来源 | 数据派THU(ID:DatapiTHU)
百度于今年早些时候发布了其最新的NLP架构ERNIE 2.0,在GLUE基准测试中的所有任务上得分均远高于XLNet和BERT。NLP的这一重大突破利用了一项被称为“连续增量式多任务学习”的创新技术。在本文中,我们将直观地解释“连续多任务学习”的概念,构建ERNIE 2.0模型,并解决有关ERNIE 2.0结果的疑虑。
预备知识:
(请看这个视频:https://bit.ly/2lIADHm)
什么是多任务学习?
为了理解多任务学习,让我们从单任务学习示例开始:为了简单起见,想象一下在NLP(自然语言处理)预训练中使用的简单前馈神经网络。任务是预测句子中的下一个单词。

输入字符串是“ I like New”,正确的输出是字符串“ York”。
训练过程(梯度下降)可以看成是滚下山坡的球:这里的地形是损失函数(也称为成本/误差函数),球的位置代表所有参数的当前值(权重和偏差)。
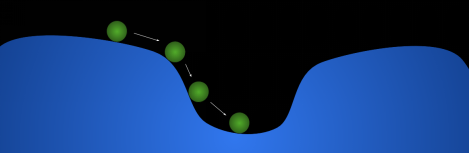
此图仅有两个维度以用于可视化目的。 如果这个比喻让你无法理解,请查看对梯度下降的理解:https://bit.ly/2C080IK。现在,如果你希望神经网络执行多个任务怎么办? 例如,预测句子中的下一个单词并进行情感分析(预测态度分为正面,中立或负面。例如,“你很棒”被归为正面)。
实际上,你可以直接加上另一个输出!

输入为“I like New”,下一个单词预测为“York”,情感预测为正面。
然后,将两个输出的损失相加并求平均值,最后的损耗用于训练网络,因为这样就可以将两个任务的损失都降至最低。
这次,可以将训练过程可视化为将两种地形(两个损失函数)加在一起以获得一个新的地形(最终损失函数),然后执行梯度下降。

Figure 1: Calculating the final loss function and performing gradient descent
图1:计算最终损失函数并执行梯度下降
这就是多任务学习的本质-训练一个神经网络执行多个任务,以便该模型可以开发语言的通用表达形式,而不是将自身限制到一个特定的任务上。实际上,ERNIE 2.0训练其神经网络执行7个任务,后面将对此进行详细说明。
多任务学习在自然语言处理中尤其有用,因为预训练过程的目标是“理解”语言。同样,在语言理解方面,人类也会执行多项任务。
我们已经解释了多任务学习,而ERNIE 2.0架构中还有另一个关键概念,那就是……
持续学习
训练神经网络面临的一个挑战是这样一个事实:局部最小值并不总是全局最小值。
作为示例,让我们看一下上个例子种最终损失函数的形态-如果我们对权重进行不同的初始化,即将球放置在其他位置,会怎么样?

图 2
这次的局部最小值远非理想值。为解决此问题并找到更好的局部最小值,使得该最小值更可能是全局最小值,ERNIE 2.0提出了“持续学习”的概念。
不是训练所有任务(图2),而是按顺序训练它们:
-
在任务1上进行训练
-
使用上一步中的参数,并在任务1、2上进行训练
-
使用上一步中的参数,并在任务1、2、3上进行训练,以此类推…
这是受人类启发的,因为我们是逐步学习而不是一次学习多个任务。之所以行之有效,是因为如果达到任务1的全局最小值,那么将两个损失函数加在一起时,与使用完全随机参数开始时相比,更有可能获得全局最小值(图3)。

图 3
持续学习还可以轻松添加新任务-只需在序列中添加一个额外的步骤即可(例如,第3步:训练任务1、2、3)。但是,请记住,必须训练所有先前的任务以及新任务,以确保将损失函数相加。
此外,在ERNIE 2.0中,Adam Optimizer用于保证有更大机会定位到全局最小值,但这不在本文的讨论范围之内。如果您想了解更多信息,请访问以下链接:
https://arxiv.org/pdf/1412.6980.pdf
ERINE 2.0模型
于是,我们终于可以构建ERINE2.0模型了!

这张图在论文4.2.3节
让我们从输入开始:输入包含token embedding, sentence embedding, sentence embedding, position embedding, task embedding。如果您没有听说过embedding,它们实际上是一种表示形式,可以将人类可以理解的内容转换为机器可以理解的内容。(在此处了解更多信息:https://bit.ly/2k52nWt)
接下来,将其输入可以是任何形式神经网络的“编码器”中。当然,如果你想要在自然语言处理种获得最好的效果,就应该使用RNN或者一种Transformer。
ERINIE 2.0使用的transformer与BERT和XLNET相同。
最后,输出结果包含了7个任务的输出,分别是:
-
知识遮盖
-
标记-文档关系
-
大写预测
-
句子重新排序
-
句子距离
-
话语关系
-
相关性
这些任务是专门挑选用来学习语言的词汇,句法(结构)和语义(含义)信息的。阅读论文第4.2节,以详细了解每个任务。
训练过程基本上与我们之前在持续学习部分演示的示例相同:
先训练任务1,然后任务1&2,然后任务1&2&3,以此类推……直到训练完7个任务。
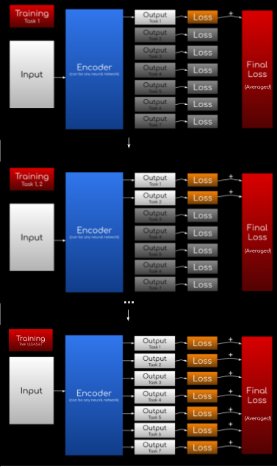
图 4
如图4所示,当任务在训练过程中处于非活动状态时,其损失函数基本上始终为零。
另外,ERNIE 2.0设置中的一个不同之处是最终对损失进行平均(而不是求和)。
有关ERNIE 2.0结果的疑虑
ERNIE 2.0在GLUE基准测试的每个任务中都击败了所有以前的模型,例如XLNet和BERT。虽然该论文暗示该开创性的结果是由持续多任务学习引起的,但尚无模型简化测试来证明这一点。持续多任务学习之外的某些因素可能在击败XLNET和BERT方面发挥了关键作用:
-
使用了更多数据来训练模型(Reddit,发现数据…)。但是,这在一定程度上是不可避免的。由于多任务学习的训练目标更多,因此需要更多的数据。
-
该神经网络在PaddlePaddle中实现
-
更重要的是,为了将ERNIE 2.0的结果归因于“持续多任务学习”,需要回答以下问题:
-
多任务学习对结果有多大影响?
-
持续学习对结果有多大影响?如果一次训练了所有七个任务而不是依次进行会怎么样?
-
任务的顺序有影响吗?
结论
总而言之,ERNIE 2.0引入了“连续多任务学习”的概念,并且在所有NLP任务中均成功胜过XLNET和BERT。可以说连续多任务学习是开创性结果中的第一大因素,但仍然有许多问题需要解决。
当然,本文不会涵盖论文的全部主题,例如具体的实验结果,也没有这个必要。本文只是对ERNIE 2.0核心概念进行了直观解释。如果您想全面了解ERNIE 2.0,请同时阅读论文!
论文:
“ERNIE 2.0: A Continual Pre-training Framework for Language Understanding”
作者:
Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, Haifeng Wang
链接:
https://arxiv.org/pdf/1512.03385.pdf
Related:
相关文章:
Interpolation in Autoencoders via an Adversarial Regularizer
Pre-training, Transformers, and Bi-directionality
Large-Scale Evolution of Image Classifiers
原文标题:








