
本文基于几篇经典的论文,对 Attention 模型的不同结构进行分析、拆解。
先简单谈一谈 attention 模型的引入。以基于 seq2seq 模型的机器翻译为例,如果 decoder 只用 encoder 最后一个时刻输出的 hidden state,可能会有两个问题(我个人的理解)。
1. encoder 最后一个 hidden state,与句子末端词汇的关联较大,难以保留句子起始部分的信息;
2. encoder 按顺序依次接受输入,可以认为 encoder 产出的 hidden state 包含有词序信息。所以一定程度上 decoder 的翻译也基本上沿着原始句子的顺序依次进行,但实际中翻译却未必如此,以下是一个翻译的例子:
英文原句:space and oceans are the new world which scientists are trying to explore.
翻译结果:空间和海洋是科学家试图探索的新世界。
词汇对照如下:

可以看到,翻译的过程并不总是沿着原句从左至右依次进行翻译,例如上面例子的定语从句。
为了一定程度上解决以上的问题,14 年的一篇文章 Sequence to Sequence Learning with Neural Networks 提出了一个有意思的 trick,即在模型训练的过程中将原始句子进行反转,取得了一定的效果。
为了更好地解决问题,attention 模型开始得到广泛重视和应用。
下面进入正题,进行对 attention 的介绍。
Show, Attend and Tell

■ 论文 | Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
■ 链接 | https://www.paperweekly.site/papers/812
■ 源码 | https://github.com/kelvinxu/arctic-captions
文章讨论的场景是图像描述生成(Image Caption Generation),对于这种场景,先放一张图,感受一下 attention 的框架。
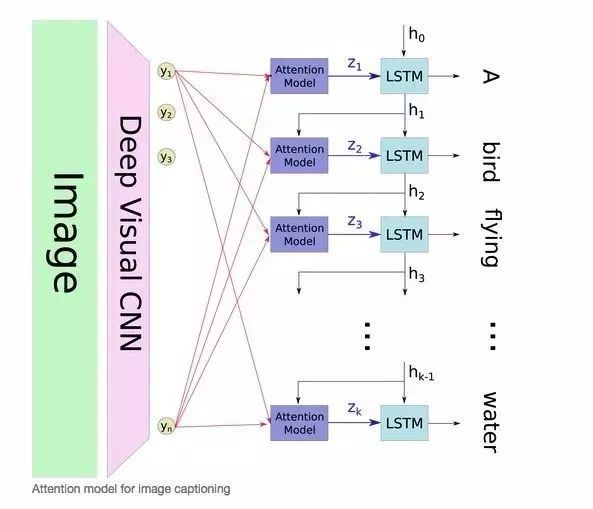
文章提出了两种 attention 模式,即 hard attention 和 soft attention,来感受一下这两种 attention。


1. Stochastic “Hard” Attention
记 St 为 decoder 第 t 个时刻的 attention 所关注的位置编号, Sti 表示第 t 时刻 attention 是否关注位置 i , Sti 服从多元伯努利分布(multinoulli distribution), 对于任意的 t ,Sti,i=1,2,…,L 中有且只有取 1,其余全部为 0,所以 [St1,St2,…,stL] 是 one-hot 形式。这种 attention 每次只 focus 一个位置的做法,就是“hard”称谓的来源。 Zt 也就被视为一个变量,计算如下:


接下来的一些细节涉及reinforcement learning,感兴趣的同学可以去看这篇 paper。
2. Deterministic “Soft” Attention
说完“硬”的 attention,再来说说“软”的 attention。 相对来说 soft attention 很好理解,在 hard attention 里面,每个时刻 t 模型的序列 [ St1,…,StL ] 只有一个取 1,其余全部为 0,也就是说每次只 focus 一个位置,而 soft attention 每次会照顾到全部的位置,只是不同位置的权重不同罢了。这时 Zt 即为 ai 的加权求和:

