(点击
上方蓝字
,快速关注我们)
来源:伯乐在线专栏作者 - iPytLab
如有好文章投稿,请点击 → 这里了解详情
前言
本文中作者使用MPI的Python接口mpi4py来将自己的遗传算法框架GAFT进行多进程并行加速。并对加速效果进行了简单测试。
项目链接:
正文
我们在用遗传算法优化目标函数的时候,函数通常都是高维函数,其导数一般比较难求取。这样我们的适应度函数计算通常都是比较费时的计算。
例如在使用遗传算法寻找最优结构时候通常需要调用量化软件进行第一性原理计算结构的total energy,这是非常费时的过程; 例如我们优化力场参数的时候,以力场计算出的能量同基准能量之前的误差作为适应度,也需要调用相应的力场程序获取总能量来求取,同样这个过程也是相对耗时的。
这就会导致一个问题,当我们的
种群比较大
的时候,我们需要利用适应度信息来产生下一代种群,这时候每一代繁殖的过程将会很耗时。但有幸的是,种群的选择交叉变异过程对于种群中的个体都是
相互独立
的过程,我们可以将这一部分进行并行处理来加速遗传算法的迭代。
使用mpi4py
由于实验室的集群都是MPI环境,我还是选择使用MPI接口来将代码并行化,这里我还是用了MPI接口的Python版本mpi4py来将代码并行化。关于mpi4py的使用,我之前写过一篇博客专门做了介绍,可以参见《
Python多进程并行编程实践-mpi4py的使用
》
将mpi4py的接口进一步封装
为了能让mpi的接口在GAFT中更方便的调用,我决定将mpi4py针对遗传算法中需要用的地方进行进一步封装,为此我单独写了个MPIUtil类, 详细代码参见gaft/mpiutil.py。
封装通信子常用的接口
例如进程同步, 获取rank,进程数,判断是否为主进程等。
class
MPIUtil
(
object
)
:
def
__init__
(
self
)
:
logger_name
=
'gaft.{}'
.
format
(
self
.
__class__
.
__name__
)
self
.
_logger
=
logging
.
getLogger
(
logger_name
)
# Wrapper for common MPI interfaces.
def
barrier
(
self
)
:
if
MPI_INSTALLED
:
mpi_comm
=
MPI
.
COMM_WORLD
mpi_comm
.
barrier
()
@
property
def
rank
(
self
)
:
if
MPI_INSTALLED
:
mpi_comm
=
MPI
.
COMM_WORLD
return
mpi_comm
.
Get_rank
()
else
:
return
0
@
property
def
size
(
self
)
:
if
MPI_INSTALLED
:
mpi_comm
=
MPI
.
COMM_WORLD
return
mpi_comm
.
Get_size
()
else
:
return
1
@
property
def
is_master
(
self
)
:
return
self
.
rank
==
0
组内集合通信接口
由于本次并行化的任务是在种群繁衍时候进行的,因此我需要将上一代种群进行划分,划分成多个子部分,然后在每个进程中对划分好的子部分进行选择交叉变异等遗传操作。在最后将每个字部分得到的子种群进行收集合并。为此写了几个划分和收集的接口:
def
split_seq
(
self
,
sequence
)
:
'''
Split the sequence according to rank and processor number.
'''
starts
=
[
i
for
i
in
range
(
0
,
len
(
sequence
),
len
(
sequence
)
//
self
.
size
)]
ends
=
starts
[
1
:
]
+
[
len
(
sequence
)]
start
,
end
=
list
(
zip
(
starts
,
ends
))[
self
.
rank
]
return
sequence
[
start
:
end
]
def
split_size
(
self
,
size
)
:
'''
Split a size number(int) to sub-size number.
'''
if
size
<
self
.
size
:
warn_msg
=
(
'Splitting size({}) is smaller than process '
+
'number({}), more processor would be '
+
'superflous'
).
format
(
size
,
self
.
size
)
self
.
_logger
.
warning
(
warn_msg
)
splited_sizes
=
[
1
]
*
size
+
[
0
]
*
(
self
.
size
-
size
)
elif
size
%
self
.
size
!=
0
:
residual
=
size
%
self
.
size
splited_sizes
=
[
size
//
self
.
size
]
*
self
.
size
for
i
in
range
(
residual
)
:
splited_sizes
[
i
]
+=
1
else
:
splited_sizes
=
[
size
//
self
.
size
]
*
self
.
size
return
splited_sizes
[
self
.
rank
]
def
merge_seq
(
self
,
seq
)
:
'''
Gather data in sub-process to root process.
'''
if
self
.
size
==
1
:
return
seq
mpi_comm
=
MPI
.
COMM_WORLD
merged_seq
=
mpi_comm
.
allgather
(
seq
)
return
list
(
chain
(
*
merged_seq
))
用于限制程序在主进程执行的装饰器
有些函数例如日志输出,数据收集的函数,我只希望在主进程执行,为了方便,写了个装饰器来限制函数在主进程中执行:
def
master_only
(
func
)
:
'''
Decorator to limit a function to be called
only in master process in MPI env.
'''
@
wraps
(
func
)
def
_call_in_master_proc
(
*
args
,
**
kwargs
)
:
if
mpi
.
is_master
:
return
func
(
*
args
,
**
kwargs
)
return
_call_in_master_proc
在遗传算法主循环中添加并行
主要在种群繁衍中对种群针对进程数进行划分然后并行进行遗传操作并合并子种群完成并行,代码改动很少。详见:https://github.com/PytLab/gaft/blob/master/gaft/engine.py#L67
# Enter evolution iteration.
for
g
in
range
(
ng
)
:
# Scatter jobs to all processes.
local_indvs
=
[]
local_size
=
mpi
.
split_size
(
self
.
population
.
size
//
2
)
# Fill the new population.
for
_
in
range
(
local_size
)
:
# Select father and mother.
parents
=
self
.
selection
.
select
(
self
.
population
,
fitness
=
self
.
fitness
)
# Crossover.
children
=
self
.
crossover
.
cross
(
*
parents
)
# Mutation.
children
=
[
self
.
mutation
.
mutate
(
child
)
for
child
in
children
]
# Collect children.
local_indvs
.
extend
(
children
)
# Gather individuals from all processes.
indvs
=
mpi
.
merge_seq
(
local_indvs
)
# The next generation.
self
.
population
.
individuals
=
indvs
测试加速效果
测试一维搜索
下面我针对项目中的一维优化的例子进行并行加速测试来看看加速的效果。例子代码在/examples/ex01/
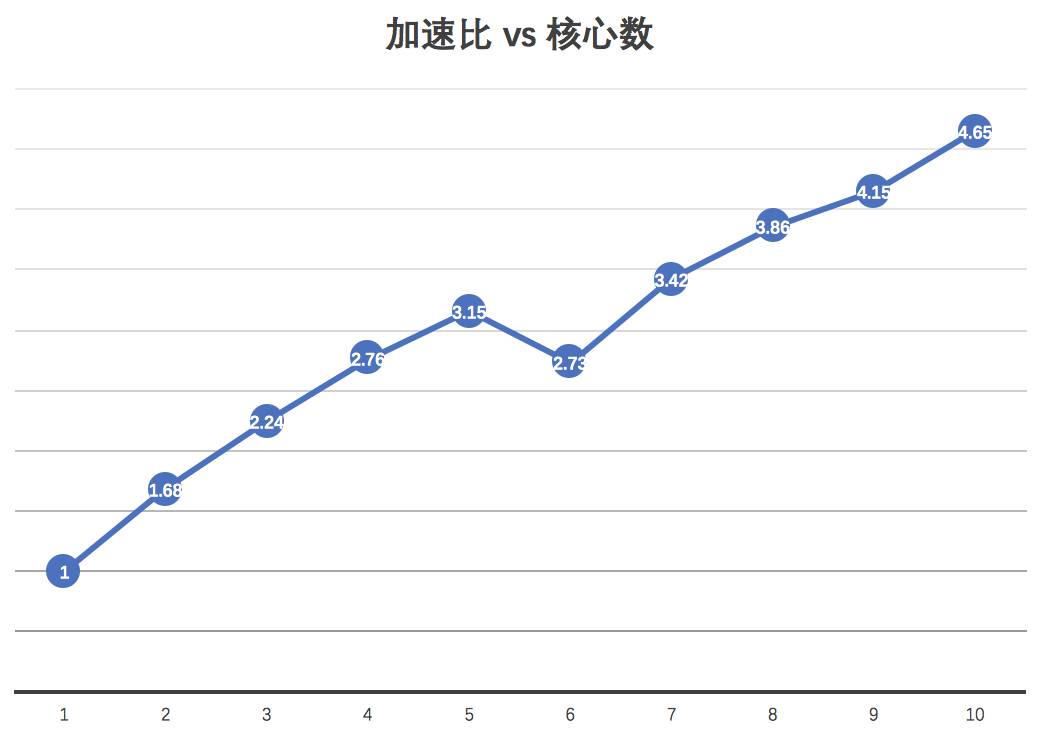
由于自己本子核心数量有限,我把gaft安装在实验室集群上使用MPI利用多核心进行并行计算一维优化,种群大小为50,代数为100,针对不同核心数可以得到不同的优化时间和加速比。可视化如下图:
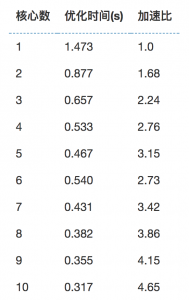
核心数与优化时间的关系:

核心数与加速比:
测试力场优化
这里我对自己要研究的对象进行加速测试,这部分代码并未开源,针对每个个体的适应度计算都需要调用其他的计算程序,因此此过程相比直接有函数表达式的目标函数计算要耗时很多。
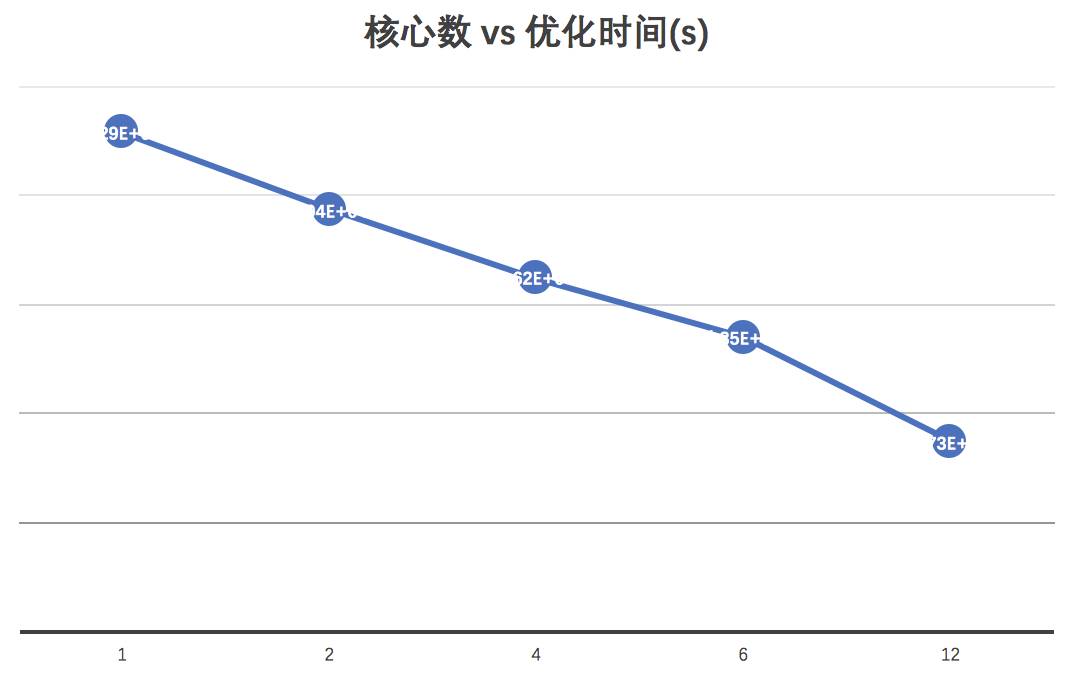
同样,我针对不同核心数看看使用MPI在集群上加速的效果:
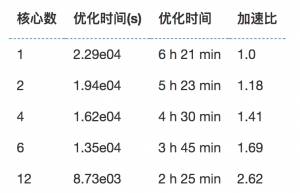
核心数与优化时间的关系:
核心数与加速比:
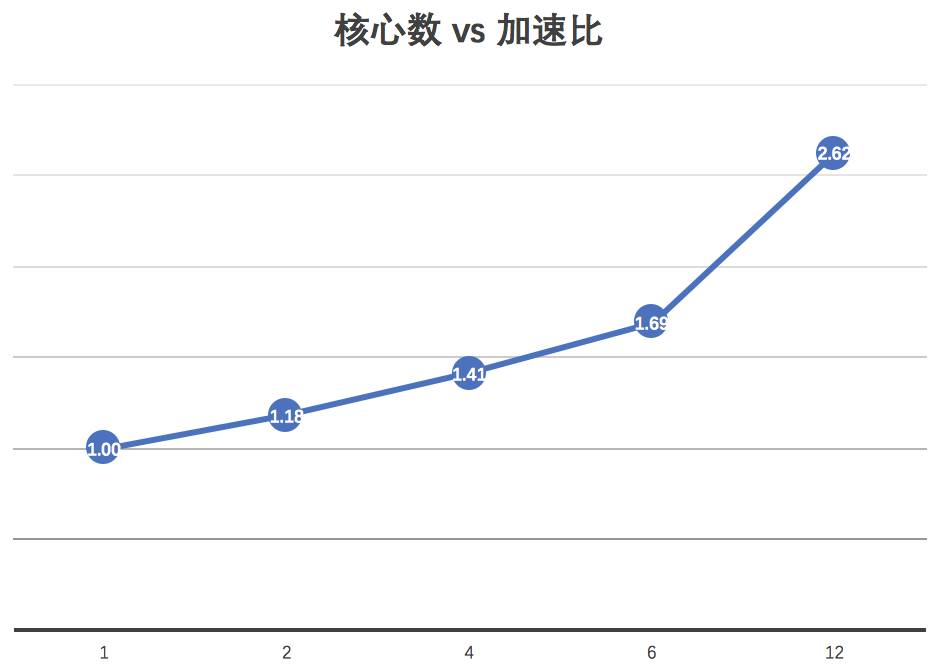
可见针对上述两个案例,MPI对遗传算法的加速还是比较理想的,程序可以扔到集群上飞起啦~~~
总结
本文主要总结了使用mpi4py对遗传算法进行并行化的方法和过程,并对加速效果进行了测试,可见MPI对于遗传算法框架GAFT的加速效果还是较为理想的。带有MPI并行的遗传算法框架目前也已更新并上传至GitHub(https://github.com/PytLab/gaft) 欢迎围观[]~( ̄▽ ̄)~*
看完本文有收获?请转发分享给更多人
关注「大数据与机器学习文摘」,成为Top 1%






