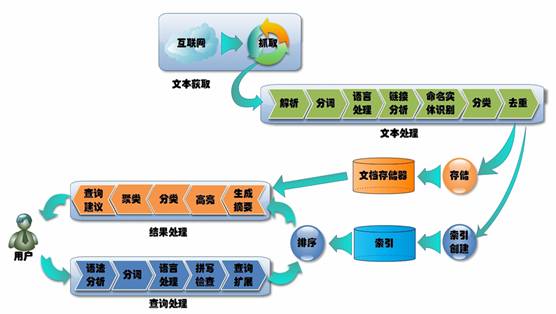
这个图是一个经典的搜索引擎的架构图。
说到大数据,首先我们来看一下数据的分类,我们生活中的数据总体分为两种: 结构化数据和非结构化数据。
结构化数据: 指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据: 指不定长或无固定格式的数据,如邮件, word 文档等
当然有的地方还会提到第三种,半结构化数据,如 XML, HTML 等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
随着互联网的发展,非结构化数据越来越多,当我们遇到这么多数据的时候,怎么办呢?分为以下的步骤:
数据的收集:即将散落在互联网世界的数据放到咱们的系统中来。数据收集分两个模式,推和拉,所谓的推,即推送,是在互联网世界里面放很多自己的小弟程序,这些小弟程序收集了数据后,主动发送给咱们的系统。所谓的拉,即爬取,通过运行程序,将互联网世界的数据下载到咱们的系统中。
数据的传输:收到的数据需要通过一个载体进行传输,多采用队列的方式,因为大量的数据同时过来,肯定处理不过来,通过队列,让信息排好队,一部分一部分的处理即可。
数据的存储:好不容易收集到的数据,对于公司来讲是一笔财富,当然不能丢掉,需要找一个很大很大的空间将数据存储下来。
数据的分析:收到的大量的数据,里面肯定有很多的垃圾数据,或者很多对我们没有用的数据,我们希望对这些数据首先进行清洗。另外我们希望挖掘出数据之间的相互关系,或者对数据做一定的统计,从而得到一定的知识,比如盛传的啤酒和尿布的关系。
数据的检索和挖掘:分析完毕的数据我们希望能够随时把我们想要的部分找出来,搜索引擎是一个很好的方式。另外对于搜索的结果,可以根据数据的分析阶段打的标签进行分类和聚类,从而将数据之间的关系展现给用户。
