2025.02.
12
本文字数:2927,阅读时长大约5分钟
作者
|
新皮层NewNewThing
王杰夫、梁夏琦、吴一凡、王艺澄
全球用户增长最快的应用程序已不再是ChatGPT,而是DeepSeek。
Sensor Tower的统计显示,DeepSeek应用程序自1月11日发布后,20天左右(2月1日前后)日活用户数就超过了1000万(约1200万),达到ChatGPT(约5200万)的23%。
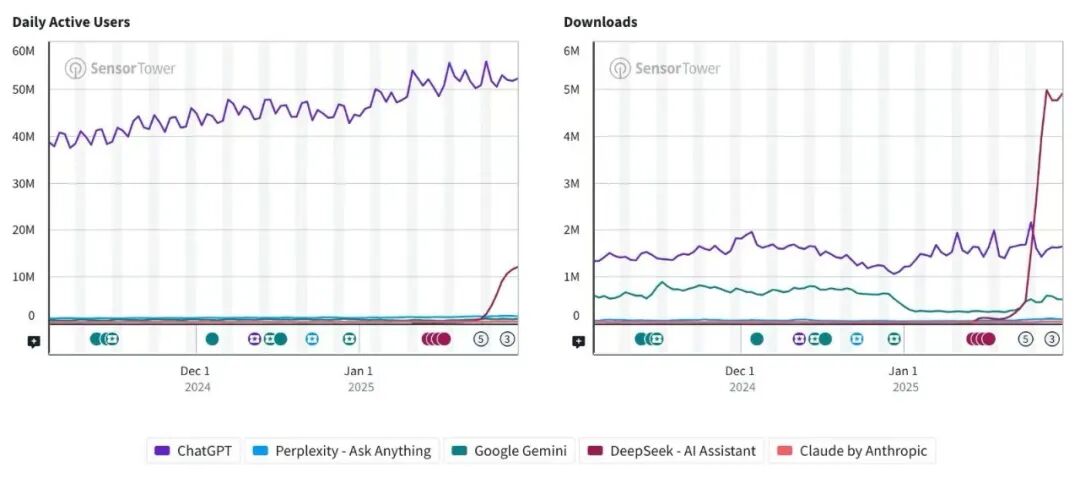
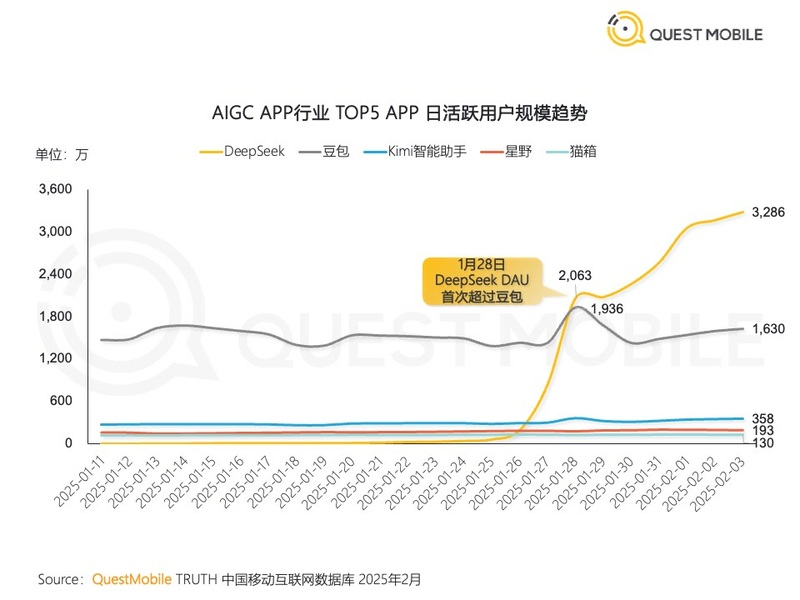
另一家统计机构QuestMobile给出的数字更加激进,它表示,DeepSeek的日活跃用户在1月28日首次超越豆包(约1695万),随后在2月1日突破3000万大关——按SimilarWeb的数据计算,ChatGPT获得同样规模的日活用了11个月时间,DeepSeek只用了20天,成为有史以来最快达到这一里程碑的应用程序。
3000万日活已经超过ChatGPT目前日活(以5200万计算)的一半,且按照目前的增速,DeepSeek在用户规模上超过ChatGPT只是时间问题。
DeepSeek改变的不止是用户的使用习惯,还有基于AI的整个生态。
给用户答案,更告诉用户为什么
自OpenAI在2024年9月推出o1模型起,OpenAI对于推理模型技术方案的保护就格外重视,它不仅没有像以往那样发布该模型的技术报告,用户多次询问ChatGPT它是怎么思考的话还会收到封号警告的邮件,OpenAI透露的关键词只有「强化学习」和「思维链」(Chain of Thought,CoT)。
所以在它之后发布的智谱GLM-Zero模型,月之暗面k0-math、k1、k1.5模型,阿里巴巴Marco-o1、QwQ模型,乃至DeepSeek的R1模型,都是各家AI公司对o1模型盲人摸象般的复现,R1模型只是其中最接近o1能力的那一个。而如今,随着DeepSeek将推理模型开源并公开了详细的技术报告,首当其冲的就是一直闭源的OpenAI。
于是在DeepSeek火爆全网时,OpenAI的反应是最快的。1月31日,OpenAI在DeepSeek成为全球媒体焦点时迅速发布了全新推理模型o3-mini,并首次向免费用户开放该模型,用户只要在提问时选中「推理」即可使用。
紧接着的2月7日,OpenAI还首次公开了o3-mini在执行推理时的思维链,就像DeepSeek做的那样,然而很快就有用户质疑这个思维链看起来像被处理过。OpenAI研究员Noam Brown表示「这些虽然不是原始的思维链,但已经非常接近了」,CEO Sam Altman也承认展示出来的思维链已经「被二次处理过」,他给出的原因是「原始思维链缺少可读性」。
行动起来的还有阿里巴巴,1月29日,阿里通义团队发布了超过20万亿token训练的MoE模型Qwen2.5-Max,特别提升了文本生成、结构化数据分析和指令遵循等能力。作为非推理模型,Qwen2.5-Max号称在数学编程等基准测试中不弱于o1与R1等推理模型。
未来几个月,在庞大的用户需求和开源社区的努力下,准o1级别的推理模型将大概率成为标配。
DeepSeek如何扩容?这是个问题,更是个机会
DeepSeek在C端市场的爆火同样极大带动了B端市场的需求。虽然DeepSeek官方一直面向B端市场提供模型调用服务,甚至
去年5月的大模型价格战
就是由这家公司首先打响的,但这一次突然暴涨的流量远远超过了其服务器的承受能力,2月6日DeepSeek官方暂停了基于API的模型调用服务充值。
这让一些第三方云厂商获得分食DeepSeek开源生意的机会。
1月29日至30日中国春节假期期间,微软、亚马逊、英伟达等美国巨头抢先宣布接入DeepSeek模型。假期过后,国内的重要云厂商阿里巴巴、华为、百度、字节、三大通信运营商等也都快速跟进,宣布自家的云平台接入了DeepSeek模型。
在此之前,大部分云厂商都会接入Llama、Mistral等知名开源模型或者洽谈部分闭源模型以满足客户的多样性需求,但在市场推广策略上还是以自研模型为主,例如阿里云主推通义模型,百度智能云主推文心模型。但如今DeepSeek模型已成为国内各家云厂商的主推模型。例如百度智能云趁机推出「首个自研万卡集群」,号称提升了模型训练与推理的效率与稳定性,并且模型调用价格比DeepSeek官方便宜一半。
同样嗅到商机的还有硅基流动、潞晨科技等新型云计算服务公司。这些公司基本都在大模型兴起之后创立,试图借助大模型这一细分市场切入云计算领域,与阿里云、华为云等传统云计算公司竞逐市场。2月1日,硅基流动宣布基于华为云的昇腾芯片部署了DeepSeek模型。随后2月4日,潞晨科技也宣布了类似合作。
然而,这些都不等于解决DeepSeek官方应用和API调用面临的容量不足问题。直到现在,用户打开DeepSeek时仍然常常收到「服务器繁忙,请稍后再试」的通知。DeepSeek将如何扩容成为国产GPU公司和云计算平台都想知道的问题——这直接意味着订单。
就在硅基流动等公司宣布基于华为的昇腾芯片部署了DeepSeek模型之后,国内的众多GPU初创公司比如沐曦、天数智芯、摩尔线程、海光信息、壁仞科技等也相继宣布适配DeepSeek模型。
「新皮层」获得的消息称,国产AI芯片目前仍然不足以满足大模型的训练需求,但已经能胜任算力需求没有那么高的推理环节。这使得AI推理市场对英伟达的依赖度降低,国产GPU公司由此获得机会。
不过也有AI芯片创业者对「新皮层」表示,DeepSeek不一定要通过自购芯片才能扩容,寻求云厂商的合作也是可选项。他猜测DeepSeek眼下可能正在与阿里云、腾讯云等云计算厂商讨论合作。
2月7日晚间,市场传闻阿里巴巴将以10亿美元投资DeepSeek,其美股股价也于当日开盘前涨了超过4%。不过阿里后来否认了该传闻。
从模型竞争转向产品竞争
作为一个开源模型,DeepSeek的低成本和高性能正在改变不少公司针对「自研大模型」的战略。
1月29日,过去一年估值从5.2亿美元飙升至90亿美元的明星AI创业公司Perplexity选择接入DeepSeek-R1模型作为可选模型之一,这家以AI搜索作为招牌的公司在此之前仅接入过OpenAI、Anthropic两家公司的第三方模型。
在国内,同为AI搜索公司的秘塔科技也在2月2日宣布接入「满血版」DeepSeek-R1推理模型。在此之前,这家公司一直使用着自研模型来提供服务。
同样改变战略的还有网易有道。2023年,网易曾经推出自研教育大模型「子曰」,前不久还发布了推理模型「子曰-o1」,「教学过程中最大的场景、最难的问题都依赖理科大模型的能力」,有道CEO周枫当时曾这么说。但2月6日,网易有道就改变了方向,宣布旗下AI教育应用将全面接入DeepSeek-R1,声称在推理模型的帮助下,全科学习助手「有道小P」将提供「更具深度、更强准确性的解题思路」。Hi Echo、有道智云、QAnything等口语私教、翻译、知识库产品也将陆续升级。
Perplexity、秘塔科技和网易有道的选择意味着,这些公司将自己定义为要在产品层取胜的公司,将不再在模型层恋战。「如果你的目标是建立以产品为核心的公司,就不要在训练自有模型上浪费时间。」
Perplexity创始人Aravind Srinivas一年前所确立的创业逻辑曾遭受「套壳」产品的质疑
,如今却开始成为共识——正是由于DeepSeek的火爆。
对于网易有道这样的中小型公司来说,DeepSeek这种开源模型问世自然是个好消息,但对于字节跳动、百度等宣称要「all in AI」的技术巨头来说,这个选择就没那么容易作了。
DeepSeek发布后,华为、百度、字节等公司旗下的不少AI应用都宣布了接入DeepSeek。其中华为AI助手小艺于2月5日宣布接入DeepSeek-R1;2月8日,百度智能云宣布旗下的客悦、曦灵、甄知、一见等4款AI应用完成了对DeepSeek模型的适配,例如曦灵数字人平台开始采用R1推理模型来创作视频脚本,百度文小言也在同一天的App更新说明中特别提到「接入DeepSeek-R1模型优化了拍照解题功能」;就连在2024年的大模型大战中通过「大力出奇迹」暂时压倒众多大模型选手的字节跳动,也于2月7日宣布,其办公产品飞书的多维表格功能已接入DeepSeek-R1模型,用户可以在AI字段捷径中直接调用。
从产品角度说,选择性能更强、成本更低的模型(哪怕它是第三方模型)是个理性做法,毕竟用户满意度至上。但从公司角度看,放弃投资数十亿元的自研模型,这样的决策就没那么好向董事会与股东交代了。这个选择对于刚刚试图在大模型领域大手笔投入的小米和理想同样困难。