btw,模型的 loss function 加入了 αti 的正则项。

■ 论文 | Effective Approaches to Attention-based Neural Machine Translation
■ 链接 | https://www.paperweekly.site/papers/806
■ 源码 | https://github.com/lmthang/nmt.matlab
文章提出了两种 attention 的改进版本,即 global attention 和 local attention。先感受一下 global attention 和 local attention 长什么样子。
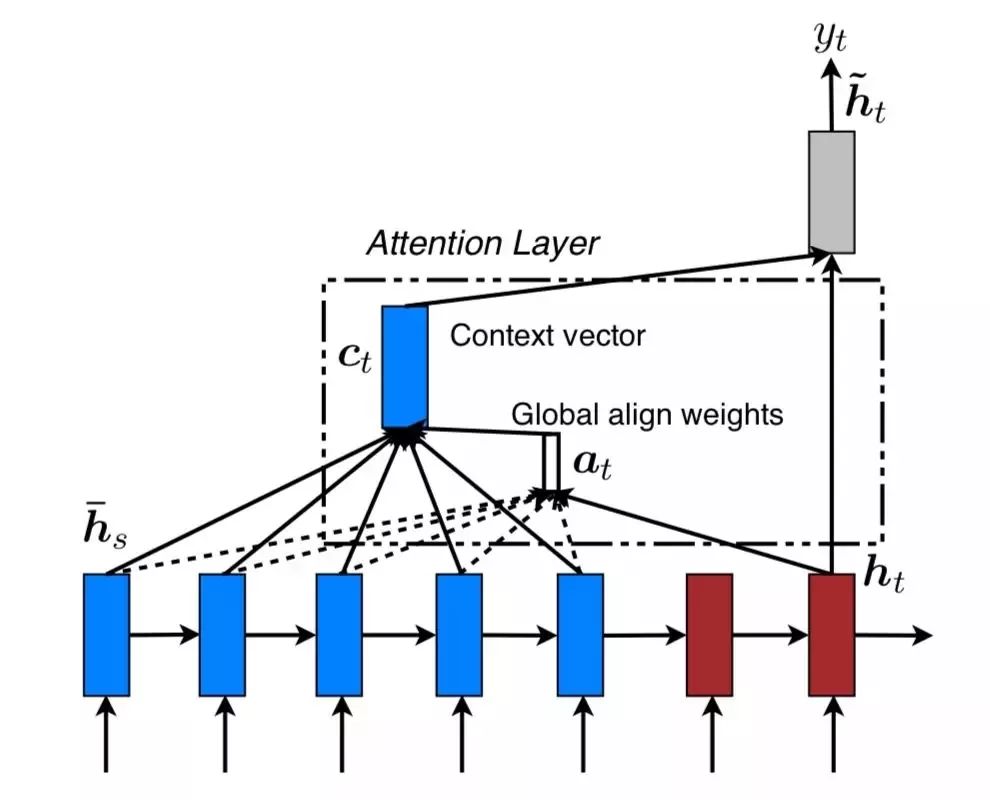
Global Attention
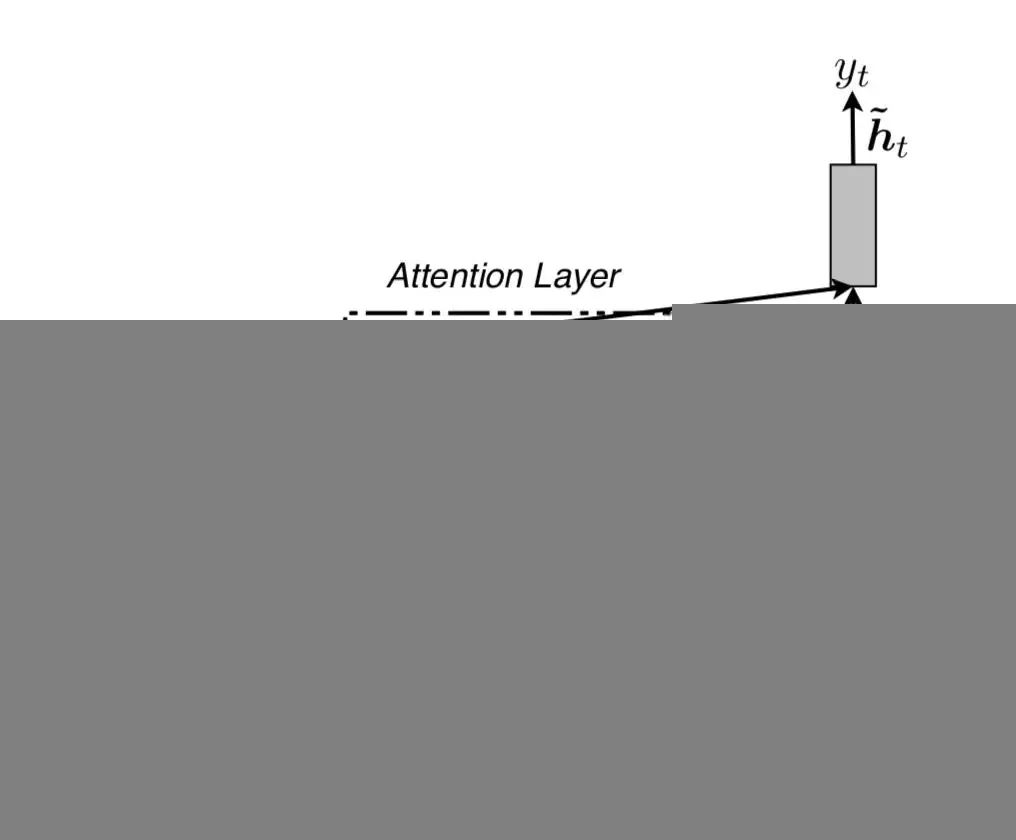
Local Attention
文章指出,local attention 可以视为 hard attention 和 soft attention 的混合体(优势上的混合),因为它的计算复杂度要低于 global attention、soft attention,而且与 hard attention 不同的是,local attention 几乎处处可微,易与训练。 文章以机器翻译为场景, x1,…,xn 为 source sentence, y1,…,ym 为 target sentence, c1,…,cm 为 encoder 产生的 context vector,objective function 为:
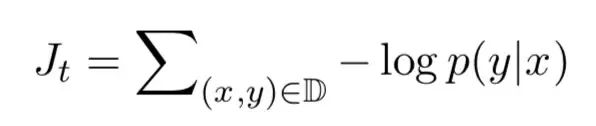
Ct 来源于 encoder 中多个 source position 所产生的 hidden states,global attention 和 local attention 的主要区别在于 attention 所 forcus 的 source positions 数目的不同:如果 attention forcus 全部的 position,则是 global attention,反之,若只 focus 一部分 position,则为 local attention。
由此可见,这里的 global attention、local attention 和 soft attention 并无本质上的区别,两篇 paper 模型的差别只是在 LSTM 结构上有微小的差别。
在 decoder 的时刻 t ,在利用 global attention 或 local attention 得到 context vector Ct之后,结合 ht ,对二者做 concatenate 操作,得到 attention hidden state。
下面重点介绍 global attention、local attention。
1. global attention

