遥想盖子当年,MS 红火了,谈笑间,640k 内存足矣。 - 程序君
现在已经不是从指缝中扣内存的时代了。bit 在主流的解释型语言中要么失了踪迹,要么被作为高(sha)级(bi)功能被雪藏起来,就像 .net 的 managed code 一样,被压抑得像个旷妇。 HTTP 这样的 string-based protocol 进一步助长了这种气焰,互联网世界原本精心构建的那一个个端庄优雅的透着书香的数据结构,让渡给了粗陋的 JSON。
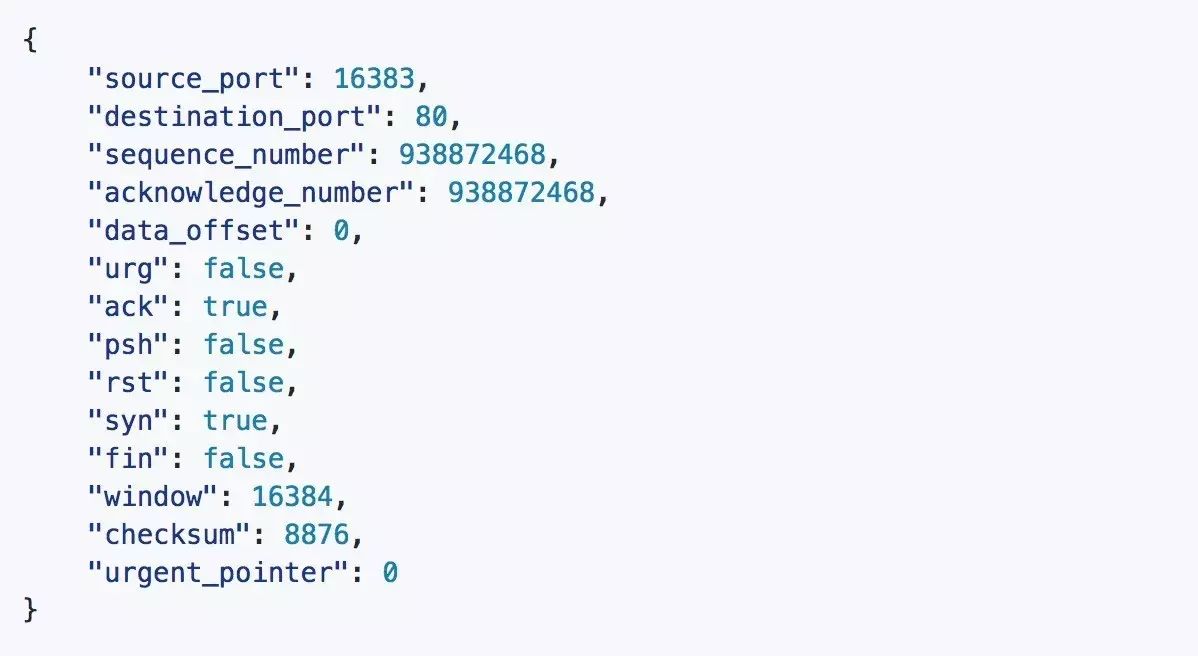
昨天文章中的 slides,在如何 improve memory 那里,我放了一张 RFC793 TCP header 的截图。有个细心的读者发现了,于是我们有了如下的对话(吐槽):
第 33 张幻灯片标题是 memory,图怎么放得是 TCP 的协议头:)
眼尖心细!这张 slides 我懒得写文字了,调侃了一下现在日下的世风,web dev 动辄 json,对数据的把控退化到 integer / string / array / map,不再有 enum 的概念,不再有 bit,该用 atom/symbol 统统 string..
我觉得很多人会不以为然。现在不是论 M,更不是论 K 的时代了。每 Gb 内存,也就是 711 一份好炖的价格,咱不差钱,32G 不够,上 128G,还不够,只要系统支持,咱可以照着 Tb 往上撸,多大个事!为了抠点内存,浪费我司宝贵的程序员的时间,那可是一秒钟几十万上下的!
好吧,那我们聊聊这个事。
先说好理解的。一个 256 byte 就可以搞定的数据结构,如果任其膨胀到 2k,会发生什么?
-
CPU 的顺序读取时间膨胀了 8x
-
网络的发送时间增长了 8x
好吧,这些都是小时间,ns / us 量级的东西,不足为虑!
我们接着看:
公允期间,咱们都不做 gzip(你要非跟我较真这个,那么咱就把前提变成 1k 和 8k),由于 2k > 标准的 MTU(1514),这个数据一个报文发送不了,于是乎,发送端需要分片,接收端需要重组。分片是万恶之源,我们昨天的文章中提到,美国到欧洲一个 roundtrip 就是 150ms,一个包拆成两个,那就要两个 roundtrip 后才能收到完整的数据结构,进行后续处理,这就起码 300ms 起步。IP 是无序的,分片抵达接收端时,可能会后队变前队,第二个分片先到达,这就涉及 reassemble,reassemble 还好,多了一个包,丢包的概率就大大升高了。而丢包,众所周知,是网络性能的大敌。
更大的数据带来更多的读写时间,更多的网络传输时间,可能会引发分片,进而引发重组,还有更高的丢包率,以上种种,形成了乘数效应,耿直的程序员汉子管这叫:cluster f**k。
所以不要小看了多用了些本不该用的内存 —— 它就跟「多收了三五斗米」一样,暗藏的蝴蝶效应也许会搅得你鸡犬不宁。
好吧,其实这也不是多大点事,原本 150ms 完成的事情,现在即便最坏的情况,500ms 完成,也没啥大不了哈。
好,咱么再换个角度,谈谈 capacity。
假设你一台服务器配 16G 内存,其中有 12G 可以完全归你的 app 所有。在 256 byte 的数据结构下,暂且不考虑内存的其他损耗(mm frag,control block 的消耗等等),你可以支撑 48M 的 capacity。2k 大小的数据结构,则缩减到 6M。还是 8 倍的差距。假设你的系统要能支持到 40M 的这种结构的热数据,那么,对于前者,一主两备的 cluster,三台组个 full mesh 网路足矣;对于后者,你需要至少 3 x 7 台,可能稍稍得花些心思:full mesh 时同步的消耗会不会太大,要不要转而使用 gossip 组 cluster 啊。
如果你对数字没概念,那咱们换成钱 —— 16G 内存的 M4.xlarge,一小时两毛,一个月按 750 小时算,150刀,那么 3 台的成本是 450 刀,而 21 台是 3150 刀,换算成软妹币,duang 的一下,差出来一个 Jr. + 一个程序员鼓励师的费用啊。
而且,管理更多的机器,花的时间虽然不是线性,但总归多些,你这边士气 -1,人家那里军队 +1,还添了个大天使,全员士气 +1。一来一回,效率差出了不少。
当然你可以说咱初始资金多,不差钱。好,那继续撸。
我们再看程序设计的严谨性。为方便阅读,我们把上篇文章的 TCP header 再粘回来:

我们可以看到,不带 option 的 TCP header,是 20 个字节,5 个 word。
假设我们用 JSON 表述 TCP header: