编辑:Gemini
感知机(或称感知器,Perceptron)是Frank Rosenblatt在1957年就职于Cornell航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1。感知机是神经网络的雏形,同时也是支持向量机的基础,感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。感知机学习旨在求出将训练数据进行线性划分的分离超平面。
感知机是生物神经细胞的简单抽象。神经细胞结构大致可分为:树突、突触、细胞体及轴突。单个神经细胞可被视为一种只有两种状态的机器——激动时为‘是’,而未激动时为‘否’。神经细胞的状态取决于从其它的神经细胞收到的输入信号量,及突触的强度(抑制或加强)。当信号量总和超过了某个阈值时,细胞体就会激动,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。为了模拟神经细胞行为,与之对应的感知机基础概念被提出,如权量(突触)、偏置(阈值)及激活函数(细胞体)。
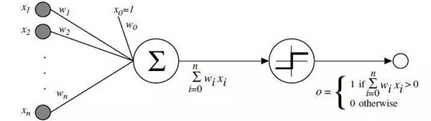
图1 感知机算法
在人工神经网络领域中,感知机也被指为单层的人工神经网络,以区别于较复杂的多层感知机(Multilayer Perceptron)。作为一种线性分类器,(单层)感知机可说是最简单的前向人工神经网络形式。尽管结构简单,感知机能够学习并解决相当复杂的问题。感知机主要的本质缺陷是它不能处理线性不可分问题。
1943年,心理学家Warren McCulloch和数理逻辑学家Walter Pitts在合作的《A logical calculus of the ideas immanent in nervous activity》中提出并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。

图2 Warren McCulloch和Walter Pitts以及他们提出的模型
1949年,心理学家Donald O. Hebb在《The Organization of Behavior》中描述了神经元学习法则。

图3 Hebb学习法则
1957年,美国神经学家Frank Rosenblatt在Cornell航空实验室中,他成功在IBM 704机上完成了感知机的仿真。两年后,他又成功实现了能够识别一些英文字母、基于感知机的神经计算机——Mark1,并于1960年6月23日,展示与众。

图4 Rosenblatt和Mark1 感知机
Rosenblatt,在Hebb学习法则的基础上,发展了一种迭代、试错、类似于人类学习过程的学习算法——感知机学习,该算法的初衷是为了‘教导’感知机识别图像。除了能够识别出现较多次的字母,感知机也能对不同书写方式的字母图像进行概括和归纳。但是,由于本身的局限,感知机除了那些包含在训练集里的图像以外,不能对受干扰(半遮蔽、不同大小、平移、旋转)的字母图像进行可靠的识别,即对噪声敏感。
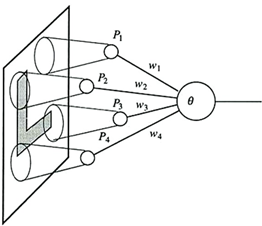
图5 Rosenblatt的感知机示意图
首个有关感知机的成果,由Rosenblatt于1958年发表在《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》里。1962年,他又出版了《Principles of Neurodynamics: Perceptrons and the theory of brain mechanisms》一书,向大众深入解释感知机的理论知识及背景假设。此书介绍了一些重要的概念及定理证明,例如感知机收敛定理。
虽然最初被认为有着良好的发展潜能,但感知机最终被证明不能处理诸多的模式识别问题。1969年,Marvin Minsky和Seymour Papert在《Perceptrons》书中,仔细分析了以感知机为代表的单层神经网络系统的功能及局限,证明感知机不能解决简单的异或(XOR)等线性不可分问题,但Rosenblatt和Minsky及Papert等人在当时已经了解到多层神经网络能够解决线性不可分的问题。

图6 Marvin Minsky和Seymour Papert及XOR问题
由于Rosenblatt等人没能够及时推广感知机学习算法到多层神经网络上,又由于《Perceptrons》在研究领域中的巨大影响,及人们对书中论点的误解,造成了人工神经领域发展的长年停滞及低潮,直到人们认识到多层感知机没有单层感知机固有的缺陷及反向传播算法在80年代的提出,才有所恢复。1987年,书中的错误得到了校正,并更名再版为《Perceptrons - Expanded Edition》。
