
大家早上好,Glide系列的第三篇终于和大家见面了。在本系列的上一篇文章中,我们一起阅读了一遍Glide的源码,初步了解了这个强大的图片加载框架的基本执行流程。
不过,上一篇文章只能说是比较粗略地阅读了Glide整个执行流程方面的源码,搞明白了Glide的基本工作原理,但并没有去深入分析每一处的细节(事实上也不可能在一篇文章中深入分析每一处源码的细节)。那么从本篇文章开始,我们就一篇篇地来针对Glide某一块功能进行深入地分析,慢慢将Glide中的各项功能进行全面掌握。
今天我们就先从缓存这一块内容开始入手吧。不过今天文章中的源码都建在上一篇源码分析的基础之上,还没有看过上一篇文章的朋友,建议先去阅读 Glide系列第二弹,从源码的角度深入理解Glide的执行流程 。
Glide的缓存设计可以说是非常先进的,考虑的场景也很周全。在缓存这一功能上,Glide又将它分成了两个模块,一个是内存缓存,一个是硬盘缓存。
这两个缓存模块的作用各不相同,内存缓存的主要作用是防止应用重复将图片数据读取到内存当中,而硬盘缓存的主要作用是防止应用重复从网络或其他地方重复下载和读取数据。
内存缓存和硬盘缓存的相互结合才构成了Glide极佳的图片缓存效果,那么接下来我们就分别来分析一下这两种缓存的使用方法以及它们的实现原理。
既然是缓存功能,就必然会有用于进行缓存的Key。那么Glide的缓存Key是怎么生成的呢?我不得不说,Glide的缓存Key生成规则非常繁琐,决定缓存Key的参数竟然有10个之多。不过繁琐归繁琐,至少逻辑还是比较简单的,我们先来看一下Glide缓存Key的生成逻辑。
生成缓存Key的代码在Engine类的load()方法当中,这部分代码我们在上一篇文章当中已经分析过了,只不过当时忽略了缓存相关的内容,那么我们现在重新来看一下:

可以看到,这里在第11行调用了fetcher.getId()方法获得了一个id字符串,这个字符串也就是我们要加载的图片的唯一标识,比如说如果是一张网络上的图片的话,那么这个id就是这张图片的url地址。
接下来在第12行,将这个id连同着signature、width、height等等10个参数一起传入到EngineKeyFactory的buildKey()方法当中,从而构建出了一个EngineKey对象,这个EngineKey也就是Glide中的缓存Key了。
可见,决定缓存Key的条件非常多,即使你用override()方法改变了一下图片的width或者height,也会生成一个完全不同的缓存Key。
EngineKey类的源码大家有兴趣可以自己去看一下,其实主要就是重写了equals()和hashCode()方法,保证只有传入EngineKey的所有参数都相同的情况下才认为是同一个EngineKey对象,我就不在这里将源码贴出来了。
有了缓存Key,接下来就可以开始进行缓存了,那么我们先从内存缓存看起。
首先你要知道,默认情况下,Glide自动就是开启内存缓存的。也就是说,当我们使用Glide加载了一张图片之后,这张图片就会被缓存到内存当中,只要在它还没从内存中被清除之前,下次使用Glide再加载这张图片都会直接从内存当中读取,而不用重新从网络或硬盘上读取了,这样无疑就可以大幅度提升图片的加载效率。比方说你在一个RecyclerView当中反复上下滑动,RecyclerView中只要是Glide加载过的图片都可以直接从内存当中迅速读取并展示出来,从而大大提升了用户体验。
而Glide最为人性化的是,你甚至不需要编写任何额外的代码就能自动享受到这个极为便利的内存缓存功能,因为Glide默认就已经将它开启了。
那么既然已经默认开启了这个功能,还有什么可讲的用法呢?只有一点,如果你有什么特殊的原因需要禁用内存缓存功能,Glide对此提供了接口:

可以看到,只需要调用skipMemoryCache()方法并传入true,就表示禁用掉Glide的内存缓存功能。
没错,关于Glide内存缓存的用法就只有这么多,可以说是相当简单。但是我们不可能只停留在这么简单的层面上,接下来就让我们就通过阅读源码来分析一下Glide的内存缓存功能是如何实现的。
其实说到内存缓存的实现,非常容易就让人想到LruCache算法(Least Recently Used),也叫近期最少使用算法。它的主要算法原理就是把最近使用的对象用强引用存储在LinkedHashMap中,并且把最近最少使用的对象在缓存值达到预设定值之前从内存中移除。LruCache的用法也比较简单,我在 http://blog.csdn.net/guolin_blog/article/details/9316683 这篇文章当中有提到过它的用法,感兴趣的朋友可以去参考一下。
那么不必多说,Glide内存缓存的实现自然也是使用的LruCache算法。不过除了LruCache算法之外,Glide还结合了一种弱引用的机制,共同完成了内存缓存功能,下面就让我们来通过源码分析一下。
首先回忆一下,在上一篇文章的第二步load()方法中,我们当时分析到了在loadGeneric()方法中会调用Glide.buildStreamModelLoader()方法来获取一个ModelLoader对象。当时没有再跟进到这个方法的里面再去分析,那么我们现在来看下它的源码:

这里我们还是只看关键,在第11行去构建ModelLoader对象的时候,先调用了一个Glide.get()方法,而这个方法就是关键。我们可以看到,get()方法中实现的是一个单例功能,而创建Glide对象则是在第24行调用GlideBuilder的createGlide()方法来创建的,那么我们跟到这个方法当中:

这里也就是构建Glide对象的地方了。那么观察第22行,你会发现这里new出了一个LruResourceCache,并把它赋值到了memoryCache这个对象上面。你没有猜错,这个就是Glide实现内存缓存所使用的LruCache对象了。不过我这里并不打算展开来讲LruCache算法的具体实现,如果你感兴趣的话可以自己研究一下它的源码。
现在创建好了LruResourceCache对象只能说是把准备工作做好了,接下来我们就一步步研究Glide中的内存缓存到底是如何实现的。
刚才在Engine的load()方法中我们已经看到了生成缓存Key的代码,而内存缓存的代码其实也是在这里实现的,那么我们重新来看一下Engine类load()方法的完整源码:


可以看到,这里在第17行调用了loadFromCache()方法来获取缓存图片,如果获取到就直接调用cb.onResourceReady()方法进行回调。如果没有获取到,则会在第26行调用loadFromActiveResources()方法来获取缓存图片,获取到的话也直接进行回调。只有在两个方法都没有获取到缓存的情况下,才会继续向下执行,从而开启线程来加载图片。
也就是说,Glide的图片加载过程中会调用两个方法来获取内存缓存,loadFromCache()和loadFromActiveResources()。这两个方法中一个使用的就是LruCache算法,另一个使用的就是弱引用。我们来看一下它们的源码:

在loadFromCache()方法的一开始,首先就判断了isMemoryCacheable是不是false,如果是false的话就直接返回null。这是什么意思呢?其实很简单,我们刚刚不是学了一个skipMemoryCache()方法吗?如果在这个方法中传入true,那么这里的isMemoryCacheable就会是false,表示内存缓存已被禁用。
我们继续住下看,接着调用了getEngineResourceFromCache()方法来获取缓存。在这个方法中,会使用缓存Key来从cache当中取值,而这里的cache对象就是在构建Glide对象时创建的LruResourceCache,那么说明这里其实使用的就是LruCache算法了。
但是呢,观察第22行,当我们从LruResourceCache中获取到缓存图片之后会将它从缓存中移除,然后在第16行将这个缓存图片存储到activeResources当中。activeResources就是一个弱引用的HashMap,用来缓存正在使用中的图片,我们可以看到,loadFromActiveResources()方法就是从activeResources这个HashMap当中取值的。使用activeResources来缓存正在使用中的图片,可以保护这些图片不会被LruCache算法回收掉。
好的,从内存缓存中读取数据的逻辑大概就是这些了。概括一下来说,就是如果能从内存缓存当中读取到要加载的图片,那么就直接进行回调,如果读取不到的话,才会开启线程执行后面的图片加载逻辑。
现在我们已经搞明白了内存缓存读取的原理,接下来的问题就是内存缓存是在哪里写入的呢?这里我们又要回顾一下上一篇文章中的内容了。还记不记得我们之前分析过,当图片加载完成之后,会在EngineJob当中通过Handler发送一条消息将执行逻辑切回到主线程当中,从而执行handleResultOnMainThread()方法。那么我们现在重新来看一下这个方法,代码如下所示:

在第13行,这里通过EngineResourceFactory构建出了一个包含图片资源的EngineResource对象,然后会在第16行将这个对象回调到Engine的onEngineJobComplete()方法当中,如下所示:

现在就非常明显了,可以看到,在第13行,回调过来的EngineResource被put到了activeResources当中,也就是在这里写入的缓存。
那么这只是弱引用缓存,还有另外一种LruCache缓存是在哪里写入的呢?这就要介绍一下EngineResource中的一个引用机制了。观察刚才的handleResultOnMainThread()方法,在第15行和第19行有调用EngineResource的acquire()方法,在第23行有调用它的release()方法。其实,EngineResource是用一个acquired变量用来记录图片被引用的次数,调用acquire()方法会让变量加1,调用release()方法会让变量减1,代码如下所示:

也就是说,当acquired变量大于0的时候,说明图片正在使用中,也就应该放到activeResources弱引用缓存当中。而经过release()之后,如果acquired变量等于0了,说明图片已经不再被使用了,那么此时会在第24行调用listener的onResourceReleased()方法来释放资源,这个listener就是Engine对象,我们来看下它的onResourceReleased()方法:

可以看到,这里首先会将缓存图片从activeResources中移除,然后再将它put到LruResourceCache当中。这样也就实现了正在使用中的图片使用弱引用来进行缓存,不在使用中的图片使用LruCache来进行缓存的功能。
这就是Glide内存缓存的实现原理。
接下来我们开始学习硬盘缓存方面的内容。
不知道你还记不记得,在本系列的第一篇文章中我们就使用过硬盘缓存的功能了。当时为了禁止Glide对图片进行硬盘缓存而使用了如下代码:
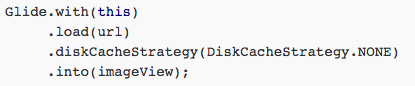
调用diskCacheStrategy()方法并传入DiskCacheStrategy.NONE,就可以禁用掉Glide的硬盘缓存功能了。
这个diskCacheStrategy()方法基本上就是Glide硬盘缓存功能的一切,它可以接收四种参数:
DiskCacheStrategy.NONE: 表示不缓存任何内容。
DiskCacheStrategy.SOURCE: 表示只缓存原始图片。
DiskCacheStrategy.RESULT: 表示只缓存转换过后的图片(默认选项)。
DiskCacheStrategy.ALL : 表示既缓存原始图片,也缓存转换过后的图片。
上面四种参数的解释本身并没有什么难理解的地方,但是有一个概念大家需要了解,就是当我们使用Glide去加载一张图片的时候,Glide默认并不会将原始图片展示出来,而是会对图片进行压缩和转换(我们会在后面学习这方面的内容)。总之就是经过种种一系列操作之后得到的图片,就叫转换过后的图片。而Glide默认情况下在硬盘缓存的就是转换过后的图片,我们通过调用diskCacheStrategy()方法则可以改变这一默认行为。
好的,关于Glide硬盘缓存的用法也就只有这么多,那么接下来还是老套路,我们通过阅读源码来分析一下,Glide的硬盘缓存功能是如何实现的。
首先,和内存缓存类似,硬盘缓存的实现也是使用的LruCache算法,而且Google还提供了一个现成的工具类DiskLruCache。我之前也专门写过一篇文章对这个DiskLruCache工具进行了比较全面的分析,感兴趣的朋友可以参考一下 http://blog.csdn.net/guolin_blog/article/details/28863651 。当然,Glide是使用的自己编写的DiskLruCache工具类,但是基本的实现原理都是差不多的。
接下来我们看一下Glide是在哪里读取硬盘缓存的。这里又需要回忆一下上篇文章中的内容了,Glide开启线程来加载图片后会执行EngineRunnable的run()方法,run()方法中又会调用一个decode()方法,那么我们重新再来看一下这个decode()方法的源码:

可以看到,这里会分为两种情况,一种是调用decodeFromCache()方法从硬盘缓存当中读取图片,一种是调用decodeFromSource()来读取原始图片。默认情况下Glide会优先从缓存当中读取,只有缓存中不存在要读取的图片时,才会去读取原始图片。那么我们现在来看一下decodeFromCache()方法的源码,如下所示:

可以看到,这里会先去调用DecodeJob的decodeResultFromCache()方法来获取缓存,如果获取不到,会再调用decodeSourceFromCache()方法获取缓存,这两个方法的区别其实就是DiskCacheStrategy.RESULT和DiskCacheStrategy.SOURCE这两个参数的区别,相信不需要我再做什么解释吧。
那么我们来看一下这两个方法的源码吧,如下所示:

可以看到,它们都是调用了loadFromCache()方法从缓存当中读取数据,如果是decodeResultFromCache()方法就直接将数据解码并返回,如果是decodeSourceFromCache()方法,还要调用一下transformEncodeAndTranscode()方法先将数据转换一下再解码并返回。
然而我们注意到,这两个方法中在调用loadFromCache()方法时传入的参数却不一样,一个传入的是resultKey,另外一个却又调用了resultKey的getOriginalKey()方法。这个其实非常好理解,刚才我们已经解释过了,Glide的缓存Key是由10个参数共同组成的,包括图片的width、height等等。但如果我们是缓存的原始图片,其实并不需要这么多的参数,因为不用对图片做任何的变化。那么我们来看一下getOriginalKey()方法的源码:

可以看到,这里其实就是忽略了绝大部分的参数,只使用了id和signature这两个参数来构成缓存Key。而signature参数绝大多数情况下都是用不到的,因此基本上可以说就是由id(也就是图片url)来决定的Original缓存Key。
搞明白了这两种缓存Key的区别,那么接下来我们看一下loadFromCache()方法的源码吧:

这个方法的逻辑非常简单,调用getDiskCache()方法获取到的就是Glide自己编写的DiskLruCache工具类的实例,然后调用它的get()方法并把缓存Key传入,就能得到硬盘缓存的文件了。如果文件为空就返回null,如果文件不为空则将它解码成Resource对象后返回即可。
这样我们就将硬盘缓存读取的源码分析完了,那么硬盘缓存又是在哪里写入的呢?趁热打铁我们赶快继续分析下去。
刚才已经分析过了,在没有缓存的情况下,会调用decodeFromSource()方法来读取原始图片。那么我们来看下这个方法:

这个方法中只有两行代码,decodeSource()顾名思义是用来解析原图片的,而transformEncodeAndTranscode()则是用来对图片进行转换和转码的。我们先来看decodeSource()方法:

这里会在第5行先调用fetcher的loadData()方法读取图片数据,然后在第9行调用decodeFromSourceData()方法来对图片进行解码。接下来会在第18行先判断是否允许缓存原始图片,如果允许的话又会调用cacheAndDecodeSourceData()方法。而在这个方法中同样调用了getDiskCache()方法来获取DiskLruCache实例,接着调用它的put()方法就可以写入硬盘缓存了,注意原始图片的缓存Key是用的resultKey.getOriginalKey()。
好的,原始图片的缓存写入就是这么简单,接下来我们分析一下transformEncodeAndTranscode()方法的源码,来看看转换过后的图片缓存是怎么写入的。代码如下所示:

这里的逻辑就更加简单明了了。先是在第3行调用transform()方法来对图片进行转换,然后在writeTransformedToCache()方法中将转换过后的图片写入到硬盘缓存中,调用的同样是DiskLruCache实例的put()方法,不过这里用的缓存Key是resultKey。
这样我们就将Glide硬盘缓存的实现原理也分析完了。虽然这些源码看上去如此的复杂,但是经过Glide出色的封装,使得我们只需要通过skipMemoryCache()和diskCacheStrategy()这两个方法就可以轻松自如地控制Glide的缓存功能了。
了解了Glide缓存的实现原理之后,接下来我们再来学习一些Glide缓存的高级技巧吧。
虽说Glide将缓存功能高度封装之后,使得用法变得非常简单,但同时也带来了一些问题。
比如之前有一位群里的朋友就跟我说过,他们项目的图片资源都是存放在七牛云上面的,而七牛云为了对图片资源进行保护,会在图片url地址的基础之上再加上一个token参数。也就是说,一张图片的url地址可能会是如下格式:

而使用Glide加载这张图片的话,也就会使用这个url地址来组成缓存Key。
但是接下来问题就来了,token作为一个验证身份的参数并不是一成不变的,很有可能时时刻刻都在变化。而如果token变了,那么图片的url也就跟着变了,图片url变了,缓存Key也就跟着变了。结果就造成了,明明是同一张图片,就因为token不断在改变,导致Glide的缓存功能完全失效了。
这其实是个挺棘手的问题,而且我相信绝对不仅仅是七牛云这一个个例,大家在使用Glide的时候很有可能都会遇到这个问题。
那么该如何解决这个问题呢?我们还是从源码的层面进行分析,首先再来看一下Glide生成缓存Key这部分的代码:

来看一下第11行,刚才已经说过了,这个id其实就是图片的url地址。那么,这里是通过调用fetcher.getId()方法来获取的图片url地址,而我们在上一篇文章中已经知道了,fetcher就是HttpUrlFetcher的实例,我们就来看一下它的getId()方法的源码吧,如下所示:
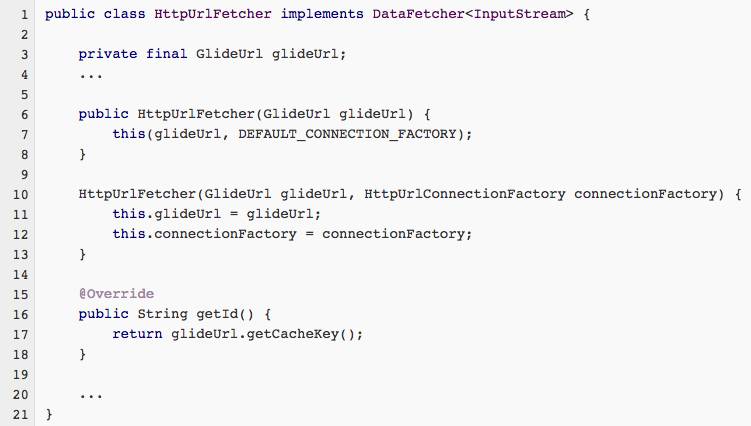
可以看到,getId()方法中又调用了GlideUrl的getCacheKey()方法。那么这个GlideUrl对象是从哪里来的呢?其实就是我们在load()方法中传入的图片url地址,然后Glide在内部把这个url地址包装成了一个GlideUrl对象。
很明显,接下来我们就要看一下GlideUrl的getCacheKey()方法的源码了,如下所示:

这里我将代码稍微进行了一点简化,这样看上去更加简单明了。GlideUrl类的构造函数接收两种类型的参数,一种是url字符串,一种是URL对象。然后getCacheKey()方法中的判断逻辑非常简单,如果传入的是url字符串,那么就直接返回这个字符串本身,如果传入的是URL对象,那么就返回这个对象toString()后的结果。
其实看到这里,我相信大家已经猜到解决方案了,因为getCacheKey()方法中的逻辑太直白了,直接就是将图片的url地址进行返回来作为缓存Key的。那么其实我们只需要重写这个getCacheKey()方法,加入一些自己的逻辑判断,就能轻松解决掉刚才的问题了。
创建一个MyGlideUrl继承自GlideUrl,代码如下所示:

可以看到,这里我们重写了getCacheKey()方法,在里面加入了一段逻辑用于将图片url地址中token参数的这一部分移除掉。这样getCacheKey()方法得到的就是一个没有token参数的url地址,从而不管token怎么变化,最终Glide的缓存Key都是固定不变的了。
当然,定义好了MyGlideUrl,我们还得使用它才行,将加载图片的代码改成如下方式即可:
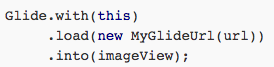
也就是说,我们需要在load()方法中传入这个自定义的MyGlideUrl对象,而不能再像之前那样直接传入url字符串了。不然的话Glide在内部还是会使用原始的GlideUrl类,而不是我们自定义的MyGlideUrl类。
这样我们就将这个棘手的缓存问题给解决掉了。
好了,关于Glide缓存方面的内容今天就分析到这里,现在我们不光掌握了Glide缓存的基本用法和高级技巧,还了解了它背后的实现原理,又是收获满满的一篇文章啊。下一篇文章当中,我会继续带着大家深入分析Glide的其他功能模块,讲一讲回调方面的知识,敬请期待。
每天学习累了,看些搞笑的段子放松一下吧。关注最具娱乐精神的公众号,每天都有好心情。

如果你有好的技术文章想和大家分享,欢迎向我的公众号投稿,投稿具体细节请在公众号主页点击“投稿”菜单查看。
欢迎长按下图 -> 识别图中二维码或者扫一扫关注我的公众号:










