
如今,越来越多的国际友人加入小红书平台,这股汹涌而来的流量也伴随着“欲戴王冠,必承其重”的压力。小红书备受赞誉的内容推荐算法,正是它能够成功承接这股流量洪流的核心要素之一。本文将通过深入解读小红书官方团队发表的两篇关于推荐算法的论文,带您一窥小红书内容推荐机制的奥秘所在。
最近,外国友人们如潮水般涌入“Xiaohongshu”,网友们纷纷惊叹,仿佛一夜之间,平台就与国际潮流无缝对接。
这场被誉为“美洲大迁徙”的互联网奇观,很大程度上得益于小红书自身卓越的内容推荐算法技术。国外网友们对“Xiaohongshu”的推荐算法同样不吝赞美之词。
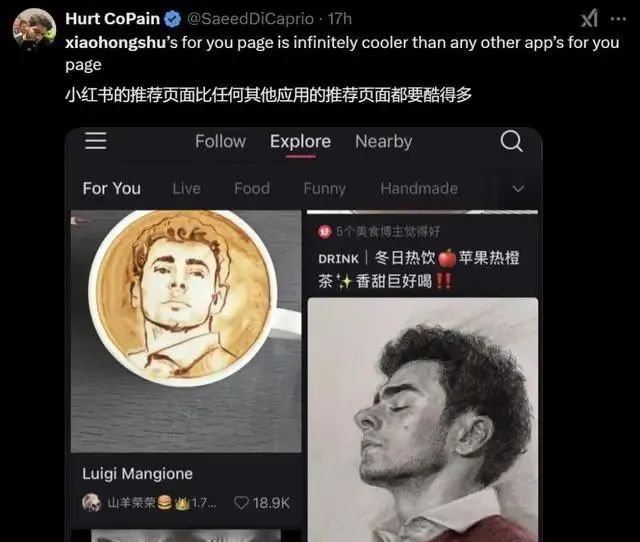
01 小红书如何「投你所好」
接下来,让我们深入探讨小红书的推荐算法是如何持续精准地“投你所好”。
一般而言,为了生成符合用户喜好的推荐内容列表,一个经典的推荐系统通常由以下几个关键环节构成:
首先,从庞大的内容数据库中检索出潜在的候选内容;
接着,利用排序模块对每个候选内容的质量进行评估,即预测特定内容能为用户带来的满意度或价值;
最后,经过排序的高质量内容会被送至策略模块,进行进一步的筛选和重新排序,以精心构建出最终的个性化推荐列表。

推荐系统的典型架构
截至目前,我们能够检索到的小红书官方公开发表的关于推荐算法的技术论文共有两篇。接下来,就让我们一同揭开小红书内容推荐机制的“神秘面纱”。
02 发现你的兴趣:NoteLLM
为用户提供与其兴趣高度契合的笔记推荐是一项至关重要的任务。NoteLLM作为一种创新的统一框架,专为解决内容到内容(I2I)的笔记推荐问题而设计,旨在为用户提供更加精确和个性化的笔记推荐服务。
研究团队在小红书平台上开展了一项为期一周的在线I2I推荐实验,以验证NoteLLM的有效性。
与先前采用SentenceBERT的方法相比,NoteLLM在点击率上实现了16.20%的显著提升,同时召回性能的优化也促使评论数增加了1.10%,平均每周的发布者数量更是增长了0.41%。
这些成果充分表明,将大型语言模型(LLM)应用于I2I笔记推荐任务中,能够大幅提升推荐系统的性能和用户的体验。此外,新发布的笔记在一天内获得的评论数也显著增加了3.58%,这进一步证明了LLM的泛化能力对于冷启动笔记具有积极的推动作用。
目前,NoteLLM已经被成功部署在小红书的I2I笔记推荐任务中。
具体而言,该框架通过“笔记压缩提示词”技术,将笔记内容精炼成独特的单一标记(token),并借助对比学习方法,进一步深入学习潜在相关笔记之间的嵌入关系。此外,NoteLLM还具备对笔记进行总结的能力,能够根据指令自动生成优化的标签或类别。
