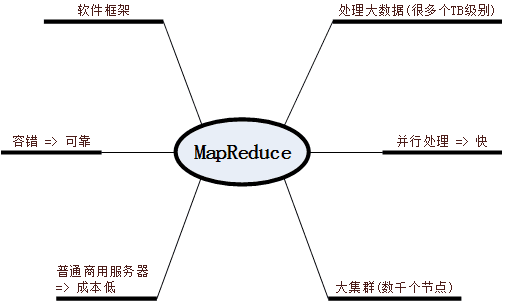
MapReduce特点
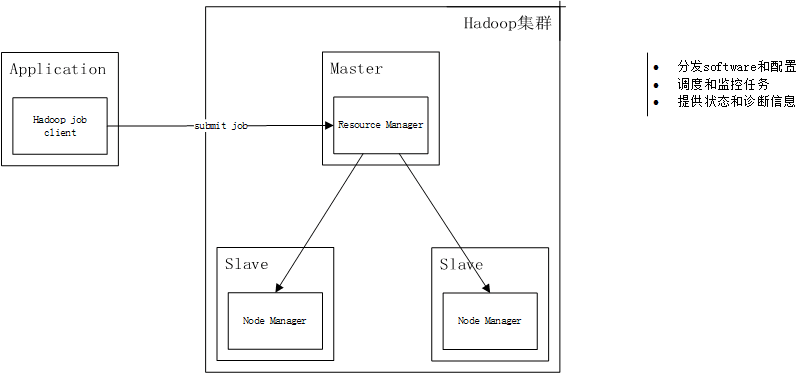
Hadoop工作架构
我们的应用程序通过Hadoop job client向Hadoop集群提交作业,Hadoop集群中Master节点负责调度各个Slave节点共同完成作业。
我认为有2个含义。1是在代码中使用的api,2是提交作业时使用的命令行工具。
比如在参考文章中的WordCount v1.0源代码,main方法负责构建配置并提交作业:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
这里大部分的类都来自包org.apache.hadoop.mapreduce。
而在运行这个程序的时候,先生成jar包,再执行下面的命令:
$ bin/hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output
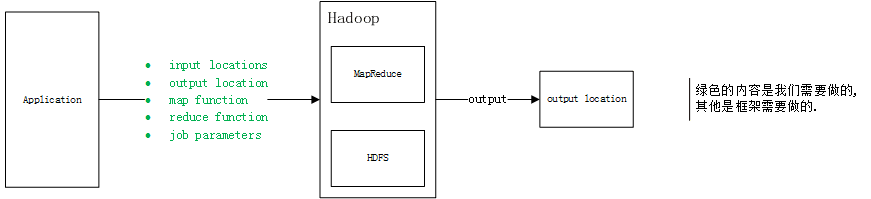
-
提供input locations和output location
这个是在运行jar包的命令行中提供的.
-
提供map和reduce的实现
这个对应源代码中的TokenizerMapper和IntSumReducer类。
-
提供job参数
具体对应源代码中的main方法.
包括上面的input/output locations, map和reduce的实现, 都需要以job参数的形式来提供, 才能实际被使用.
flat
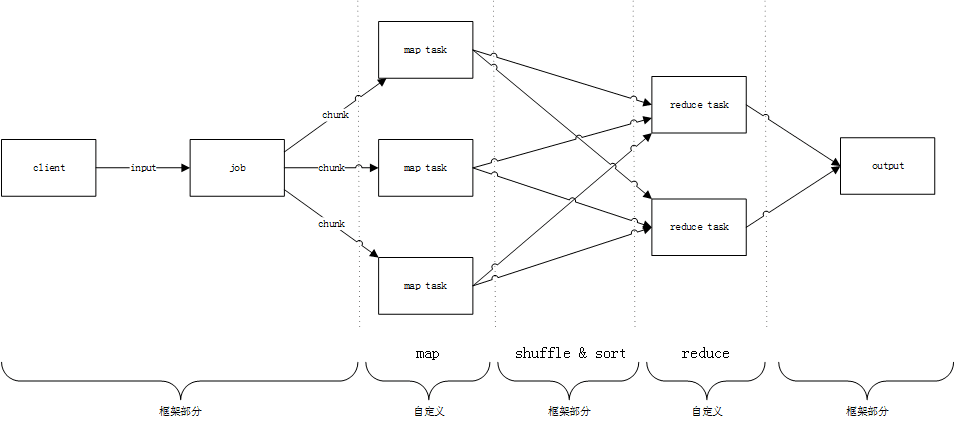
流水细节
client将软件和数据提交给job,job将输入拆分成一个个独立的数据块,每个数据块提交给不同的map task来处理.
结合HDFS的内容,我推论实际的过程是这样子的:
job查询NameNode元数据,得知输入数据文件对应的数据块及其所在的DataNode位置.
然后将所要执行的软件,和对应的数据块的元数据信息传给对应的DataNode.
每个DataNode所接收到的软件是一样的,但是数据块的元数据信息就只是自己相关的那一部分.
DataNode接收软件和数据块元数据之后,就找出对应的数据,作为输入来执行软件.
map对数据块中的数据进行初次处理,由于每个map task处理的是不同的数据块,所以这里是并行的. 处理完之后输出
形式的中间结果.