在Freund及Schapire(1998)使用核技巧改进感知机学习算法之后,愈来愈多的人对感知机学习算法产生兴趣。后来的研究表明除了二元分类,感知机也能应用在较复杂、被称为structured learning类型的任务上(Collins, 2002),又或使用在分布式计算环境中的大规模机器学习问题上(McDonald, Hall and Mann, 2011)。
假设输入空间(特征向量)为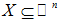 ,输出空间为
,输出空间为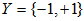 。输入
。输入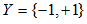 表示实例的特征向量,对应于输入空间的点;输出
表示实例的特征向量,对应于输入空间的点;输出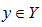 表示示例的类别。由输入空间到输出空间的函数为
表示示例的类别。由输入空间到输出空间的函数为
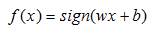
(1)
称为感知机。其中,参数w叫做权值向量weight,b称为偏置bias, sign为反对称的符号函数,定义为
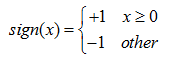
(2)
感知机是一种线性分类模型,属于判别模型。我们需要做的就是找到一个最佳的满足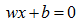 的w和b的值,即确定一个分离超平面(Separating Hyperplane)将正负样本分开。如图7所示。
的w和b的值,即确定一个分离超平面(Separating Hyperplane)将正负样本分开。如图7所示。
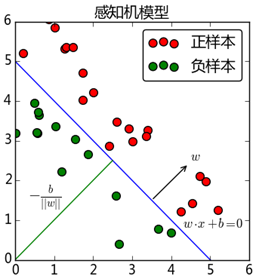
图7 线性可分的感知机模型
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练数据集中正样本和负样本完全分开的分类超平面,为了找到分类超平面,需要定义一个损失函数并通过将损失函数最小化来求w和b。考虑到分类错误的点会有如下性质
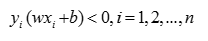
(3)
因此,损失函数定义如下:
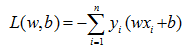
(4)
感知机的学习策略就是选取使得损失函数(4)最小的w和b。
感知机学习问题转化为求解w和b关于损失函数(4)的最优化问题,如果只考虑最优化问题的话,有很多方法可以求解,比如梯度下降法(Gradient Descent)、共轭梯度法(Conjugate Gradient)等。本文所选取的最优化方法是随机梯度下降法。
要使用随机梯度下降法,需要先求出L(w,b)关于w和b的梯度,结果如下:
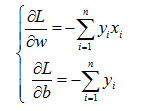
(5)
所谓的随机梯度下降法,就是在训练的时候随机选取一个误分类点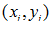 对w和b进行更新,更新方式如下:
对w和b进行更新,更新方式如下:
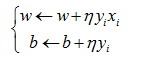
(6)
其中η>0是学习率,影响优化速率。
感知机学习算法是误分类样本驱动的,每一次更新权重和偏置都是由误分类样本决定。在实际操作中,首先随机选取一个分类超平面,即随机选取 ,然后用梯度下降法不断极小化目标函数式(4)。极小化的过程不是一次使得所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。下面以台湾大学林轩田老师《Machine Learning Foundation》的讲义中列举的分类案例说明感知机学习算法。具体实现过程如下:
,然后用梯度下降法不断极小化目标函数式(4)。极小化的过程不是一次使得所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。下面以台湾大学林轩田老师《Machine Learning Foundation》的讲义中列举的分类案例说明感知机学习算法。具体实现过程如下:
Step0.画出要分类的样本。
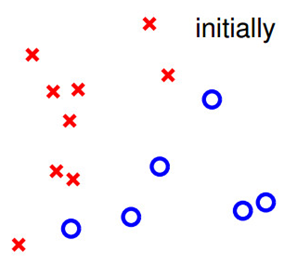
图8 分类样本
Step1.随机选取一个分类超平面,即随机选取 。
。
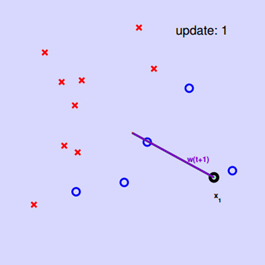
图9 初始化分类超平面
Step2.找一个错分类样本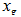 ,利用(6)对w和b进行更新。相当于给分类超平面的法向量w做了一次旋转。
,利用(6)对w和b进行更新。相当于给分类超平面的法向量w做了一次旋转。
图10 对w和b进行一次更新
Step3-end.以最新的w和b生成的分类超平面为界,将样本重新进行分类,和Step2一样再找一个个错分类样本 ,利用(6)对w和b进行更新。如此重复进行下去,不断地利用(6)修正w和b,直到所有的数据都被正确的分类。
,利用(6)对w和b进行更新。如此重复进行下去,不断地利用(6)修正w和b,直到所有的数据都被正确的分类。
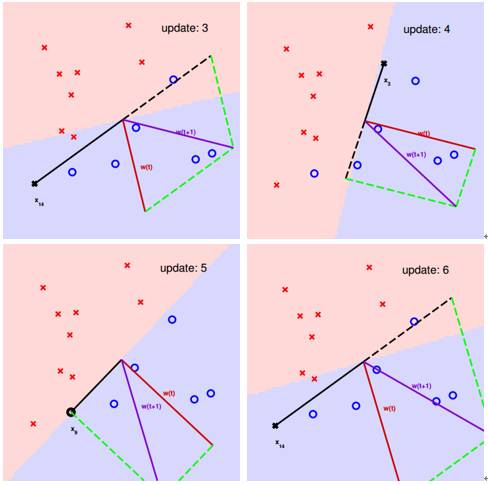
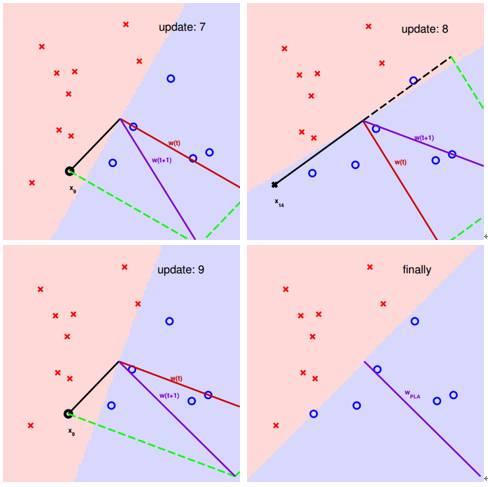
图12 感知机的学习过程
clear; close all; clc;
%% 定义变量
n = 50; % 正负样本的个数,总样本数为2n
r = 0.5; % 学习率
m = 2; % 样本的维数
i_max = 100; % 最大迭代次数
%% 生成样本(以二维为例)
pix = linspace(-pi,pi,n);
randx = 2*pix.*rand(1,n) - pi;
x1 = [cos(randx) + 2*rand(1,n); 3+sin(randx) + 2*rand(1,n)];
x2 = [3+cos(randx) + 2*rand(1,n); sin(randx) + 2*rand(1,n)];
x = [x1'; x2'];
y = [ones(n,1); -ones(n,1)];
hold on;
plot(x1(1,:),x1(2,:),'rx');
plot(x2(1,:),x2(2,:),'go');
%% 训练感知机
x = [ones(2*n,1) x]; % 增加一个常数偏置项 y = w0 + w1*x1 + w2*x2
w = zeros(1,m+1); % 初始化权值
flag = true; % 退出循环的标志,为true时退出循环
for i=1:i_max
for j=1:2*n
if sign(x(j,:)*w') ~= y(j)
flag = false;
w = w + r*y(j)*x(j,:);
% 以下代码为了展示感知机的训练过程,可以注释,停止请按 Ctrl+C
% begin
pause(0.3);
cla('reset');
axis([-1,6,-1,6]);
hold on
plot(x1(1,:),x1(2,:),'rx');
plot(x2(1,:),x2(2,:),'go');
x_test = linspace(0,5,20);
y_test = -w(2)/w(3).*x_test-w(1)/w(3);
plot(x_test,y_test,'m-.');
% end
end
end
if flag
break;
end
end
%% 画分割线
cla('reset');
hold on
axis([-1,6,-1,6]);
plot(x1(1,:),x1(2,:),'rx');
plot(x2(1,:),x2(2,:),'go');
x_test = linspace(0,5,20);
y_test = -w(2)/w(3).*x_test-w(1)/w(3);
plot(x_test,y_test,'linewidth',2);
legend('标签为正的样本','标签为负的样本','分类超平面');
参考资料
[1]https://zh.wikipedia.org/wiki/%E6%84%9F%E7%9F%A5%E5%99%A8#cite_note-2
[2] http://slideplayer.org/slide/890210/
[3] https://en.wikipedia.org/wiki/Perceptron
[4] Hebb, Donald O. "The organization of behavior." (1949).
[5]http://www.csie.ntu.edu.tw/~htlin/course/ml13fall/doc/02_handout.pdf 林轩田
[6] 李航《统计学习方法》
作者其他文章推荐:
机器学习编年史










