来源:Github
整理&作者:文强
【新智元导读】距离上次新智元整理报道“最受欢迎的 Github 深度学习项目”已经过去大半年。在这期间,又涌现出不少值得关注的新项目,而以前榜单上的项目也有不小的变化。本次统计将常用深度学习开源框架也纳入统计,以供参考,比如 TensorFlow 就从去年 8 月 29622 颗星变为 56796 颗星,实力惊人。下面,就来看看截止到 2017年 5月14日,Github 最受欢迎的深度学习项目 TOP 20 是哪些吧(统计难免不完善,欢迎评论补充)。我们的这份榜单也会持续更新。

Star:56,796
Github 地址:https://github.com/tensorflow/tensorflow
TensorFlow是一个开源软件库,使用数据流图(data flow graph)进行数值计算。图中的节点表示数学运算,而图形边缘表示在它们之间流动的多维数据阵列(张量)。 这种灵活的架构让人能将计算部署到桌面、服务器或移动设备中的一个或多个CPU或GPU,而无需重写代码。TensorFlow 还有一个数据可视化工具包 TensorBoard。
TensorFlow 由 Google Brain 团队研究人员和工程师开发,用于进行机器学习和深层神经网络研究。不久前发布了 TensorFlow 1.0 版本。
Star:18,516
Github 地址:https://github.com/scikit-learn/scikit-learn
scikit-learning是一个用于机器学习的 Python 模块,建立在 SciPy 之上,并按照 3-Clause BSD 许可证分发。该项目于 2007 年由 David Cournapeau 开始,作为“Google夏季代码”项目,此后,许多志愿者做出了贡献。目前由志愿者团队维护。
志愿者的力量是强大的。

Star:17,795
Github 地址:https://github.com/BVLC/caffe
Caffe 是一个深刻的学习框架,设计时注重表达(expression)、速度和模块化。根据 Github 介绍,Caffe 由伯克利 AI(BAIR)/伯克利视觉与学习中心(BVLC)及社区贡献者开发。Caffe 有一个非常活跃的开发者社区。
去年 11 月,Caffe 主要作者、Facebook 研究科学家贾扬清在 Facebook 官往发文,介绍了 Caffe2go,一款规模更小、训练速度更快、对计算性能要求较低的机器学习框架,在手机上也能运行神经网络模型。但令人震惊,Caffe2go 截止发稿前 Github 星级为 0。
今年 4月,Facebook 宣布开源跨平台的深度学习框架 Caffe2,轻量级、模块化,在移动端和云上都做了优化。同时提供的还有 C++ 和 Python API,以及模型库 Caffe2 Model Zoo,里面有视觉、语音、翻译等预训练模型,方便开发人员和研究者直接使用。Caffe2 目前在 Github 星级为 4602。
Caffe2 Github 地址:https://github.com/caffe2/caffe2
Star:15,515
GitHub 地址:https://github.com/fchollet/keras
Keras是一个高级神经网络 API,用 Python 编写,能够运行在 TensorFlow 或者 Theano 上。Keras 的开发重点是实现快速实验,能够用尽可能少的延迟从理念到结果,是进行良好研究的关键,也是 Keras 受欢迎的一大原因。
Star:14,620(去年 8 月 10,563)
GitHub 地址:https://github.com/tensorflow/models/tree/master/im2txt
这是 Oriol Vinyals et. al.(2016)的论文“Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge”的用TensorFlow实现的 image-to-text 图片说明生成模型。
Show and Tell 模型是一个学习如何描述图片的深度神经网络。生成的图片说明是一个完整的句子,下面是一些例子:

Star:13,673(去年 8 月为 10,148)
Github 地址:https://github.com/jcjohnson/neural-style
这个项目是用 Torch 对 Leon A. Gatys, Alexander S. Ecker, 和 Matthias Bethge 等人的论文“A Neural Algorithm of Artistic Style”的一个实现。论文中提出一种算法,用卷积神经网络将一幅图像的内容与另一幅图像的风格进行组合。下面是一个将梵高《星夜》的艺术风格转移到斯坦福大学校园夜景的照片中的效果:

将不同的艺术风格应用到同样一幅图像中会得出有趣的效果。论文中提供了各种风格的德国宾根大学图像:

Star:10,673
Github 地址:https://github.com/Microsoft/CNTK
CNTK 是微软的开源深度学习框架,支持大部分流行的神经网络。2015 年 2 月,官方报道了一个基准性能测试结果,针对一个 4 层全连接神经网络,CNTK 与 Caffe、TensorFlow、Theano 和 Torch 对比,速度要快上 1.5 倍。
去年 10 月,微软提供了 CNTK 升级版。本次升级最大的亮点在于增加了 Python 绑定。另外,新版本工具包跨服务器处理能力也得到了提升,能有效加快处理速度,并支持增强学习的实践。
Star:10,370
Github 地址:https://github.com/tesseract-ocr/tesseract
Tesseract 支持 unicode(UTF-8),可以直接识别超过 100 种语言,也可以在训练后识别其他语言。
Tesseract 支持各种输出格式:plain-text、hocr(html)和 pdf。
Tesseract 最初是惠普实验室开发的,2005 年开源。2006 年以后由谷歌开发。
Star:10,156(去年 8 月 9042)
Github 地址:https://github.com/tesseract-ocr/tesseract
需要说明,这不是谷歌官方 Deep Dream 的 Github 库。这个库里包含了有示例代码的 IPython Notebook,补充了 Google Research 官方博客关于 Neural Network Art 的博文。
很多开发人员使用这个库里描述的技术制作了脑洞大开的图像。我们也期待你的尝试。对了,如果你将图像发布到 Google+,Facebook 或 Twitter,请务必使用 #deepdream 做上标记,方便其他研究人员查看。
Star:9615
Github 地址:https://github.com/dmlc/mxnet
MXNet 是一个旨在提高效率和灵活性的深度学习框架。因得到亚马逊的大力而成为常用深度学习框架的黑马。MXNet 可以混合符号和命令式编程,从而最大限度地提高效率和生产力。在其核心,MXNet 包含一个动态依赖调度程序(dynamic dependency scheduler),可以自动将符号运算和命令运算并行。顶部的图形优化层使 MXNet 符号执行速度快,记忆效率高。此外,MXNet 是便携式和轻量级的,可有效扩展到多颗 GPU 和多台机器。
Star:8065(去年 8 月 7734)
Github 地址:https://github.com/Rochester-NRT/RocAlphaGo
这个项目是有学生主导的一个独立项目,使用 Python 和 Keras 重新实现了 DeepMind 在2016年发表的论文 "Mastering the game of Go with deep neural networks and tree search"(《用深度神经网络和树搜索学习围棋》)。使用 Python 和 Keras 的这个选择优先考虑了代码清晰度,至少在早期阶段是如此。
这个项目目前仍在进行中,还不是 AlphaGo 的完全实现。项目先期关注 DeepMind AlphaGo 中神经网络的训练方面,而且已经得到论文中树搜索算法的一个简单单线程的实现,虽然速度上无法与 DeepMind 相比。
Star:7763(去年 8 月 7306)
Github 地址:https://github.com/alexjc/neural-doodle
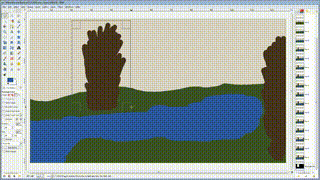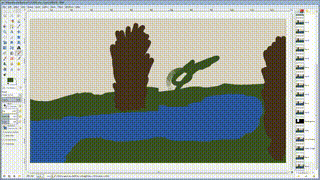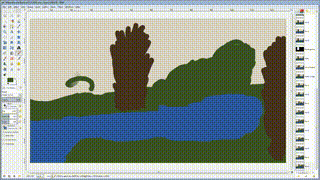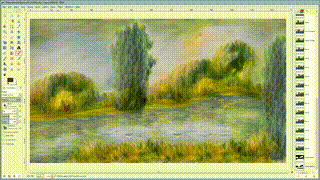
使用深度神经网络把你的二流涂鸦变成艺术一般的作品!这个项目是 Champandard(2016)的论文 “Semantic Style Transfer and Turning Two-Bit Doodles into Fine Artworks”的一个实现,基于 Chuan Li 和 Michael Wand(2016)在论文“Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis”中提出的 Neural Patches 算法。这篇文章中深入解释了这个项目的动机和灵感来源:https://nucl.ai/blog/neural-doodles/
doodle.py 脚本通过使用1个,2个,3个或4个图像作为输入来生成新的图像,输入的图像数量取决于你希望生成怎样的图像:原始风格及它的注释(annotation),以及带有注释(即你的涂鸦)的目标内容图像(可选)。该算法从带风格图像中提取 annotated patches,然后根据它们匹配的紧密程度用这些 annotated patches 渐进地改变目标图像的风格。
Star:7122(去年 8 月 6072)
Github 地址:https://github.com/cmusatyalab/openface
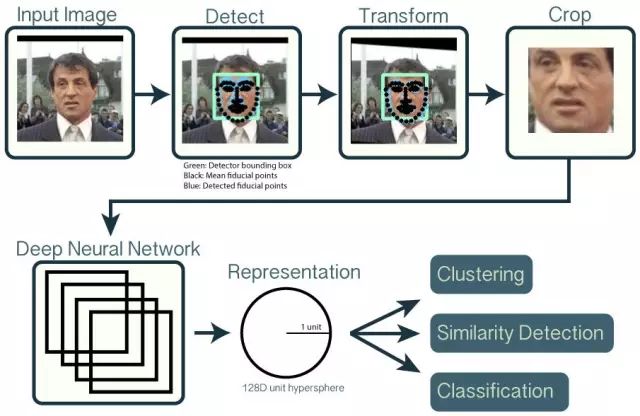
OpenFace 是一个使用深度神经网络,用 Python 和 Torch 实现人脸识别的项目。神经网络模型基于 Google Florian Schroff 等人的 CVPR 2015 论文“FaceNet: A Unified Embedding for Face Recognition and Clustering” ,Torch 让网络可以在 CPU 或 CUDA 上运行。
这是CMU的一个使用深度神经网络进行人脸识别的免费、开源项目。该项研究得到美国国家科学基金会(NSF)的支持,以及英特尔、谷歌、 Vodafone、英伟达和 Conklin Kistler 的额外支持。这个 Github 库中包含 batch-represent、real-time web、compare.py、vis-outputs.lua、classifier.py 等的 demo 和测试、训练、评估等的代码。
Star:6843
Github 地址:https://github.com/torch/torch7
PyTorch是一个提供两个高级功能的 python 包:① 具有强 GPU 加速度的张量计算(如numpy);②深度神经网络建立在基于磁带的自动调整系统(tape-based autograd system)Torch 也是常用深度学习框架之一,是 Torch7 中的 main package,其中定义了用于多维张量和数学运算的数据结构。此外,Torch 提供了很多实用功能,比如访问文件的实用程序,序列化任意类型的对象和其他有用的实用程序。
13. Neural Enhance:深度学习做图像高分辨率
Star:6557
Github 地址:https://github.com/alexjc/neural-enhance