框架对中间结果进行处理,对每个中间结果进行排序,分区,发到具体的reduce task,然后再进行排序,分组.
最后reduce程序接收到的输入是
>的格式,这是按照key进行分组的结果.
reduce负责处理
>, 并输出最终的结果
到输出目录.
整个过程的数据类型变化情况
(input)
-> map ->
-> shuffle & sort ->
> -> reduce ->
(output)
map task的个数 = input文件的所有的块的个数.
reduce task的个数可以设置:Job.setNumReduceTasks();设置的大, 会增加框架开销, 但是可以增加负载均衡 并降低故障成本(每一个reduce负责的内容少了). 设置的小则会有相反的结论.
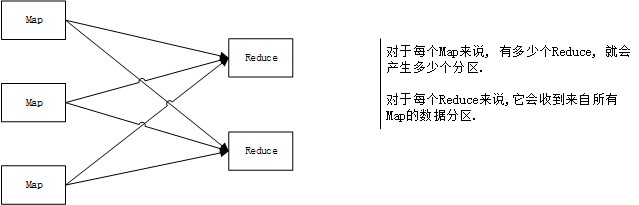
group
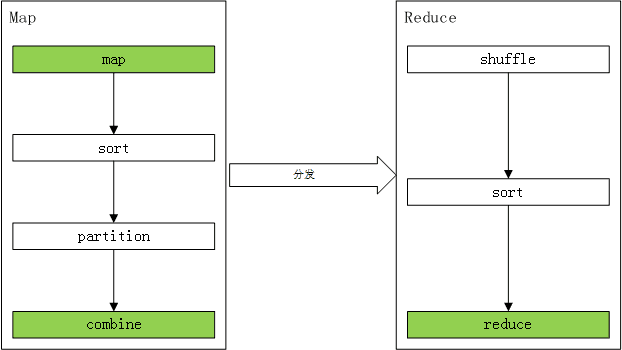
MapReduce的细节
浅绿色背景是我们要做的,其他是框架做的.
Map
-
map 是我们定义的map函数, 负责从我们指定的输入中解析出作为中间结果的
-
sort 负责对map的结果进行排序
-
partition 负责对上一步的结果数据进行分区.不同的分区会发到不同的Reduce task.
-
combine 负责本地聚合数据,这样可以减少发到Reduce task的数据量. 由我们自己定义聚合函数,这一步不是必须的.
Reduce
这里结合WordCount v1.0运行过程来对工作流程中每一步的工作有个形象的了解.
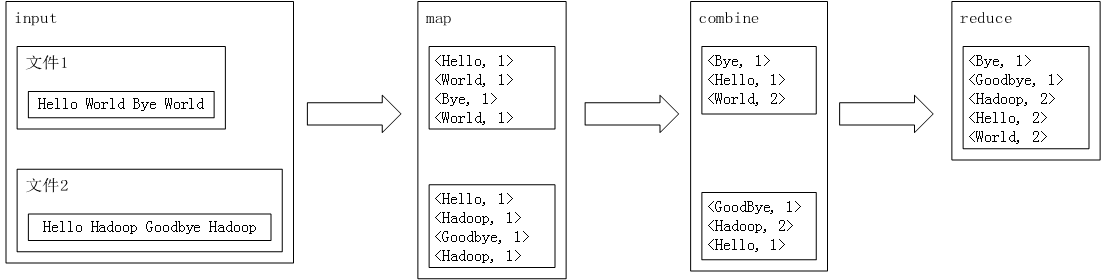
demo处理过程
WordCount负责统计输入文件中每个单词的出现次数.
input有2个文件, 每个文件占据一个数据块(每个文件都那么小), 所以会有2个map task分别处理一个数据块.
map的结果是以此记录哪个单词出现了一次, 并没有进行排序和聚合处理.
map到combine之间还有一段, 就是框架对数据进行了排序, combine接收到的已经是排序的结果.
combine负责在本地聚合, 它主要可以减少数据从map到reduce的传输量. 可以看到combine的输出已经是排好序且做了聚合处理.
reduce负责对接收到的来自2个map的数据块进行再分组, 排序, 聚合. 并最终输出结果.
End
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
排名前50的开源Web爬虫用于数据挖掘
33款可用来抓数据的开源爬虫软件工具
在中国我们如何收集数据?全球数据收集大教程
PPT:数据可视化,到底该用什么软件来展示数据?
干货|电信运营商数据价值跨行业运营的现状与思考
大数据分析的集中化之路 建设银行大数据应用实践PPT
【实战PPT】看工商银行如何利用大数据洞察客户心声?
六步,让你用Excel做出强大漂亮的数据地图
数据商业的崛起 解密中国大数据第一股——国双
双11剁手幕后的阿里“黑科技” OceanBase/金融云架构/ODPS/dataV
金融行业大数据用户画像实践
“
讲述大数据在金融、电信、工业、商业、电子商务、网络游戏、移动互联网等多个领域的应用,以中立、客观、专业、可信赖的态度,多层次、多维度地影响着最广泛的大数据人群
搜索「36大数据」或输入36dsj.com查看更多内容。
投稿/商务/合作:[email protected]