当数据量很少的时候,以上的几个步骤其实都不需要云计算,一台机器就能够解决。然而量大了以后,一台机器就没有办法了。
所以大数据想了一个方式,就是聚合多台机器的力量,众人拾柴火焰高,看能不能通过多台机器齐心协力,把事情很快的搞定。
对于数据的收集,对于IoT来讲,外面部署这成千上万的检测设备,将大量的温度,适度,监控,电力等等数据统统收集上来,对于互联网网页的搜索引擎来讲,需要将整个互联网所有的网页都下载下来,这显然一台机器做不到,需要多台机器组成网络爬虫系统,每台机器下载一部分,同时工作,才能在有限的时间内,将海量的网页下载完毕。开源的网络爬虫大家可以关注一下Nutch。
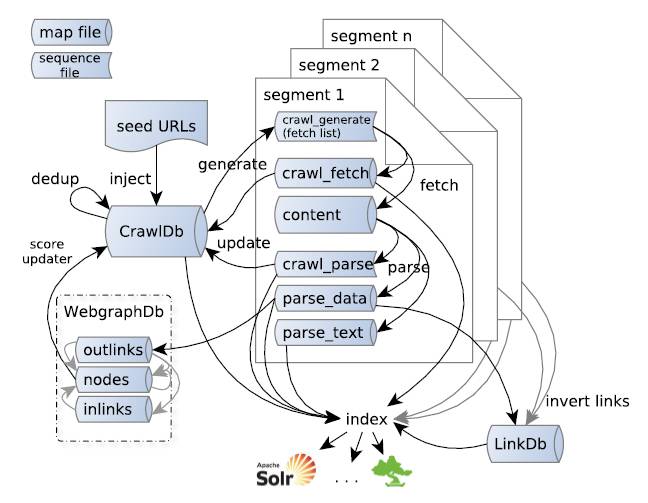
对于数据的传输,一个内存里面的队列肯定会被大量的数据挤爆掉,于是就产生了Kafka这样基于硬盘的分布式队列,也即kafka的队列可以多台机器同时传输,随你数据量多大,只要我的队列足够多,管道足够粗,就能够撑得住。
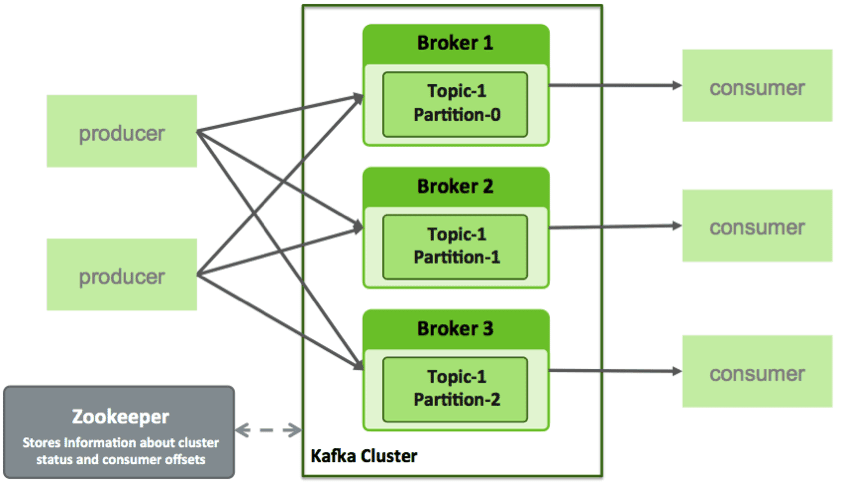
对于数据的存储,一台机器的硬盘肯定是放不下了,所以需要一个很大的分布式存储来做这件事情,把多台机器的硬盘打成一块大硬盘(而非存储池,注意两者的区别),hadoop的HDFS可以做到,也有很多地方用对象存储,同样可以有非常大的空间保存海量的数据。
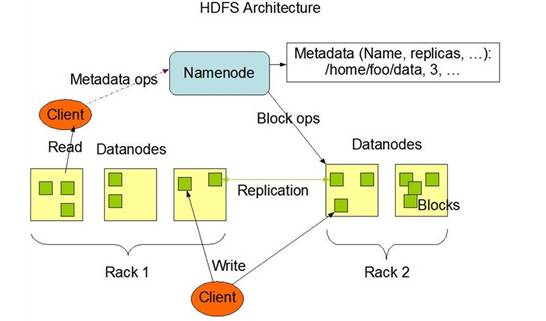
这个图描述的HDFS的一个架构,可以产出来,HDFS将很多个DataNode管理在一起,将数据分成很多小块,分布在多台机器上,从而实现了海量数据的存储。
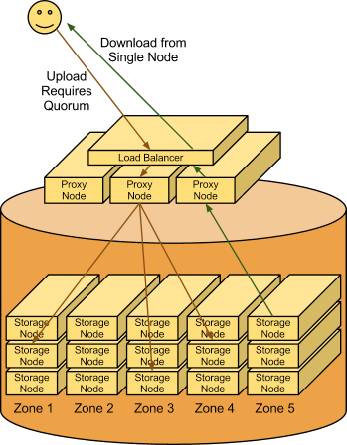
这个图描述的是swift对象存储的架构,也是将很多的storage node聚合在一起,实现海量的存储。
对于数据的分析,一台机器一篇一篇的分析,那要处理到猴年马月也分析不完,于是就有了map-reduce算法,将海量的数据分成多个部分,使用大规模的hadoop集群,每台机器分析一部分,这个过程叫做map,分析完毕之后,还需要汇总一下,得到最终结果,汇总的过程称为reduce。
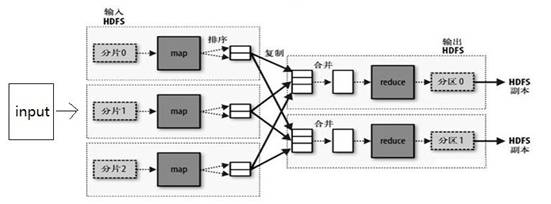
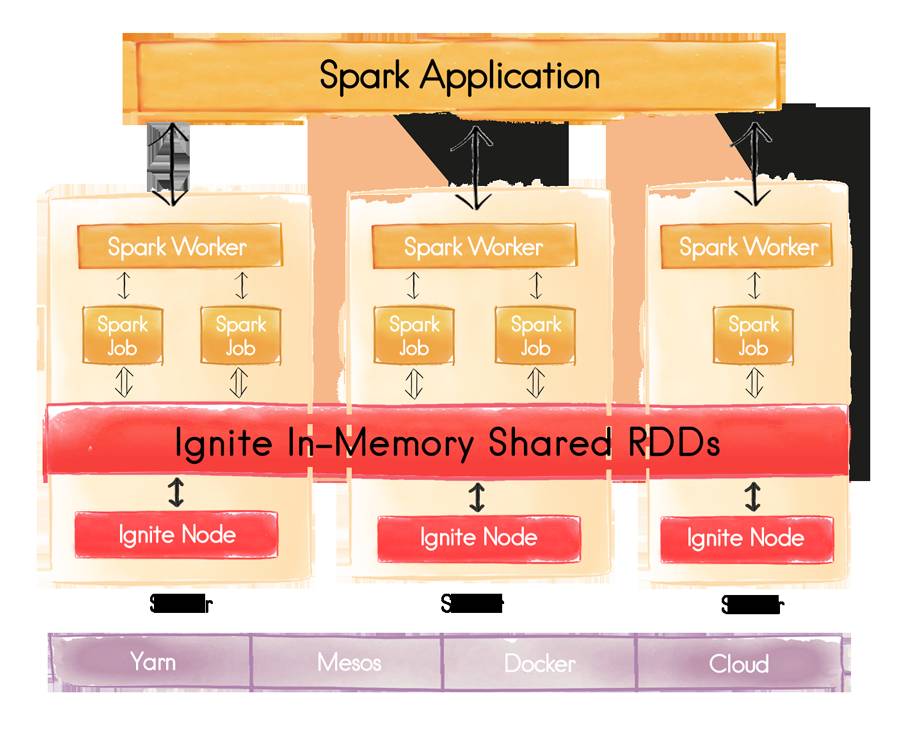
最初的map-reduce算法是每一轮分析都将结果写入文件系统的,后来人们发现往往复杂的分析需要多轮计算才能有结果,而每一轮计算都落盘对速度影响比较大,于是有了Spark这种中间计算全部放入内存的分布式计算框架。对于数据的分析有全量的离线的计算,例如将所有的用户的购买行为进行分类,也有需要实时处理实时分析的,例如股票资讯的分类,实时的计算框架有storm,spark streaming等等。
对于数据的搜索,如果使用顺序扫描法 (Serial Scanning),比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。为什么慢呢?其实是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。
如果我们通过对于非结构化数据进行处理,形成索引文件,里面保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
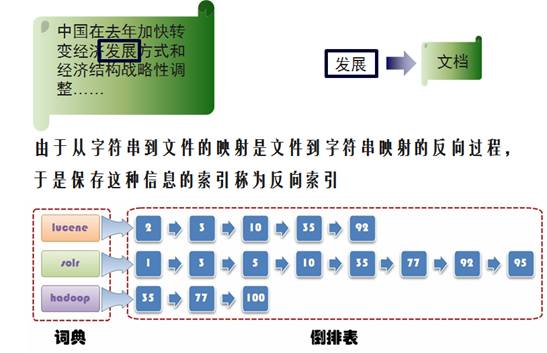
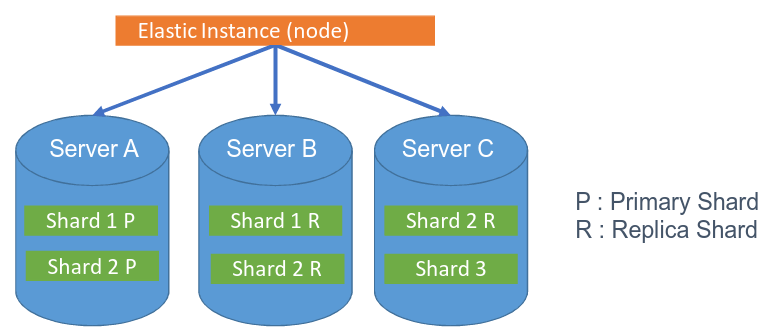
当数据量非常大的时候,一个索引文件已经不能满足大数据量的搜索,所以要分成多台机器一起搜索,如图所示,将索引分成了多个shard也即分片,分不到不同的机器上,进行并行的搜索。
所以说大数据平台,什么叫做大数据,说白了就是一台机器干不完,大家一起干。