经过大量实际场景的验证,NoteLLM在小红书的推荐系统中展现出了卓越的效果,为用户带来了更加精准和个性化的笔记推荐体验。

论文链接:https://arxiv.org/pdf/2403.01744
基于BERT模型的在线I2I笔记推荐方法存在一定的局限性,因为它们仅仅将标签/类别视为笔记内容的普通组成部分,而没有深入挖掘其潜在的巨大价值。实际上,标签/类别凝聚了笔记的核心要点,对于判断笔记之间内容的相关性具有至关重要的作用。
生成标签/类别与生成笔记嵌入在某种程度上具有相似性,两者都能够将笔记的关键信息提炼并浓缩为有限的内容表示。因此,通过学习如何生成高质量的标签/类别,我们可以进一步提升笔记嵌入的质量,从而增强推荐系统的准确性和性能。
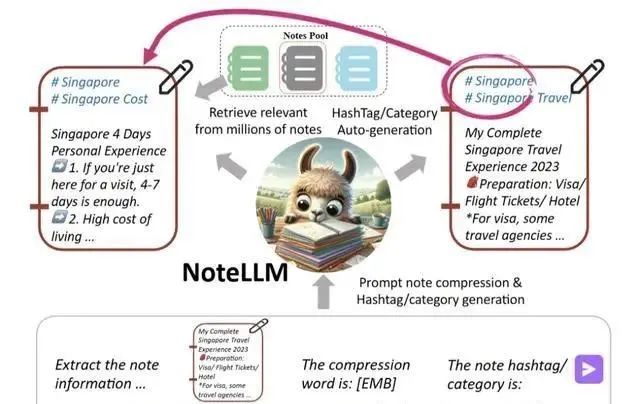
NoteLLM框架由三大核心组件构成:笔记压缩提示构建模块、生成对比学习(GCL)模块以及协作监督微调(CSFT)模块。
研究者精心设计了统一的笔记压缩提示,其目的在于将复杂的笔记内容高效地压缩成一个独特的单一token,以此作为强有力的工具来辅助I2I推荐任务和生成任务的执行。
在这个精心压缩后的特殊token的基础上,研究者引入了生成对比学习(GCL)模块,以深入挖掘其中蕴含的协作知识。随后,借助协作监督微调(CSFT)模块,研究者巧妙地运用这些协作知识来生成更加精确和有意义的标签与类别。
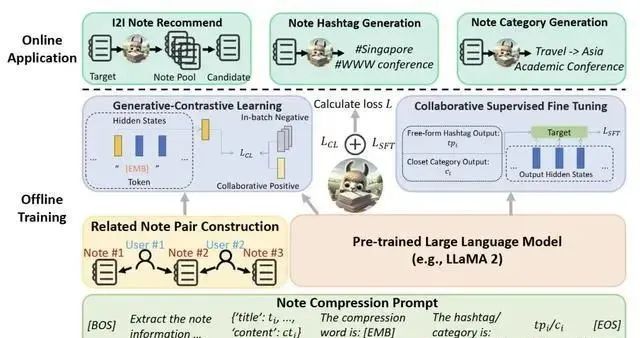
构建笔记压缩提示
研究者采用了以下精心设计的提示模板,成功实现了对笔记内容的通用压缩以及标签和类别的有效生成:
在这个模板中,[BOS]、[EMB] 和 [EOS] 扮演着特殊标记(token)的角色。而(指令)、(输入笔记)、(输出引导)以及(输出结果)则作为占位符存在,它们会在后续步骤中被具体的内容所替换。
关于类别生成的具体内容定义如下:

标签生成的模板如下:

完成提示构建之后,需对其进行标记化处理,并将其输入到大型语言模型(LLM)中。LLM将会提炼出协作信号与关键语义信息,并将这些信息浓缩到压缩词中,根据笔记的核心思想来生成相应的标签或类别。
生成对比学习(GCL)
为了进一步增强LLM捕获更强协作信号的能力,研究者提出了生成式对比学习(GCL)方法。与传统的从特定答案或奖励模型中学习的方式不同,GCL采用了对比学习的策略,从整体的视角来评估笔记之间关系的紧密程度。
