在近日举行的腾讯研究院年会上,腾讯副总裁、AI Lab院长姚星发表了《AI 真实的希望与喧哗的隐忧》主题演讲,介绍了腾讯人工智能部门的发展历程,同时也对机器学习和人工智能的未来谈了自己的看法。机器之心参与了本次会议,并对演讲内容进行了整理。

姚星首先回顾腾讯与中国互联网二十年的发展历程,从最初的窄带时代到现在的移动互联网时代,在每一个重要节点腾讯都有一款重量级产品出现。在最近进入到 AI 爆发的阶段,腾讯也顺势成立了自己的 AI Lab。演讲中正式向外公布腾讯 AI Lab 所关注 AI 四个基础研究领域和 4 个专属研究方向。也谈及在趋之若鹜的 AI 浪潮中,大家对人工智能的希望来自于深度学习的算法、模型和数学理论的突破,但同时深度学习自身的能力局限、计算能力的限制以及数学理论的不可解释性为过高的期望降温。
以下为演讲内容整理:
各位朋友大家下午好。今天我演讲的题目——AI:真实的希望与喧哗的隐忧。希望表明了大家对 AI 的期待,而隐忧则说明大家期望过高。
腾讯与中国互联网二十年的发展
回顾中国互联网过去二十年的发展,这二十年是信息高速发展的二十年,大致经历了三个发展阶段:上个世纪九十年代、21 世纪初期以及2010 年后。
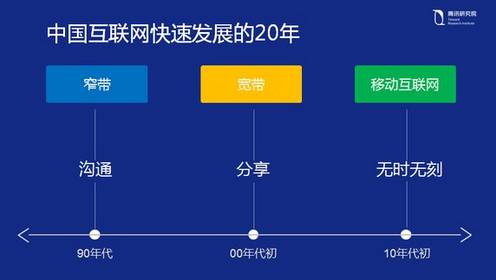
在上世纪九十年代初期,中国第一次连上互联网——「跨越长城,连接世界」。随着第一封 e-mail 的发出,中国正式进入到互联网大家庭中来。但是由于当时网络速度的问题,大部分互联网应用只限于沟通。沟通解决了当时的很多问题,人们不再需要面对面才能进行交流,或者通过传统书信的方式进行沟通。不论天涯海角,只要能连上互联网,人们总是可以接触到信息。
随着整个网络设备和传输能力的发展,特别是 2000 年以来,网吧的大量涌现、网络连接速度的大幅提升、网络带宽速度的快速提升,人们对互联网的诉求不再仅仅是消息的传递和沟通,更多的是分享。当时兴起了很多基于分享的应用,博客、MSN、 Facebook、QQ 空间等都是基于分享的。人人为我,我为人人——有很多内容或者信息都是通过互联网来分享的,比如跟朋友分享生活的喜悦和苦恼。
随后移动时代的发展,特别是以智能手机为代表的智能终端的发展,也即自 2010 年以来,移动互联网高速发展所带来明显的变革——人们不再受限于特定时间和特定空间的互联网连接。以前大家都是在网吧或者工作的地方才能获取互联网信息,现在大家随时随地通过智能手机就可以与互联网连接。可以看出,中国互联网过往二十年的发展是随着设备的发展、产业的发展、信息产业的发展而演进的。
伴随着互联网过往二十年的发展,腾讯在过去二十年里做了些什么?实际上在每一个阶段,腾讯都有一款重量级的产品出现。
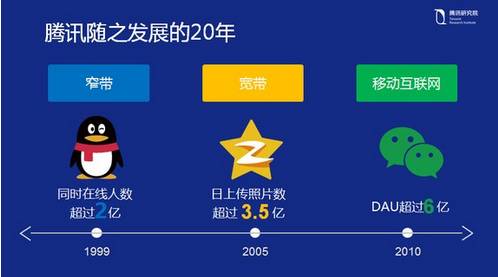
在上世纪九十年代,也即中国互联网的早期发展阶段——窄带时代,就如刚才所说,当时的互联网主要是用于沟通,在那个阶段腾讯推出了 QQ。QQ 是目前世界上同时在线人数最多的应用,已经达到两亿人同时在线的体量。而到了宽带时代,在 2000 年初的时候,QQ 空间诞生。QQ 空间目前日上传照片数超过五亿张,这个规模跟世界上最大的社交网络 Facebook 相比,几乎是同一个量级,在总照片数量上跟 Facebook 也几乎是同一个量级(2013 年 Facebook 公开数据显示其日上传照片数大概是在 2.5 亿张左右,总照片数大概 6000 亿张)。
然后来到移动互联网时代,为大家所熟知的一个产品就是微信。这款产品不仅是一个简单的应用,WeChat 是一个超级 APP。微信不仅解决了沟通问题,还解决了社交、分享的问题,还支持线下支付、线下打车,甚至医院挂号看病、交水电费等一系列功能都可以在这一个软件上实现。实际上,腾讯的这三款产品在整个世界范围内都是领先的。
从整个发展史来看,我们可以看出过往的发展史经历窄带时代、宽带时代,然后到现在的移动互联网时代,它犹如生物进化一般,从原始的单细胞生物到多细胞生物到最后有智能的生物。那么今年来讲「智能」,智能会更加的广义,不仅仅是智能终端,大家讨论更多的智能是 AI。
腾讯的 AI 布局
2016 年正好是 AI 发展六十周年,从去年开始 AI 迅速爆发,可以说是家喻户晓。这也是为什么我刚刚在跟很多嘉宾聊的时候说,大家觉得腾讯在 AI 上很低调,没有什么大动作。甚至有很多人问我腾讯到底有没有在做 AI?怎么从来没有向外界宣布任何 AI 相关的布局规划呢?实际上腾讯有自己的 AI 部门,从 2016 年 4 月份开始,腾讯成立了自己的 AI Lab,目前已经有 30 多位的 Research Scientists,绝大多数拥有博士学历及以上且都有海外研究经历。他们中业界的来自于微软、IBM、Facebook 等公司,学术界是从世界最顶级学府引进的人才,包括斯坦福、加州伯克利、康奈尔、麻省理工、哥伦比亚大学等顶级高校。

目前在腾讯,我们已经组织了一个 30 人左右的 AI Lab,而且规模还在扩张。腾讯的 AI 可能不像其它公司的 AI 为人所了解,比如说谷歌的 AI,很多人都知道 DeepMind 在做围棋,他们用强化学习来实现,而且他们用强化学习来完成很多任务。以及他们提出了很多的神经网络结构(neural network),比如 WaveNet,deepNet,LipNet 等;而百度为大家所熟知的有无人车、度秘等一些产品。但腾讯的 AI 一直没有对外宣传,今天我也跟大家分享腾讯在 AI 上面的一些考虑。
实际上腾讯的 AI 主要基于四个垂直领域,计算机视觉(Computer Vision)、语音识别(Speech Recognition)、自然语言处理(NLP)和机器学习(Machine Learning),每一个领域都是代表了 AI 的一个基础的研究方向,但是每个领域都可以更多深层次的研究拓展。比如在计算机视觉领域,除了传统的图像处理还会有增强现实(AR)的研究拓展,也会引入空间定位(Simultaneous Localization and Mapping)技术;比如在语音识别领域,我们除了传统的语音识别、语音合成以外,还会引入更多的跟语音相关的拓展研究比如说自动翻译(Translation)。另外在 NLP 里,除了传统的自然语言处理的对人的认知行为的一些研究,我们还会做聊天机器人的一些研究。在 ML 里,从监督类的机器学习到无监督的机器学习,然后到增强学习的机器学习,都会展开相关的研究。这四个领域基本上涵盖了当今整个 AI 基础研究领域的方方面面,也是腾讯 AI Lab 将会关注的四个基础研究领域。

然后我们还提出了四个专属的研究方向,这是结合整个腾讯公司的业务来进行的。
我们提出了内容 AI(Content AI),我们把基于内容类的推荐和搜索类的应用都归属在内容 AI 里。
另外还有我们的社交 AI
(Social AI)
,腾讯是一个社交应用上很强势的公司,包括刚刚说的 QQ 空间、微信都是社交平台,所以在社交 AI 上面我们会基于社交考虑来研究相关的 AI 技术,比如社交中的对话、聊天机器人、智能助手等,都会纳入这个研究方向中来。
