 点击 Chatbots技术与产品,快速关注本账号!
点击 Chatbots技术与产品,快速关注本账号!

一、复述的简介
复述(Paraphrase)是自然语言中比较普遍的一个现象,它集中反映了语言的多样性。复述研究的对象主要是有关短语或者句子的同义现象。随着自然语言处理各种底层技术的不断发展和成熟,对复述技术的需求也越来越强烈,因此有关复述的研究受到越来越多的关注。在英文和日文方面,复述技术已经被成功的应用到自然语言处理的多个领域,有效地提高了这些系统的性能。
综述现有的研究成果,可将复述现象划分为以下几类:
(1)细微变化。细微变化指的是功能词的增删与替换;
(2)同义短语替换。同义短语替换指的是将原文中的短语替换成其同义短语;
(3)词典注释替换。词典注释替换是指将原文中的词替换成词典中的注释;
(4)语序替换。语序替换是指在不改变原文意思的前提下移动原文中某些成分的位置;
(5)句子结构变换。句子结构变换是一种复杂的复述现象。这类复述往往不是对原文的个别成分进行简单的替换或变化,而是对原文进行较大的改动,以至于复述前后的句子结构会产生明显的变化;
(6)句子拆分与合并。句子拆分是指将一个复杂的长句拆分成若干等价的简单短句;句子合并恰恰与上述过程相反;
(7)基于推理的复述。基于推理的复述是指那些需要使用某些背景知识才能正确识别和理解的复述。
复述研究可大致分为两部分,一部分是复述资源获取,包括构建复述句库、获取复述短语和复述模板等;另一部分是复述生成,即针对给定文本片段(通常是句子)生成复述。
二、复述的应用
复述在自然语言处理的许多领域中都有着重要的应用。其中,讨论最广泛、应用最多的当属在机器翻译(Machine Translation,简称MT)领域中。根据已有的研究,复述可以有效的解决机器翻译中的数据稀疏的问题,并且复述可以将不规范的句子改写为规范的句子,这无疑会降低翻译系统的处理难度。
自动问答(Question Answering,简称QA)是复述的另外一个重要应用领域。在自动问答系统的问句理解部分,复述可以将用户提问的一个复杂问句改写成一组简单的子句,这些子句每一个都含有原问句所携带信息的一部分。这种改写大大简化了系统对问旬的理解和之后的处理。在系统的答案抽取部分,复述可以用来将问旬扩展成句群,并全部提交给系统以解决表达不匹配的问题,这可以在很大程度上提高答案抽取的召回率。
在信息检索(Information Retrieval,简称IR)中,复述通常用来进行查询扩展。已有工作表明经过复述处理之后的查询扩展可以有效地提高瓜系统的性能。
在自动文摘(Summarization)的研究中,复述的作用现在两个方面。一方面,复述可用于计算句子的相似度,识别出那些意思相同或者相近的句子。另一方面,复述还可以用于机器生成文摘的自动评价。
在自然语言生成(Natural Language Generation,简称NLG)中,复述可被应用于自动生成句子的改写,以使生成的句子更加生动、通顺和富于变化。
除了上面介绍的应用领域外,复述还在其他一些领域中扮演者重要的角色。例如复述技术可用于句子的自动校正,即把存在用词或句法错误的句子复述为正确的句子;复述还可用于辅助阅读,通过将复杂、深奥的文本复述为简单易懂的文本,以减轻有语言障碍者的阅读困难;在秘密学和文本水印的研究中,复述可用于句子改写,进而达到信息隐藏的目的;此外,复述技术还有助于文章抄袭和剽窃现象的自动发现。由于复述在众多领域中的应用使其成为自然语言处理中一个重要的研究方向。甚至有学者将复述与问答、文摘与翻译并列为衡量计算机是否理解自然语言的四条准则。由此,复述研究的重要程度可见一斑。
三、复述模板的抽取
复述模板抽取是指利用包括词典、语料库在内的各种资源抽取复述。这里的复述既包括词汇级,也包括短语级和句子级。其中,许多短语级和词汇级复述的抽取技术都基于已经获得的复述句。抽取出的复述短语和复述词又可以直接应用于之前介绍的自动问答、机器翻译、信息抽取等各种研究中,也可以用于之后的复述生成。这里主要介绍复述模板和复述搭配的抽取的相关技术。
复述模板的抽取一直是研究者关注的重点。这里将重点介绍基于依存句法结构树和《知网》相似度的复述模板抽取。复述模板抽取的前提是我们已经获取了复述句(人工标注的复述句)。
下面介绍子树和部分子树的定义:
子树:一颗子树STE(e)为句法树TE中的的一个连通子图,它以e为根节点,并且包含e的所有子孙节点。
部分子树:一颗部分子树PSTE(e)为子树STE(e)的一个连通子图,它以e为根节点,但舍弃e的任意一个或多个子树节点。
对于上面的定义,我们可以看出一颗句法树可以包含多棵子树,而一颗子树又可以包含多棵部分子树。对于句子“我们已经把他的名字报备司法部”,其句法树TE、子树STE(报备)和部分子树PSTE(报备)如图1所示。
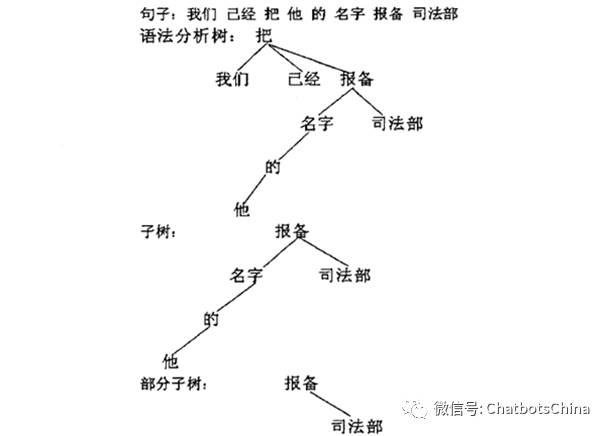
图1 句法树、子树和部分子树的实例
在对句子进行分析之后,抽取复述模板的过程可以分为两个步骤:首先,对构成复述句对的两个句子都进行模板的抽取;之后,计算模板语义相似度以进行模板的匹配。
抽取模板
如之前提到的,经过进行语法分析过的句子中的每个词语都有固定的“词语/词性”这样的形式。对于如图1中的部分子树PTSE(报备)含有字符串“⋯报备司法部”。我们可以从中抽取出模板“X 报备 司法部”。为了限定在“X”位置可以出现的词语的类型,我们考虑STE(报备),并使用出现在STE(报备)而未出现在PSTE(报备)的词的类型来限定槽的类型。在例子中槽中应填入的是“他的 名字”,但是若把所有的词语词性都来填充模板槽,会导致抽取的模板过于具体和复杂,并且,在依存句法中,“他 的”是对“名字”的修饰。因此,我们只保留节点e(报备)孩子节点的词性。综上所述,抽取出来的模板即是"N 报备 司法部”。表1描述了具体算法过程。