2. local attention
global attention 可能的缺点在于每次都要扫描全部的 source hidden state,计算开销较大,对于长句翻译不利,为了提升效率,提出 local attention,每次只 focus 一小部分的 source position。
这里,context vector ct 的计算只 focus 窗口 [pt-D,pt+D] 内的 2D+1 个source hidden states(若发生越界,则忽略界外的 source hidden states)。
其中 pt 是一个 source position index,可以理解为 attention 的“焦点”,作为模型的参数, D 根据经验来选择(文章选用 10)。 关于 pt 的计算,文章给出了两种计算方案:

Jointly Learning

■ 论文 | Neural Machine Translation by Jointly Learning to Align and Translate
■ 链接 | https://www.paperweekly.site/papers/434
■ 源码 | https://github.com/spro/torch-seq2seq-attention
这篇文章没有使用新的 attention 结构,其 attention 就是 soft attention 的形式。文章给出了一些 attention 的可视化效果图。
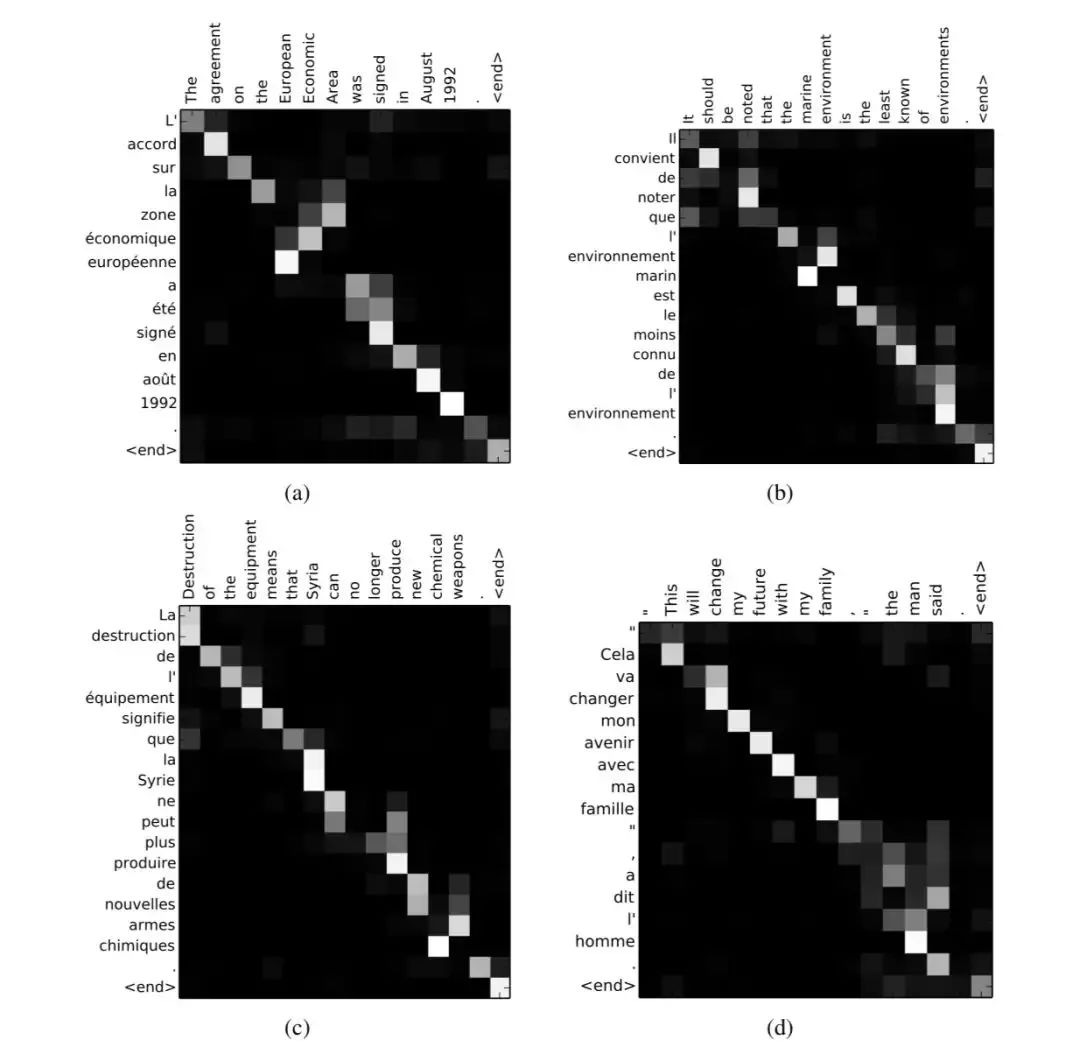
上面 4 幅图中,x 轴代表原始英文句子,y 轴代表翻译为法文的结果。每个像素代表的是纵轴的相应位置的 target hidden state 与横轴相应位置的 source hidden state 计算得到的权重 αij,权重越大,对应的像素点越亮。可以看到,亮斑基本处在对角线上,符合预期,毕竟翻译的过程基本是沿着原始句子从左至右依次进行翻译。
Attention Is All You Need
■ 论文 | Attention Is All You Need
■ 链接 | https://www.paperweekly.site/papers/224
■ 源码 | https://github.com/Kyubyong/transformer
■ 论文 | Weighted Transformer Network for Machine Translation
■ 链接 | https://www.paperweekly.site/papers/2013
■ 源码 | https://github.com/JayParks/transformer
作者首先指出,结合了 RNN(及其变体)和注意力机制的模型在序列建模领域取得了不错的成绩,但由于 RNN 的循环特性导致其不利于并行计算,所以模型的训练时间往往较长,在 GPU 上一个大一点的 seq2seq 模型通常要跑上几天,所以作者对 RNN 深恶痛绝,遂决定舍弃 RNN,只用注意力模型来进行序列的建模。
作者提出一种新型的网络结构,并起了个名字 Transformer,里面所包含的注意力机制称之为 self-attention。作者骄傲地宣称他这套 Transformer 是能够计算 input 和 output 的 representation 而不借助 RNN 的的 model,所以作者说有 attention 就够了。
模型同样包含 encoder 和 decoder 两个 stage,encoder 和 decoder 都是抛弃 RNN,而是用堆叠起来的 self-attention,和 fully-connected layer 来完成,模型的架构如下:
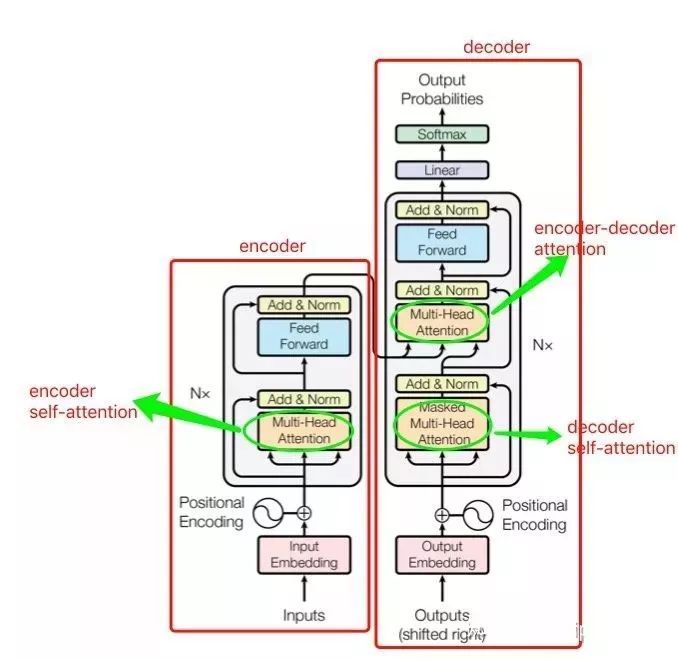
从图中可以看出,模型共包含三个 attention 成分,分别是 encoder 的 self-attention,decoder 的 self-attention,以及连接 encoder 和 decoder 的 attention。
这三个 attention block 都是 multi-head attention 的形式,输入都是 query Q 、key K 、value V 三个元素,只是 Q 、 K 、 V 的取值不同罢了。接下来重点讨论最核心的模块 multi-head attention(多头注意力)。
multi-head attention 由多个 scaled dot-product attention 这样的基础单元经过 stack 而成。
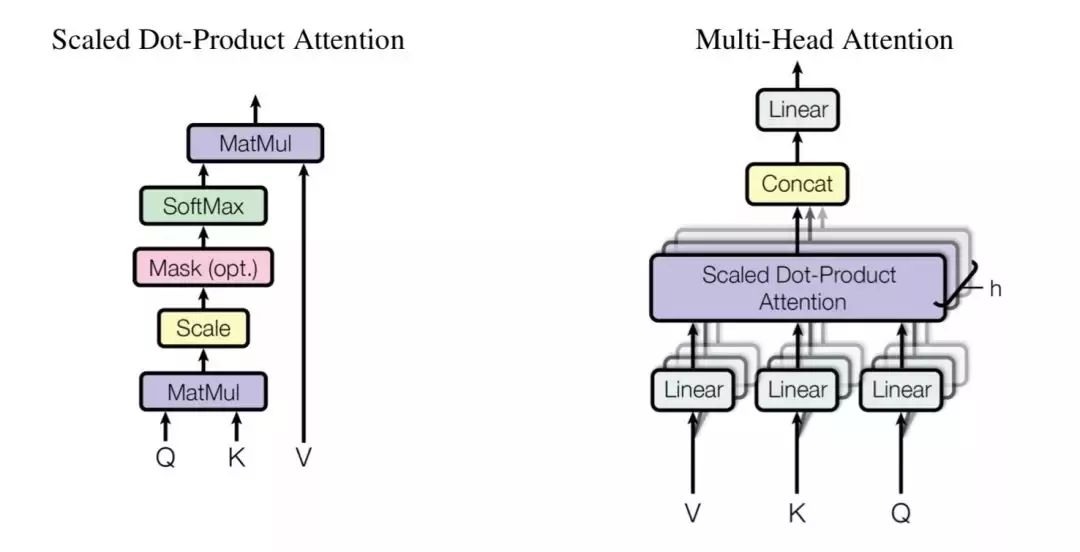
那重点就变成 scaled dot-product attention 是什么鬼了。按字面意思理解,scaled dot-product attention 即缩放了的点乘注意力,我们来对它进行研究。
在这之前,我们先回顾一下上文提到的传统的 attention 方法(例如 global attention,score 采用 dot 形式)。
我的写法与论文有细微差别,但为了接下来说明的简便,我姑且简化成这样。这个 Attention 的计算跟上面的 (*) 式有几分相似。