见过刑侦剧里将模糊图片变清晰的情节吗?由于深度学习和 #NeuralEnhance,你也可以训练一个神经网络把图像放大 2 倍乃至 4 倍而且高清。增加神经元的数量或使用类似于低分辨率图像的数据集进行训练,还可以获得更好的结果。具体怎么做?去看 Github 介绍吧。
Star:4988
Github 地址:https://github.com/pytorch/pytorch
PyTorch是一个提供两个高级功能的 python 包:①具有强 GPU 加速度的张量计算(如numpy);②深度神经网络建立在基于磁带的自动调整系统(tape-based autograd system)。考虑到它的发布时间,PyTorch 大有潜力。
你可以重用你喜欢的 python 软件包(如 numpy,scipy 和 Cython),在有需要时对 PyTorch 进行扩展。
就在 5 月 4 日,PyTorch 发布了最新版,API 有一些变动,增加了一系列新的特征,多项运算或加载速度提升,而且修改了大量 bug。官方文档也提供了一些示例。

15. Sonnet:DeepMind 内部开源深度学习框架
Star:4691
Github 地址:https://github.com/deepmind/sonnet
DeepMind 研究人员发现 TensorFlow 的灵活性和适应性适合于为特定目的构建更高级别的框架,于是他们就写了一个这样的框架,可以用 TensorFlow 快速构建神经网络模块,也就是 Sonnet 框架。
开源 Sonnet,可以使 DeepMind 创建的其他模型轻松地与社区共享,DeepMind 表示他们希望开发者社区能够使用 Sonnet 进行自己的研究。Sonnet 被专门设计用于与 TensorFlow 协同工作,不会阻止访问底层细节,如 Tensors 和可变范围等。Sonnet 编写的模型可以与原始的 TensorFlow 代码以及其他高级库中的模型自由混合。
Sonnet 将定期更新。
Star:4288(去年 8 月 3951)
Github 地址:https://github.com/david-gpu/srez
srez(super-resolution through deep learning),即通过深度学习实现图像超分辨率。这个项目是利用深度学习将 16x16 的图像分辨率增加 4 倍,基于用来训练神经网络的数据集,所得到的图像具有鲜明的特征。
下图是这个网络所能做到的一个随机、没有特意挑选的示例。从左到右,第一列是 16x16 的输入图像,第二列是利用标准的双三次插值算法(bicubic interpolation)所能得到的结果,第三列是我们的神经网络的结果,然后最右列是原本的真实图像。

如你所见,神经网络能够产生与原始的人脸非常相似的图像。由于用于训练的数据集主要由面朝正前方而且光线良好的人脸图像组成,所以当脸的朝向不是正前方、光线不足或脸被眼镜或手遮住了部分时,输出的效果会比较差。
Star:3773
Github 地址:https://github.com/junyanz/CycleGAN