另外一个方向,我认为是和全世界其他所有的公司都不太一样的一个 AI 方向,即我们的游戏 AI(Game AI)。大家可能会问我,DeepMind 也有做围棋的 AI,但是它只是一个围棋游戏,它不会涉及到太多的游戏。而对于腾讯来讲,在整个腾讯集团里面,游戏是腾讯一块很大的业务。我们会在游戏里面引入更多 AI 能力,实际上这个 AI 游戏的想像空间是非常大的。大家试想一下,会不会有一天 LOL 里 AI 也来参加世界电竞赛,与人类交战。大家知道现在腾讯有一款很受欢迎的手游叫做「王者荣耀」,如果把这里面的能力提升,是不是可玩性、乐趣性就会更多,腾讯对这一块也是很关注的。
除此之外我们还会提供很多工具类的 AI,会结合到腾讯的云服务,我们需要研发相关技术从而加强相关能力来实现这些工具的开放。这些工具将包括基于图像的人脸识别的能力、语音识别的能力、在自然语言处理里的舆情处理能力等,还包括我们在深度学习上的开放深度学习平台的能力。
所以说从目前来讲,整个腾讯 AI 研究的基础领域是四个,我们的专属研究方向也是四个。
深度学习喧嚣之下的隐忧
AI 不是一个新的概念,它的发展经历了六十多年,在这六十年里,人工智能的发展之路并不平坦。在去年人工智能又突然爆发了,势头一直延续到了现在。1956 年的达特茅斯会议,AI 这个名词被首次提出。人工智能比较有名的事件是九十年代 IBM 深蓝打败了卡斯帕罗夫,也就是那个时代的 AlphaGo 和李世乭。人们记忆中最清晰的一件事还是去年 AlphaGo 围棋打败围棋世界冠军李世乭,这表明在围棋这个最古老、最复杂的游戏上面,AlphaGo 的智能已经超越了人类。
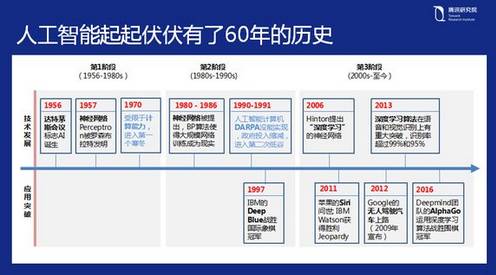
当然整个发展史里面也有很多技术方面的演进,比较有代表性的就是 2006 年,Geoffery Hinton 在深度学习上有了巨大的突破,带领 AI 的所有发展方向极速提升。我认为这次人们期待 AI 最主要的原因是这一次 AI 的底层算法在深度学习上面有了实质性的突破。
这次 AI 的发展是从 2012 年开始的,先在业界落地。可以看到整个深度学习的方法和传统方法完全不一样,不像以前的研究方法,是通过模仿来实现的。这一情形和早期人类想粘上羽毛学习飞翔比较类似,我们都知道真正的飞翔是通过空气动力学去完成的,这也是深度学习的一个思想之一。
之所以现在能有很多应用上的突破,是因为研究员们掌握了内在的学习方法,而不是表面的模仿。所以从这一点来说,我们现在在深度学习的研究方法上是正确的。
第二个是模型上的提升,刚才我说了,AI 的发展有六十年,机器学习以及深度学习并不是最近才突然出现的。神经网络早在六十年代就有过——当时提出来感知机(perceptron)。机器学习在八九十年代也非常火,当时有一个叫 SVM(支持向量机)的分类器,已经是非常厉害的一种机器学习的算法。那么现在为什么又重新提出来?深度学习同原来的机器学习相比,在模型能力上有非常大的提升。大家都知道我们所有的机器学习的方法,都是从 A 到 B 去寻找一个拟合函数,实现一个最佳的拟合过程。在这个过程中如果选取的特征越多,拟合的效果就会越好。但同时有一个问题,当特征太多的时候,计算能力就会出现问题。在浅层模型中,如果要模拟出一个从 A 到 B 的完美拟合过程,它的数据能达到几亿甚至几十亿的规模,当他达到这种规模的时候它的计算能力就会急剧下降,会通过一个非常复杂的复合函数去描述数据。但是深度学习的方式能够很好的解决这个问题,它通过深度学习神经网络的多层连接,其特征表达是一个指数层倍的关系,如果说用一个全连接(fully connected)描述十亿的特征,可能我们只需要三层一千个节点的连接,就能构建十亿个特征的权重出来。所以从本质来讲,模型上的提升也是深度学习的一个突破。




