圣路易斯的美联储,有一个网站:
http://research.stlouisfed.org/fred2/
集合了50多万条美国和国际的时间序列数据。丰富的数据源为我们的研究提供了极大的便利。当然这里顺便推荐一本书《还原真实的美联储》。
新版的Stata 15开始支持使用freduse,事实上这个命令很早之前就可以在ssc上下载了(ssc install freduse)。
如果我们想找到美国每个州的GDP,应该怎么在Stata里操作呢?
每一个变量在这个网站上都有一个编码,比如 Illinois的GDP的编码是ILNGSP,不难发现IL是 Illinois的缩写,NGSP是对GDP的简称。
刚好手边有美国每个州的全称和简称,大概长这样:
我们现在首先要做的事情是批量生成每个州的GDP编码,然后复制到我们后面的代码里。
import excel using C:\Users\Administrator\Desktop\state.xls,clear
drop in 1
gen code=A+"NGSP"
keep code
sxpose,clear
然后使用freduse批量下载。
clear
freduse ALNGSP AKNGSP AZNGSP ARNGSP (限于篇幅,未全部罗列每个州的GDP编码)
下载完成后,我们把数据处理成panel data的格式。
local i=1
foreach v of varlist *NGSP{
preserve
keep date daten `v'
rename `v' GDP
gen state=substr("`v'",1,2)
save data`i',replace
restore
local i=`i'+1
}
use data1,clear
forvalue i=2(1)51{
append using data`i'
}
gen year=year(daten)
keep year state GDP
save gdp,replace
大功告成,得到的数据集是这样的:
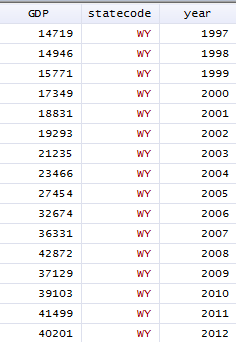
当然如果您想下载中国的宏观数据,方法也是类似的。找到编码的规律,然后批量处理。

后台不断有读者索要公众号推文Stata程序,考虑到人力有限,很难面面俱到。不妨请我们
喝杯咖啡
,我们也把先前的程序批量整理,统一发送。
先前包含Stata程序的文章有:
1、
比特币,人民币汇率和套利 | Stata应用
2、
基于财务指标的银行股轮动回测 | Stata应用
3、
Stata应用 | 如何进行量化策略回测?
4、
Stata应用 | 新浪和微博被均衡定价了吗?
5、
哪些学术大牛发了《经济研究》?来自2009年到2017年的数据分析
6、
哪些学术大牛发了AER?来自1999年到2017年的数据分析
7、
该这样面对这个残酷的世界?
原文链接为我们的
微店
,所有Stata程序均已打包,售价为50元。如果您有意索要程序(codes为付款日以前所有的Stata程序),请在微店内付款,并留下您的邮箱地址。我们会在付款后的
24小时内
将程序发到您的邮箱,发送时间集中于次日晚上9:00—11:00,请注意查收,谢谢。
注:您所购买的资料,是截止您付款时Idata所有的程序和数据,在后续更新中,若有您需要的资料,请重新购买,谢谢!
如果你觉得文章不错,请点右上角选择发送给朋友或转发到朋友圈。您的支持和鼓励是我们最大的动力。喜欢请关注我们吧!