由于微信图片上传大小限制,更清晰的图片请到 Github 查看
伯克利视觉组的研究,用于学习没有输入-输出对的图像到图像转换(即 pix2pix)的 Torch 实现,例如:

此外,另一项相关研究也十分不错:
pix2pix
Star:2965
Github 地址:https://github.com/phillipi/pix2pix
Star:3338(去年 8 月 3076)
Github 地址:https://github.com/yahoo/open_nsfw

这是雅虎构建的用于检测图片是否包含不适宜工作场所(NSFW)内容的深度神经网络项目,GitHub 库中包含了网络的 Caffe 模型的代码。检测具有攻击性或成人内容的图像是研究人员进行了几十年的一个难题。随着计算机视觉技术和深度学习的发展,算法已经成熟,雅虎的这个模型能以更高的精度分辨色情图像。
由于 NSFW 界定其实是很主观的,有的人反感的东西可能其他人并不觉得如何。雅虎的这个深度神经网络只关注NSFW内容的一种类型,即色情图片,所以该模型不适用于检测素描、文字、动画、暴力图片等内容。
Star:3337(去年 8 月 3010)
Github 地址:https://github.com/karpathy/neuraltalk2

循环神经网络(RNN)可以用于给图像取标题。NeuralTalk2 比原始版本的 NeuralTalk 更快而且性能更好。与原来的 NeuralTalk 相比,NeuralTalk2 的实现是批量的,可以使用 Torch 在 GPU上运行,并且支持 CNN 微调。这些都使得语言模型(~100x)的训练速度大大加快,但由于我们还有一个 VGGNet,因此总体上的提升没有很多。但是这仍然是个好模型,可以在 2~3 天里训练好,而且表现出的性能非常好。
Google Brain 2016年9月22日发布了 Vinyals et al.(2015)的图说模型(前文介绍的Show and Tell 模型)。它的核心模型与 NeuralTalk2(一个CNN后面跟着RNN)非常相似,但由于 Google 有更好的CNN,加上一些小技巧和更细致的工程,Google 发布的模型应该比 NeuralTalk2 的效果更好。这个项目里用 Torch 实现的代码将作为教育目的保留。
Star:3093(去年 8 月 2956)
Github 地址:https://github.com/pavelgonchar/colornet

Colornet 是一个给灰度图像自动上色的神经网络。效果如上图所示。
以下则为上次入选,这次却没有进入TOP20 的项目(Star 低于 2000 的项目就不纳入统计了):
Star:2893(去年 8 月 2769)
GitHub 地址:https://github.com/awentzonline/image-analogies

“神经图像类比”(neural image analogies)这个项目基本上是 A. Hertzmann et. al(2001)的论文“Image Analogies”的一个实现。在这个项目中,我们使用了 VGG16 的特征,利用 Chuan Li, Michael Wand (2016) 的论文“Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis”中描述的方法进行patch的匹配和混合。初始代码改编自 Keras 的“神经风格迁移”示例。
Star:2866(去年 8 月 2143)
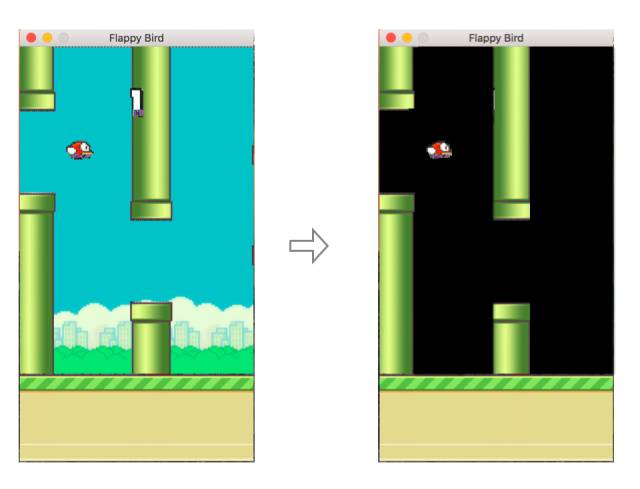
Github 地址:https://github.com/yenchenlin/DeepLearningFlappyBird
这个项目使用深度Q网络(Deep Q-Network,DQN)学习玩 Flappy Bird 游戏。
只能说,FlappyBird 的风潮已经过去了……

这个项目灵感来自使用深度增强学习玩 Atari 游戏(Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." 2013),论文中提出深度Q学习算法(Deep Q Learning algorithm),我们发现这个算法可以推广到 Flappy Bird 游戏上。
DQN 是一个卷积神经网络,用 Q-learning 的变体进行训练,其输入是原始像素,输出是一个预估未来的奖励的价值函数。由于DQN的训练的每个时间步骤都需要观察屏幕中的原始像素值,Kevin Chen 发现删除原始游戏中的背景可以让收敛更快。这个过程如下图所示: