
数据挖掘入门与实战 公众号: datadw
朴素贝叶斯常见的应用场景之一是情感分析。又上Kaggle溜达了一圈,扒下来一个类似场景的比赛。比赛的名字叫做当词袋/Bag of words 遇上 爆米花/Bags of Popcorn,地址为https://www.kaggle.com/c/word2vec-nlp-tutorial/,有兴趣的同学可以上去瞄一眼。
8.1 背景介绍
这个比赛的背景大概是:国外有一个类似豆瓣电影一样的IMDB,http://www.imdb.com/ 也是你看完电影,可以上去打个分,吐个槽的地方。然后大家就在想,有这么多数据,总得折腾点什么吧,于是乎,第一个想到的就是,赞的喷的内容都有了,咱们就来分分类,看看能不能根据内容分布褒贬。PS:很多同学表示,分个褒贬有毛线难的,咳咳,计算机比较笨,另外,语言这种东西,真心是博大精深的,我们随手从豆瓣上抓了几条《功夫熊猫3》影评下来,表示有些虽然我是能看懂,但是不处理直接给计算机看,它应该是一副『什么鬼』的表情。。。
多说一句,Kaggle原文引导里是用word2vec的方式将词转为词向量,后再用deep learning的方式做的。深度学习好归好,但是毕竟耗时耗力耗资源,我们用最最naive的朴素贝叶斯撸一把,说不定效果也能不错,不试试谁知道呢。另外,朴素贝叶斯建模真心速度快,很多场景下,快速建模快速迭代优化正是我们需要的嘛。
8.2 数据一瞥
言归正传,回到Kaggle中这个问题上来,先瞄一眼数据。Kaggle数据页面地址为https://www.kaggle.com/c/word2vec-nlp-tutorial/data,大家也可以到博主的百度网盘中下载 http://pan.baidu.com/s/1c1jX8nI 数据包如下图所示:
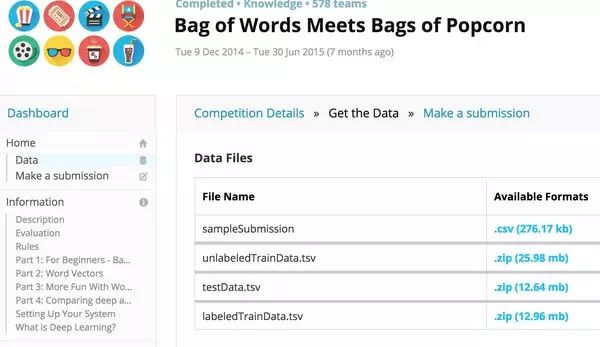
其中包含有情绪标签的训练数据labeledTrainData,没有情绪标签的训练数据unlabeledTrainData,以及测试数据testData。labeledTrainData包括id,sentiment和**review**3个部分,分别指代用户id,情感标签,评论内容。
解压缩labeledTrainData后用vim打开,内容如下:

下面我们读取数据并做一些基本的预处理(比如说把评论部分的html标签去掉等等):
import re #正则表达式
from bs4 import BeautifulSoup #html标签处理
import pandas as pd
def review_to_wordlist(review):
'''
把IMDB的评论转成词序列
'''
# 去掉HTML标签,拿到内容
review_text = BeautifulSoup(review).get_text()
# 用正则表达式取出符合规范的部分
review_text = re.sub("[^a-zA-Z]"," ", review_text)
# 小写化所有的词,并转成词list
words = review_text.lower().split()
# 返回words
return words
# 使用pandas读入训练和测试csv文件
train = pd.read_csv('/Users/Hanxiaoyang/IMDB_sentiment_analysis_data/labeledTrainData.tsv', header=0, delimiter="\t", quoting=3)
test = pd.read_csv('/Users/Hanxiaoyang/IMDB_sentiment_analysis_data/testData.tsv', header=0, delimiter="\t", quoting=3 )
# 取出情感标签,positive/褒 或者 negative/贬
y_train = train['sentiment']
# 将训练和测试数据都转成词list
train_data = []
for i in xrange(0,len(train['review'])):
train_data.append(" ".join(review_to_wordlist(train['review'][i])))
test_data = []
for i in xrange(0,len(test['review'])):
test_data.append(" ".join(review_to_wordlist(test['review'][i])))
我们在ipython notebook里面看一眼,发现数据已经格式化了,如下:

8.3 特征处理
紧接着又到了头疼的部分了,数据有了,我们得想办法从数据里面拿到有区分度的特征。比如说Kaggle该问题的引导页提供的word2vec就是一种文本到数值域的特征抽取方式,比如说我们在第6小节提到的用互信息提取关键字也是提取特征的一种。比如说在这里,我们打算用在文本检索系统中非常有效的一种特征:TF-IDF(term
frequency-interdocument
frequency)向量。每一个电影评论最后转化成一个TF-IDF向量。对了,对于TF-IDF不熟悉的同学们,我们稍加解释一下,TF-IDF是一种统计方法,用以评估一字词(或者n-gram)对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。这是一个能很有效地判定对评论褒贬影响大的词或短语的方法。
那个…博主打算继续偷懒,把scikit-learn中TFIDF向量化方法直接拿来用,想详细了解的同学可以戳sklearn TFIDF向量类
http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
对了,再多说几句我的处理细节,停用词被我掐掉了,同时我在单词的级别上又拓展到2元语言模型(对这个不了解的同学别着急,后续的博客介绍马上就来),恩,你可以再加3元4元语言模型…博主主要是单机内存不够了,先就2元上,凑活用吧…
from sklearn.feature_extraction.text import TfidfVectorizer as TFIV
# 初始化TFIV对象,去停用词,加2元语言模型
tfv = TFIV(min_df=3, max_features=None, strip_accents='unicode', analyzer='word',token_pattern=r'\w{1,}', ngram_range=(1, 2), use_idf=1,smooth_idf=1,sublinear_tf=1, stop_words = 'english')
# 合并训练和测试集以便进行TFIDF向量化操作
X_all = train_data + test_data
len_train = len(train_data)
# 这一步有点慢,去喝杯茶刷会儿微博知乎歇会儿...
tfv.fit(X_all)
X_all = tfv.transform(X_all)
# 恢复成训练集和测试集部分
X = X_all[:len_train]
X_test = X_all[len_train:]
8.4 朴素贝叶斯 vs 逻辑回归
特征现在我们拿到手了,该建模了,好吧,博主折腾劲又上来了,那个…咳咳…我们还是朴素贝叶斯和逻辑回归都建个分类器吧,然后也可以比较比较,恩。
『talk is cheap, I’ll show you the code』,直接放码过来了哈。
# 多项式朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB as MNB
model_NB = MNB()
model_NB.fit(X, y_train) #特征数据直接灌进来
MNB(alpha=1.0, class_prior=None, fit_prior=True)
from sklearn.cross_validation import cross_val_score
import numpy as np
print "多项式贝叶斯分类器20折交叉验证得分: ", np.mean(cross_val_score(model_NB, X, y_train, cv=20, scoring='roc_auc'))
# 多项式贝叶斯分类器20折交叉验证得分: 0.950837239
# 折腾一下逻辑回归,恩
from sklearn.linear_model import LogisticRegression as LR
from sklearn.grid_search import GridSearchCV
# 设定grid search的参数
grid_values = {'C':[30]}
# 设定打分为roc_auc
model_LR = GridSearchCV(LR(penalty = 'L2', dual = True, random_state = 0), grid_values, scoring = 'roc_auc', cv = 20)
# 数据灌进来
model_LR.fit(X,y_train)
# 20折交叉验证,开始漫长的等待...
GridSearchCV(cv=20, estimator=LogisticRegression(C=1.0, class_weight=None, dual=True,
fit_intercept=True, intercept_scaling=1, penalty='L2', random_state=0, tol=0.0001),
fit_params={}, iid=True, loss_func=None, n_jobs=1,
param_grid={'C': [30]}, pre_dispatch='2*n_jobs', refit=True,
score_func=None, scoring='roc_auc', verbose=0)
#输出结果
print model_LR.grid_scores_
最后逻辑回归的结果是[mean: 0.96459, std: 0.00489, params: {'C': 30}]
咳咳…看似逻辑回归在这个问题中,TF-IDF特征下表现要稍强一些…不过同学们自己跑一下就知道,这2个模型的训练时长真心不在一个数量级,逻辑回归在数据量大的情况下,要等到睡着…另外,要提到的一点是,因为我这里只用了2元语言模型(2-gram),加到3-gram和4-gram,最后两者的结果还会提高,而且朴素贝叶斯说不定会提升更快一点,内存够的同学们自己动手试试吧。
作者: 寒小阳 && 龙心尘
出处:http://blog.csdn.net/han_xiaoyang/article/details/506296
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注