为了将协作信号有效地融入LLM中,研究者采用了基于用户行为的共现机制来构建相关的笔记对。这一机制基于一个合理的假设:如果两篇笔记经常被用户一起阅读,那么它们之间很可能存在某种关联性。
在成功构建相关笔记对之后,研究者开始训练NoteLLM模型,使其能够基于文本语义和协作信号来准确地判断笔记之间的相关性。
GCL的损失函数计算具体方式如下:
其中,表示GCL的损失,为可学习的温度参数,(,)=⊤/(∥∥*∥∥) 表示向量和的相似度。
协作监督微调(CSFT)
生成标签/类别与生成笔记嵌入在功能上具有共通性,即都是对笔记核心内容的提炼与概括。前者侧重于从文本生成的维度捕捉关键信息,后者则侧重于从协作关系的角度将笔记内容压缩为表征性强的虚拟词,以便于在I2I推荐任务中发挥作用。
NoteLLM框架创新性地将生成对比学习(GCL)与协作监督微调(CSFT)两大任务融合于同一建模框架内,旨在从根本上提升嵌入表示的质量。研究者通过将这两个任务整合至一个统一的提示结构中,为它们提供互补的信息资源,并有效简化了训练流程。
03实现多样化推荐:SSD
论文链接:https://arxiv.org/pdf/2107.05204
该论文主要提出了一种名为滑动频谱分解(SSD)的方法,旨在解决小红书平台上面临的「多样化信息流推荐」挑战。同时,文中还提出了一种名为CB2CF的计算嵌入向量的策略,以有效应对实际推荐场景中普遍存在的长尾效应问题。
滑动频谱分解(SSD)
在推荐系统中,通常会为用户呈现一个冗长的内容序列,而用户的当前浏览窗口往往只能覆盖这个序列的某个片段。为了获取推荐内容序列中的更多内容,用户需要不断地滑动其当前浏览窗口。
如下图所示,用户阅览窗口的处理流程细致划分如下:首先,一个预设固定大小ω的窗口会在整个原始内容序列上进行滑动遍历。紧接着,将这些内容窗口以内容矩阵的形式有序地堆叠组合在一起。最终,通过映射机制,将每个内容项转换为其对应的d维内容嵌入,从而构建出一个轨迹张量。
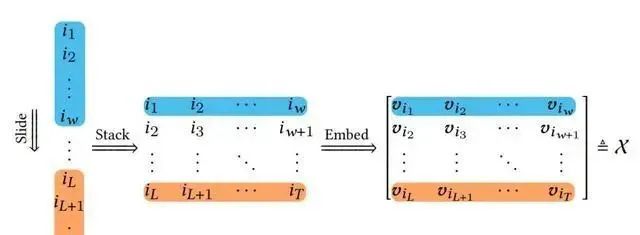
在推荐系统的应用场景中,作者巧妙地将轨迹矩阵的概念拓展至三阶情形,其中d维内容嵌入被视为多元观测数据。为了深入分析这些数据,作者引入了单变量时间序列的奇异谱分析(SSA)方法,并据此对轨迹矩阵进行了奇异值分解。
其中,该轨迹张量的体积深刻反映了基于整个内容序列及滑动窗口所展现的多样性特征。奇异矩阵可以被视作推荐内容呈现的一组正交方向基,而奇异值则量化了这些方向在用户感知多样性中所占据的权重。
作者进一步通过内容嵌入所张成的超平行体的体积来界定多样性,其逻辑在于,多样化的内容嵌入倾向于更加正交,从而能够占据更大的体积空间。








