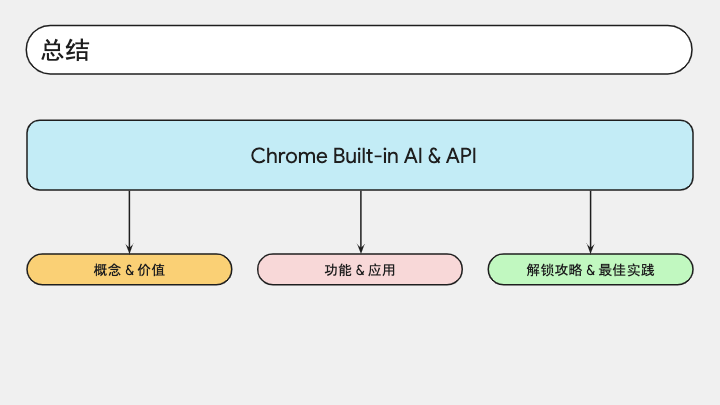
我们今天聊了 Chrome 内置 AI 以及配套的 API,讨论了什么是内置 AI,它的价值是什么,它有什么功能,能用在哪里,以及如何使用它,如何用好它。
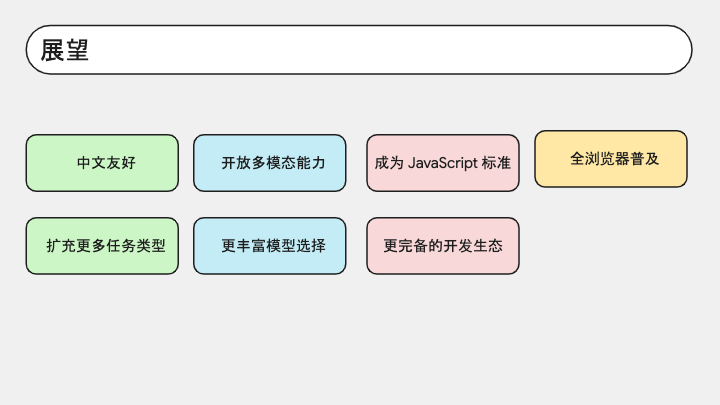
虽然内置 AI 还处于实验阶段,还不是很成熟,但这是具有开创意义的创举,代表着 Web 技术栈在 AI 时代的进化脚步。而且这肯定不是内置 AI 的最终形态,它未来会对非英语语种有更好的支持,随着使用人数增多,会有更多任务类型被发掘出来;而且 Gemini Nano 本身是一个多模态模型,以后它一定会开放多模态能力,到时候 JavaScript 就能读懂音频和图片了。我们也希望内置 AI 能够尽快得到普及,成为语言标准和浏览器必备功能。也希望更多开发者一起参与进来,我们一起把 Web AI 生态建设得更强大。
【图书】AI辅助编程入门:使用GitHub Copilot零基础开发
关于本文
作者:@JaxNext
原文:https://juejin.cn/post/7445566634469998632

这期前端早读课
对你有帮助,帮” 赞 “一下,
期待下一期,帮” 在看” 一下 。







