
图:pixabay
原文来源:arxiv(Google Research、Carnegie Mellon University)
作者:Chen Sun、Abhinav Shrivastava、Saurabh Singh、Abhinav Gupta
「机器人圈」编译:BaymaxZ、嗯~阿童木呀

深度学习在视觉问题上所取得的成功可归因于(a)高容量模型、(b)高速增长的计算力、(c)大规模标记数据的可用性。自2012年以来,模型的性能和GPU的计算力都已取得非常大的进步。但最大数据集的大小却出乎意料地保持现状。那如果我们将数据集的大小扩大10倍或是100倍会发生什么呢?本文在揭秘“超大规模数据”和深度学习之间那云里雾里的关系上取得了一大步进展。我们利用JFT—300 M数据集,图片超过3亿张中已逾有3.75亿个具有噪声的标签。我们在研究,如果这个数据用于表征学习,那么当前的视觉任务的性能将发生怎样的变化。
我们的论文提供了一些预期之外的(和一些预期之内的)发现。
首先,我们发现,视觉任务的性能仍然以训练数据大小的数量级线性增加。
第二,我们表明,表征学习(或预训练)仍然有很大的用途。通过训练更好的基础模型,便可以提高视觉任务的性能。
最后,正如预期的那样,我们在包括图像分类、目标检测、语义分割和人体姿态评估等不同视觉任务上呈现出了新的基于目前技术水平的研究成果。
我们真诚希望可以以此来激发那些机器视觉的相关社区,不要低估数据的重要性,以及要发展集体努力从而建设更大的数据集。
众所周知,目前的卷积神经网络革命是大型标注数据集的产物(具体来说,来自ImageNet的大小为1M的标记图像)和大规模计算能力(得益于GPU)。每年我们都在进一步增加计算能力(更新、更快的GPU),但是我们的数据集并没有那么幸运。ImageNet是一个基于1000个类别的1M标记图像的数据集,五年多以前用于训练AlexNet。
奇怪的是,虽然GPU和模型容量都在不断增长,但是对这些模型进行训练的数据库仍然停滞不前。即使是具有明显更多容量和深度的101层的ResNet,仍然使用来自ImageNet大约2011年的1M Image图像进行训练。为什么?在更深层次的模型和计算能力之前,我们再次贬低了数据的重要性吗?如果我们将训练数据的量增加10倍或100倍,性能会翻番么?
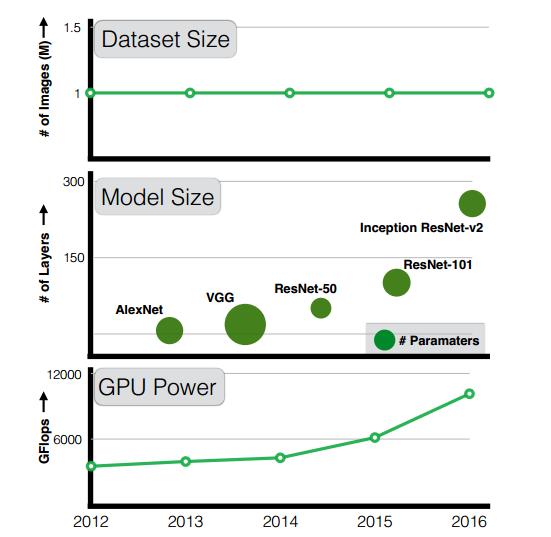
视觉数据集的奇怪案例:尽管GPU计算能力和模型尺寸在过去五年中不断增加,但是训练数据集的大小却惊人地保持不变。这是为什么?如果我们使用我们的资源来增加数据集大小,会发生什么?
本论文采取的第一步,是清除围绕“超大规模数据”与深度学习之间的神秘关系。当然,重要的是,如何收集比ImageNet还大的数据集。为了测试当前模型的极限和上限,我们可能需要一个几乎比ImageNet大100倍的数据集。事实表明,收集1M图像的1000个类别,每个问题将需要1000万美元。ImageNet使用了几种启发式(例如标签层级)来减少问题,从而将成本降低到10万美元。但是,大于100倍的数据集仍然需要超过1000万美元。
在本论文中,我们利用了一个已经存在的JFT图像数据集,该数据集由Geoffrey Hinton等科学家最早提出。JFT数据集拥有超过3亿张图像,标有18291个类别。注释是自动获得的,因此,这些注释比较嘈杂,并不是详尽无遗的。这些注释已经使用复杂的算法进行清理,以提高标签的精度;然而,精度仍然有大约20%的误差。我们将使用这些数据来研究数据量与视觉性能之间的关系。具体来说,我们将研究视觉表征学习(预训练)的数据的能力。我们评估各种视觉任务的学习性能:图像分类、对象检测、语义分割和人体姿态评估。我们的实验产生了一些令人惊讶(和一些预期)的发现:
•更好的表征学习真的有用!
我们的第一个观察是,大规模数据有助于表征学习,这是被我们研究的每个视觉任务的性能改善所证明的。
这表明,收集更大规模的数据集以研究预训练过程,可能会对该领域产生极大的好处。我们的研究结果还表明,无监督或自监督表征学习方法的光明前景。数据量表似乎可以超越标签空间的噪音。
•性能随着训练数据的数量级数线性增加!
也许我们发现的最令人惊奇的要素是,视觉任务的性能与用于表示学习的训练数据(对数量表)的数量之间的关系。我们发现这种关系还是线性的!即使是3亿张训练图像,我们对所研究的任务也没有观察到任何平台效应。
•容量至关重要
我们还观察到,为了充分利用3亿张图像,需要更高容量的模型。例如,在ResNet-50的情况下,COCO对象检测的增益(1.87%),比使用ResNet-152(3%)时,要小得多。
•长尾训练:
我们的数据有相当长的尾巴,表征学习似乎有效。这种长尾似乎不会对卷积神经网络的随机训练产生不利影响(训练仍然趋于收敛)。
•最新技术成果
最后,我们的论文使用从JFT-300M获得模型,在几个基准上提出了新成果。例如,一个单一的模型(没有任何bell和whistle)AP(目标检测中衡量检测精度的指标)达到 37.4,而COCO检测基准的AP为34.3。
想要更多了解此论文,欢迎下载https://arxiv.org/abs/1707.02968
 欢迎加入
欢迎加入

中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册