表1 中文模板抽取算法描述
匹配模板
经过第一个步骤的处理之后,互为复述句的每个句子都可以得到一个或多个模板。在第二个步骤,我们将互为复述句的句子抽到的模板进行匹配。根据复述模板的定义,每一个模板都表达了特定的含义,并且两个或多个模板在表达相同含义的情况下运用不同的表达。因此,我们可以认为互为复述模板的两个模板所使用的词语也具有一定的语义相似性。基于这样的考虑,本文通过词语来计算两个模板的语义相似度。
定义:对于两个模板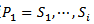 ,
,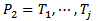 定义两个模板的语义相似度的计算公式如下:
定义两个模板的语义相似度的计算公式如下:
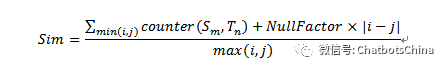
其中,NullFactor是一个较小的常数,在我们的实验中我们将其设定为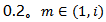 ,
,
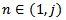 ,
,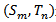 是两个模板中相对应的词对,但是对于给定的两个模板我们并不知道哪两个词语是相对应的,在本章中我们将获得相似度最大值的两个词语当作词对,
是两个模板中相对应的词对,但是对于给定的两个模板我们并不知道哪两个词语是相对应的,在本章中我们将获得相似度最大值的两个词语当作词对,
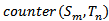 就代表计算得到的词对的语义相似度,循环这样的相似度最大值的计算就可以得到两个模板中所有的词对和词对相似度。
就代表计算得到的词对的语义相似度,循环这样的相似度最大值的计算就可以得到两个模板中所有的词对和词对相似度。
在这里词语的语义相似度计算是基于《知网》知识库的相似度。《知网》是由董振东和董强先生创建,是一部以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。基于知网的词语语义相似度计算公式如下:
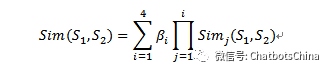
其中,Sim1,Sim2,Sim3,Sim4分别代表第一基本义原、其它基本义原、关系义原、关系符号的相似度,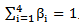 且
且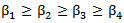 。我们设定了阈值,当计算得出的两个模板语义相似度值大于阈值时,我们就认为两个模板为复述模板。
。我们设定了阈值,当计算得出的两个模板语义相似度值大于阈值时,我们就认为两个模板为复述模板。
本文来源于《中文复述模板及搭配抽取方法研究》和《复述技术研究》
- END -
非常欢迎加入我们的微信群一起讨论分享!
新浪微博:ChatbotsChina
微信号:Chatbots01


关注我们,一起学习机器人






